Azure support for cloud-dyndns Python-script
Monday, April 1. 2019
StackExchange flair received
Monday, March 11. 2019
Whoa! I finally hit the long awaited 200 point mark in Stack Overflow. The good part about that is, Stack Exchange starts publishing a public badge they'll call "flair". They do this to make it possible for me to publicly boast about my prowess. To get some public boasting going on, my flair looks like this:

All of you Peeping Toms out there, I'll save you couple keystrokes of googling: My ![]() public user profile is at https://stackexchange.com/users/1684769/hqjatu
public user profile is at https://stackexchange.com/users/1684769/hqjatu
Blog software update
Saturday, February 23. 2019
Some of you may have noticed I've been busy doing everything else but blogging.
There were number of reasons:
- No shoes -phenomenon
- What I do for living (and past-time) is build/maintain/hack systems. Some of them running web applications such as this cloud Azure VM Nginx/PHP/PostgreSQL -thingie.
- Sometimes just starting a tedious task of fixing/updating/repairing a server instead of playing The Division or Far Cry doesn't do the trick for me. I choose to play for entertainment and not update the server.

- Ref.: The Cobbler's children have no shoes
- PHP 5.6 support EOL
- See https://secure.php.net/supported-versions.php for details
- This blog has been running on 5.6 for years and to get that updated, I had to re-asses configurations to get 7.2 running. Not an easy task, but had to be done to go forward.
- Serendipity 2.1 upgrade
- Most of you have never realized, I wouldn't touch Wordpress with a 9 foot pole. This blog runs on Serendipity (aka s9y).
- Previous version of S9y 2.0 wouldn't run correctly with PHP 7.2, so I had to go for this upgrade too.
- See https://docs.s9y.org/ for details.
- Mobile template
- This blog gets reasonable Page Rank from Google, but it really suffers from not being very good when displayed on a mobile device.
- See #1 above. This is what I do for living. It should be not a complicated task to strap Bootstrap boot on top of the theme.
- See http://blog.s9y.org/index.php?user_template=additional_themes/brownpaper
What hasn't changed: I'm still in Microsoft Azure, running CentOS 7.
The mobile version of Brown Paper is still under work in my lab VM, but it will be out soon. I promise!
Formula 1 messing with Apps
Wednesday, October 24. 2018
As a Formula 1 fan, while watching a F1 Grad Prix, I've been using real-time information feeds on https://www.formula1.com/en/f1-live.html pretty much since it was released. If memory serves me correct, that must have been around season 2008. After getting my first iPad (yes, the 1st gen one) in 2011, I went for the beautiful paid App by Soft Pauer flooding me with all kinds of information during the race. I assumed, that I had all the same information available as the TV-commentators.
In 2014 something happened. The app was same, but the publisher changed into Formula One Digital Media Limited, making it not a 3rd party software, but an official F1-product. At the same time, the free timing on the website was removed, causing a lot of commotion, as an example Why did FIA dumb-down the Live Timing on F1.com? Also, in a review (Official F1 Live Timing App 2014 reviewed), the paid app was considered very pricey and not worth the value. Years 2015 onwards, made it evident, that in loving care of the Formula One Group, they improved the app adding content, more content, improving the value and finally a TV to it. It was possible to actually watch the race via the app. All this ultimately resulted in a must-have app for every F1 fan.
This year, for Singapore weekend, they did something immensly stupid.
They changed this:
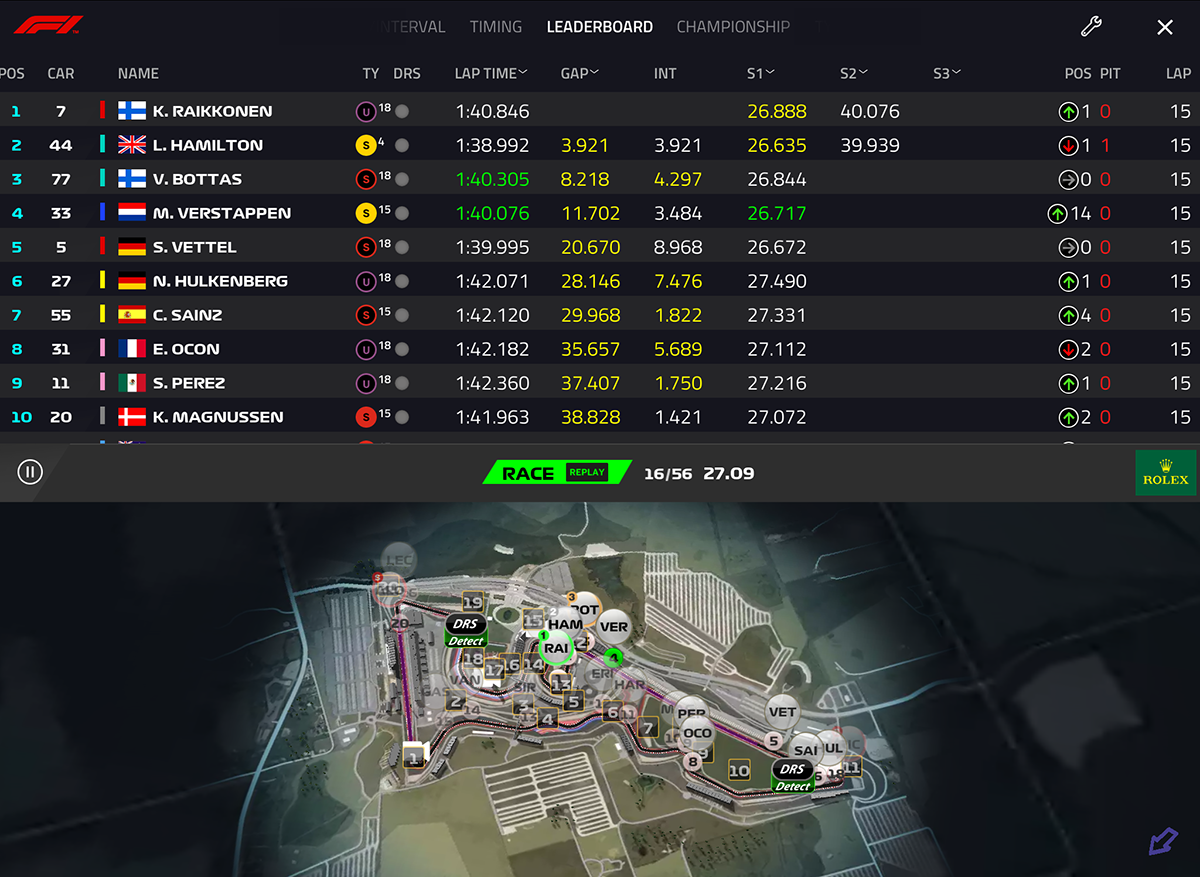
into this:

ARGH!
Did they really think nobody would notice? To put it shortly, their change was a drastical one. I ditched the new timing app after 5 minutes of failing attempts to get anything useful out of it. The people doing the design for that piece of sofware completely dropped the ball. Thy simply whipped up "something". Probably in their bright minds it was the same thing than before, it kinda looked the same, right. Obviously, they had zero idea what any form of motor racing is about. What information would be useful to anybody specatating a motor racing event was completely out of their grasp. They just published this change to App Store and went on happily.
Guess what will happen, when you take an expensive piece of yearly subscribed software and remove all the value from it. You will, but the authors of the software didn't.
IT MAKES PEOPLE MAD!
It didn't take too long (next race, to be exact), when they silently dropped the timing feature and released the old app as a spin-off titled F1 Live Timing. Obviously informing any paying customers of such a thing wasn't very high on their list of priorities. In their official statement they went for the official mumbo-jumbo: "The launch of our new F1 app didn't quite live up to your expectations, and live timing didn't deliver the great mobile F1 experience you previously enjoyed." By googling, I found tons of articles like Formula 1 makes old live timing app available again after problems.
As a friendly person, I'll offer my list of things to remember for FOM personnel in charge of those apps:
- Do not annoy paying customers. They won't pay much longer.
- If you do annoy paying customers, make sure they won't be really annoyed. They will for sure stop paying.
- If you make your paying customers mad, have the courtesy of apologizing about that.
- Also, make sure all of your paying customers know about new relevant apps, which are meant to fix your own failures.
- Improve on software design. Hire somebody who actually follows the sport to the design and testing teams.
Thank you.
Real-word Squid HTTP proxy hierarchy setup - Expat guide
Tuesday, October 17. 2017
Half a year back I posted about moving to Sweden. I built network and router setup to gain access to The Net. One of the obvious use cases for a connection is to playback various streaming media services. I have touced the subject of configuring Squid for YLE Areena earlier.
As an ex-patriate, I like to see and hear some of the media services I've used to consuming in Finland. Those stupid distribution agreements make that unnecessarily difficult.
Spec
With my current setup, I need to access services:
- directly: Using no fancy routing, direct out of my Swedish IP-address. It's faster and less error-prone. This is majority of my HTTP-traffic.
- from Finland: To access geo-IP blocked services from a Finnish IP. I have my own server there and I'm running Squid on it.
- from my VPN-provider: To access selected geo-IP blocked services from a country of my choosing
Of course I can go to my browser settings and manually change settings to achieve any of those three, but what if I want to access all of them simultaneously? To get that, I started browsing Squid configuration directive reference. Unfortunately that is what it says, a reference manual. Some understanding about the subject would be needed for a reference manual to be useful.
Getting the facts
Luckily I have access to Safari Books Online. From that I found an on-line book called Squid: The Definitive Guide:

That has an useful chapter in it about configuring a Squid to talk to other Squids forming a hierarchy:

© for above excerpt: O'Reilly Media
Now I familiarized myself with Squid configuration directives like: cache_peer, cache_peer_access and always_direct.
... but. Having the book, reading it, reading the man-pages and lot of googling around left me puzzled. In the wild-wild-net there is lot of stumble/fall-situations and most people simply won't get the thing working and those who did, didn't configure their setup like I wanted to use it.
Darn! Yet again: if you want to get something done, you must figure it out by yourself. (again!)
Desired state
This is a digaram what I wanted to have:
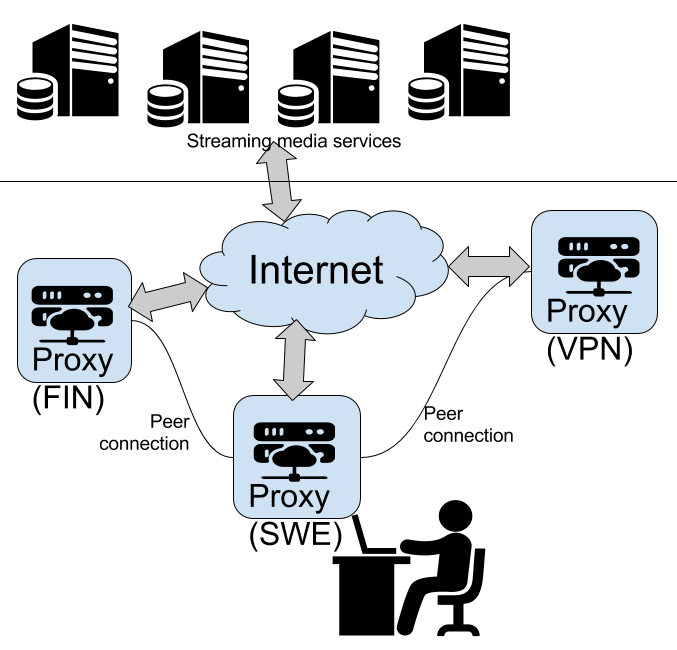
Implementation
But how to get there? I kept stumbing with always_direct allow never and never_direct allow always -permutations while trying to declare some kind of ACLs or groupings which URLs should be processed by which proxy.
After tons and tons of failure & retry & fail again -loops, I got it right! This is my home (Sweden) proxy config targeting the two other Squids to break out of geo-IP -jail:
# 1) Define cache hierarchy
# Declare peers to whom redirect traffic to.
cache_peer proxy-us.vpnsecure.me parent 8080 0 no-query no-digest name=vpnsecure login=-me-here!-:-my-password-here!-
cache_peer my.own.server parent 3128 0 no-query no-digest name=mybox default
# 2) Define media URLs
# These URLs will be redirected to one of the peers.
acl media_usanetwork dstdomain www.usanetwork.com www.ipaddress.com
acl media_netflix dstdomain .netflix.com
acl media_yle dstdomain .yle.fi areenapmdfin-a.akamaihd.net yletv-lh.akamaihd.net .kaltura.com www.ip-adress.com
acl media_ruutu dstdomain ruutu.fi geoblock.nmxbapi.fi
acl media_katsomo dstdomain .katsomo.fi
acl media_cmore dstdomain cmore.fi
# 3) Pair media URLs and their destination peers.
# Everything not mentioned here goes directly out of this Squid.
cache_peer_access vpnsecure allow media_usanetwork
cache_peer_access vpnsecure allow media_netflix
cache_peer_access mybox allow media_yle
cache_peer_access mybox allow media_ruutu
cache_peer_access mybox allow media_katsomo
cache_peer_access mybox allow media_cmore
never_direct allow media_usanetwork
never_direct allow media_yle
never_direct allow media_ruutu
never_direct allow media_katsomo
never_direct allow media_cmore
never_direct allow media_netflix
# 4) end. Done!
request_header_access X-Forwarded-For deny all
Simple, isn't it!
Nope. Not really.
Notes / Explanation
Noteworthy issues from above config:
- On my web browser, I configure it to use the home proxy for all traffic. That simply makes my life easy. All traffic goes trough there and my local Squid makes the decisions what and where to go next, or not.
- In above configuration:
- I declare two peers (
cache_peer), how and where to access them. - I declare ACLs by URL's destination domain (
acl dstdomain). It's fast and easy! - I associate ACLs with peers (
cache_peer_access) to get HTTP-routing - I make sure, that any traffic destined to be routed, does not exit directly from Sweden (
never_direct allow). Slipping with that will be disastrous for geo-IP checks! - I don't declare my traffic to be originating from a HTTP-proxy (
request_header_access X-Forwarded-For deny). Some media services follow up to the real client-address and do their geo-IP checks on that.
- I declare two peers (
- The VPN-service, I'm using is VPNSecure or VPN.S as they like to be called nowadays. Two reasons:
- No mandatory softare installation needed. You can just configure your browser to use their proxy with proxy authentication. And if you are using Google Chrome as your browser, there is an VPN.S extension for super easy configuration!
- Price. It's very competitive. You don't have to pay the list prices. Look around and you can get ridiculous discounts on their announces list prices.
- My Finnish proxy is just out-of-the-box Squid with ACLs allowing my primary proxy to access it via Internet. Other than default settings, has
request_header_access X-Forwarded-For denyin it. - For testing my setup, I'm using following display-your-IP-address -services:
- Finnish services C More and MTV Katsomo are pretty much the same thing, share user accounts and in future are merging more and more. To have C More working, both ACLs need to declared.
- YLE Areena is using Akamai CDN extensively and they tend to change.
- Ruutu is using external service for geo-IP for added accuracy. They compare the results and assume the worst! Redirecting both is necessary to keep their checks happy.
- Netflix is using their own state-of-the-art CDN, which is very easy to configure. Regardless what Mr. Hastings publicly, they only care that the monthly recurring credit card payment passes. Using different countries for Netflix produces surprising results for availability of content.
Finally
This is working nicely!
Now moving from one media service to another is seamless and they can run simultaneously. Not that I typically would be watching two or more at the same time, but ... if I wanted to, I could!
EPIC 5 Fedora 26 build
Sunday, September 3. 2017
Open source software - root of all evil?
Saturday, July 22. 2017
In Harward Business Review, a buffoon called Joshua Gans wrote an article Could Open-Source Code Make Our Y2K Fears Finally Come True?, which I recommend everybody to read.
In case of TL;DR, I'll post a totally inappropriate summary of the article here, with words and sentences taken out-of-context to make my point. So here goes:
Recent workshop organized by the Ford and Sloan Foundations, showed that Y2K-type concerns are far from over.
The base of all this is open-source code.
The Network Time Protocol, or NTP is invented by David Mills. It’s not stable. The entire NTP relies on the sole effort of a 61-year-old Harlan Stenn who is working on a shoestring budget and has pretty much volunteered his own time for the last 30 years.
Also Azer Koçulu "broke" entire Internet (yes, all of it, the entire thing!) by removing npm-package left-pad from Github.
Yup. Sounds pretty bad. Based on that, a second Y2K is going to hit us any time soon! Also, I think that because given the above proof, all software should be as closed source as possible!  NOOOOOOT!
NOOOOOOT!
Questions
Now, I'm asking you, yes you!, the reader of this blog post, to think this a bit.
To help your thinking, I'm posting some open questions which you must try to come out with some kind of answer:
- Only open-source software has flaws. True or false?
- Is it possible for any flaw/flaws in open-source software to be repaired/fixed/mended by anybody else than the original author?
- If using any piece of software to fulfill a specific task, is it possible to switch it for any suitable alternative piece of software performing similar or same task?
- Is it mandatory for all open-source software authors to be acknowledged in an appropriate Wikipedia-page to keep jealous pundits from ridiculing them in an article missing most of the facts?
- Must all open-source projects have a huge monetary budget?
- Is it mandatory for any self-respecting open-source project to fulfill any incoming user requests immediately?
- ... even if there are no known bugs and all the necessary functionality has existed in the project for past 30 years and all the new features are mostly nice-to-have?
- Does using any open-source software open your entire ICT-infrastucture to a risk of catastrophic cascading failure when an angry author chooses to remove all his work at that point from the known universe?
- Y2K was the most horrific event in the entire history of computer software. True or false?
- Is Mr. Joshua Glans an idiot, or is he just faking it?
(the answers are on the other side of this paper)
Moment - Tracking your mobile phone usage
Saturday, July 15. 2017
How I mostly use my mobile phone is like a mobile pocket computer. When I get back home I mostly just hang it to a wall:

However, that's not how majority of the people do it. They spend 24/7 with the phone talking, messaging or just watching TV from it. In Tunnelbana everybody else except me is like this:

In today's world bullshit is just bullshit and hard facts are hard facts (which can be alleged to be fake news). So, I installed an app called Moment. See https://inthemoment.io/ for details about the app. The idea is, that it tracks how much I use my phone and then I can view my screen time.
Yesterday Moment gave me a notification to inform, that it had something to tell me:
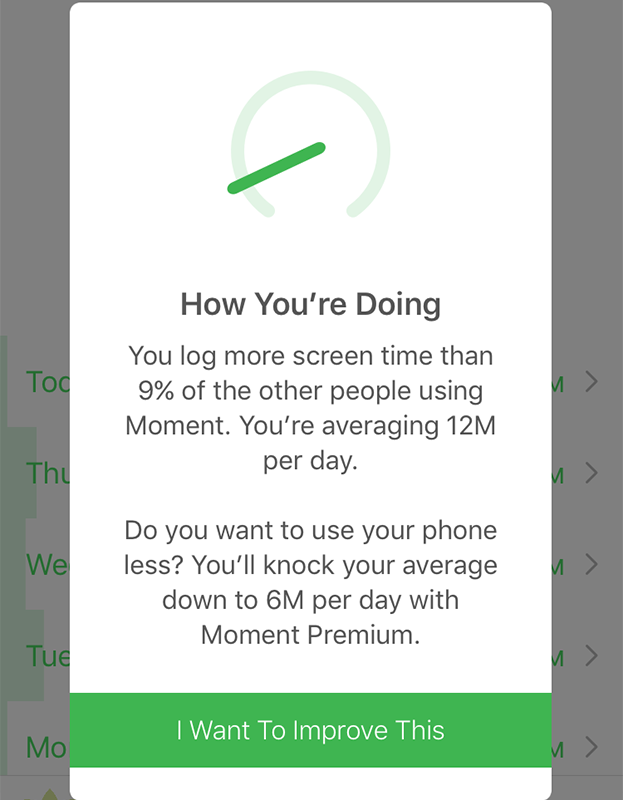
The text reads:
You log more screen time than 9% of the other people using Moment. You're averaging 12M per day.
... right. If my usage is at lower 9% of entire user population and if my average screen time is 12 minutes per day, that's not much! Looks like the app is designed only with heavy-duty phone users in mind.
For the record, my stats as seen by Moment are:
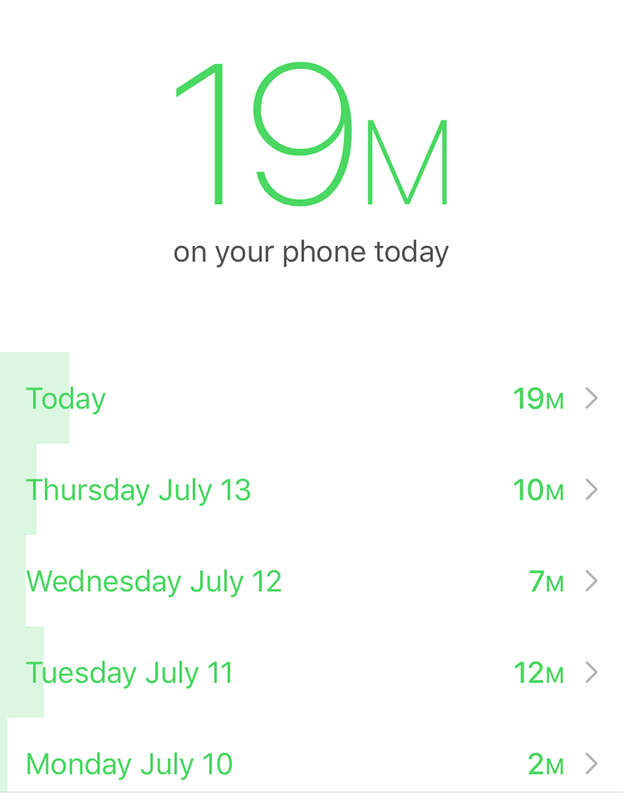
Not that bad. But then again, isn't that what every addict says?
Mirado Tech Talks - HTTP/2, the good, the bad and what's next
Tuesday, May 9. 2017
Mirado Consulting was kind enough to host a meetup, with appropriate food & drinks. By that I don't mean the pencil company:

... but a software development consulting agency in Stockholm.
They summoned Mr. Curl, aka. Daniel Stenberg:

... there to talk about HTTP/2 and QUIC, major improvements on HTTP-protocol. His work with network protocols at Mozilla, as author of libcurl/curl and as member of IETF's HTTPbis work group gives a pretty good picture what's happening at the HTTP-scene today. His presentation was titled HTTP/2, the good, the bad and what's next. In that he covered shortcomings of HTTP/1.1, benefits and shortcomings of HTTP/2 and a very likely future of moving away from TCP-based transport protocol into UDP-based QUIC.
Two tidbits from his presentation:
- Current browser implementations use HTTP/2 only with HTTPS:
- "most client implementations (Firefox, Chrome, Safari, Opera, IE, Edge) have stated that they will only support HTTP/2 over TLS, which makes encryption de facto mandatory", Wikipedia
- "Most existing servers only speak HTTP/2 over TLS", Daniel's blog
- HTTP/2 performance is poor on flaky network
- at 2% packet loss HTTP/2 is at least twice as slow then HTTP/1.1, HTTP/2: What no one is telling you (slide 53) by Hooman Beheshti, VP Technology at Fastly
- at 2% packet loss HTTP/2 is at least twice as slow then HTTP/1.1, HTTP/2: What no one is telling you (slide 53) by Hooman Beheshti, VP Technology at Fastly
So, it looks like HTTP/2 isn't going to save us from performance bottlenecks of HTTP/1.1 after all. Hence, QUIC.
About CA certificate handling on a Linux system
Finally, as I've written number of posts about TLS/SSL/HTTPS and one of them was about curl's really clumsy way of handling own CA-certificates. Also, I've always hated the fact, that if I'm running Firefox and curl on a Linux and want to add my own CA-root cert there, I need to do that three times:
- OpenSSL for the everything else in system
- curl for libcurl -depending apps to have it
- Firefox
IMHO that's two times too many! On a macOS you do that only once to the keychain and even curl will use that (yes, I confirmed from the man himself).
The reason is Mozilla's policy. NSS, or Network Security Services, a library written by Mozilla is boasting their FIPS 140 Validation and NISCC testing success, which a plain PEM-file in OpenSSL won't provide. That's why they insist on using NSS as storage and making us regular users suffer the pain of having multiple sources of truth.
Finally
Thank you Mirado Consulting for hosting a great event and Daniel for a great presentation!
Fixing curl with Go Daddy Secure Certificate Authority G2 CA root
Tuesday, June 7. 2016
Curl is one weird piece of software. Every time I use it, I get chills. The reason for this is, that it almost works and when it doesn't there isn't a damn thing you can to to fix it. The entire design of that software is ... I'm lost for words here. I'm looking for words that describe: cumbersome, shitty, unorthodox, non-functional, and so on.
Since the lib-version is used by a number of libraries and other software as a means to provide HTTP-protocol implementation I do run into curl-issues often. Many times I didn't even know, that in the end I was using libcurl for access before one of these obscure errors pops. For this reason, my weapon-of-choice is wget, it uses OpenSSL's crypto and is fully compatible with pretty much everything else in a Linux-distro.
Anyway, this time I chose to research this to the bitter and. It took me about a month (calendar time) to resolve this. Of course I didn't spend all my time and energy into this, it just took a very long time to get this one done properly & right.
The problem
One day, I was just tinkering something and ran a command:
$ curl --verbose https://packetstormsecurity.net/
... and it pulled a curl on me. 
* About to connect() to packetstormsecurity.net port 443 (#0)
* Trying 198.84.60.198...
* Connected to packetstormsecurity.net (198.84.60.198) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
* Server certificate:
* subject: CN=packetstormsecurity.com,OU=Domain Control Validated
* start date: May 31 18:04:40 2015 GMT
* expire date: May 31 18:04:40 2016 GMT
* common name: packetstormsecurity.com
* issuer: CN=Go Daddy Secure Certificate Authority - G2,
OU=http://certs.godaddy.com/repository/,
O="GoDaddy.com, Inc.",L=Scottsdale,ST=Arizona,C=US
* NSS error -8179 (SEC_ERROR_UNKNOWN_ISSUER)
* Peer's Certificate issuer is not recognized.
* Closing connection 0
curl: (60) Peer's Certificate issuer is not recognized.
More details here: http://curl.haxx.se/docs/sslcerts.html
curl performs SSL certificate verification by default, using a "bundle"
of Certificate Authority (CA) public keys (CA certs). If the default
bundle file isn't adequate, you can specify an alternate file
using the --cacert option.
If this HTTPS server uses a certificate signed by a CA represented in
the bundle, the certificate verification probably failed due to a
problem with the certificate (it might be expired, or the name might
not match the domain name in the URL).
If you'd like to turn off curl's verification of the certificate, use
the -k (or --insecure) option.
I hate when that happens. Also I don't know who forgot to do what, but it just won't work and nobody in the entire Internet knows how to handle that.
Figuring out the details of the issue
This is the easy part:
* NSS error -8179 (SEC_ERROR_UNKNOWN_ISSUER)
* Peer's Certificate issuer is not recognized.
In human language that reads: The problem is with HTTPS. The certificate used by the remote site is issued by a Certificate Authority (CA), that we don't know of and because we don't know it we won't trust any certificates issued by it.
Further:
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
In human that reads: There were three (3) places I tried looking for the root-certificate:
- NSS is the Network Security Services -library created by Mozilla. Its database is located at: /etc/pki/nssdb
- OpenSSL is the library/toolkit used by pretty much rest of your Linux for HTTPS-encryption. It has the trusted root-certificates at: /etc/pki/tls/certs/ca-bundle.crt
- OpenSSL didn't use a directory (CApath) for certificates.
After doing all three of those, no suitable CA was found and curl had to disconnect from the server and inform user about this lack-of-trust -issue.
Possible solutions
Ignore the issue and force curl to continue
There is a suggestion:
turn off curl's verification of the certificate, use the -k (or --insecure) option
This goes right out the window, because I'd rather chew off my left arm than force a prefectly valid check to be ignored. I'd rather spend the time investigating the fix. But that's me. Most of you don't care. I do.
Add the missing certificate to ca-bundle.crt
Good idea, but ... That file is reserved for the operating system / distro by OpenSSL. Actually curl uses this file only to make its own life easier so that curl doesn't have to distribute a set of trusted CA certificates, it just piggy-backs with something OpenSSL has.
Since this approach is OpenSSL-specific there is a procedure for adding own CA root-certificates into your system. When a new CA-root needs to be installed the mechanism is not to copy the certificate into this big file. How to actually do it, we'll get into that later.
The obvious problem with this approach is, that next time your distro gets a new CA-bundle one of two things will happen: 1) your changes will be overwritten and lost, you'll have to add the CA-root again or 2) the new CA-bundle won't be installed, because somebody messed up a file which he/she shouldn't do. This is definitely not a good approach.
Implicitly specify the CA root-certificate file
Aa-ha! There is a command-line option for this purpose:
--cacert <CA certificate>
(SSL) Tells curl to use the specified certificate file to verify
the peer. The file may contain multiple CA certificates. The
certificate(s) must be in PEM format. Normally curl is built to
use a default file for this, so this option is typically used to
alter that default file.
That's the one I could use, if I'd like to do that every goddamn single time I curl for something. First I don't want to do that every time and second, that command-line option isn't available for me, as I was using a piece of software wrapped to use libcurl.
Add the missing CA root-certificate into NSS database to establish trust
This is the one I chose. This is also the one nobody gets solved.
If you can find precise information on the web how to fix this, please tell me. I've been browsing the net for partial and non-working solutions enough not to care for half-assed solutions which don't work at the end.
Getting the missing certificate
Whatever we do (except just ignore the problem), the missing root-certificate needs to be located. With a little bit of googling I found a page Repository, Here’s a collection of important certificate documentation (https://certs.godaddy.com/repository/) at GoDaddy's server. Sure, the initial impression was "whoa, that was easy!", but when I landed on the page, I realized that there were following root-certificates available for GoDaddy Certificate Chain - G2 to download:
- GoDaddy Class 2 Certification Authority Root Certificate - G2
- GoDaddy Secure Server Certificate (Intermediate Certificate) - G2
- Microsoft to GoDaddy G2 Cross Certificate
- GoDaddy G2 Code Signing Intermediate
- GoDaddy Secure Extended Validation Code Signing CA - G2
- GoDaddy Certificate Bundle for Microsoft Windows Driver Signing - G2
- GoDaddy Certificate Bundles - G2
- GoDaddy PKCS7 Certificate Intermediates Bundle (for Windows IIS) - G2
- GoDaddy Certificate Bundles - G2 With Cross to G1
- GoDaddy Certificate Bundles - G2 With Cross to G1, includes Root
Ok, which one will I need? Darn!
Luckily I know something about X.509 certificates and especially certificate extensions. There should be an AIA or Authority Information Access -section (see RFC 5280 section 5.2.7 for details) in the cert. At least most CAs provide that information to make people's life easier.
First download the cert with a one-liner:
$ echo | \
openssl s_client -connect packetstormsecurity.net:443 \
> /tmp/packetstormsecurity.net.cert
Btw. the one-liner will say dumb things like:
depth=0 OU = Domain Control Validated, CN = packetstormsecurity.com
verify error:num=20:unable to get local issuer certificate
verify return:1
depth=0 OU = Domain Control Validated, CN = packetstormsecurity.com
verify error:num=27:certificate not trusted
verify return:1
depth=0 OU = Domain Control Validated, CN = packetstormsecurity.com
verify error:num=21:unable to verify the first certificate
verify return:1
That's just vomit from the fact, that the certificate isn't trusted. The important thing is, that the one-liner will result a text-file with lot of other garbage, but also the server certificate PEM. Luckily OpenSSL will ignore all the garbage when doing command:
$ openssl x509 -noout -text -in /tmp/packetstormsecurity.net.cert
That one will output a lot of stuff. Most if which are irrelevent for this purpose. The relevant things are:
Certificate:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, ST=Arizona, L=Scottsdale, O=GoDaddy.com, Inc.,
OU=http://certs.godaddy.com/repository/,
CN=Go Daddy Secure Certificate Authority - G2
X509v3 extensions:
X509v3 Certificate Policies:
Policy: 2.16.840.1.114413.1.7.23.1
CPS: http://certificates.godaddy.com/repository/
Authority Information Access:
OCSP - URI:http://ocsp.godaddy.com/
CA Issuers -
URI:http://certificates.godaddy.com/repository/gdig2.crt
X509v3 Authority Key Identifier:
keyid:40:C2:BD:27:8E:CC:34:83:30:A2:33:D7:FB:6C:B3:F0:B4:2C:80:CE
Exactly what we needed! There is an AIA-block with a direct URL of http://certificates.godaddy.com/repository/gdig2.crt in it.
A download:
$ wget http://certificates.godaddy.com/repository/gdig2.crt \
-O "/etc/pki/tls/certs/Go Daddy Secure Certificate Authority - G2.pem"
... and verify that certificate's serial number:
$ openssl x509 -noout -text \
-in /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
... will reveal:
Certificate:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, ST=Arizona, L=Scottsdale, O=GoDaddy.com, Inc.,
CN=Go Daddy Root Certificate Authority - G2
Subject: C=US, ST=Arizona, L=Scottsdale, O=GoDaddy.com, Inc.,
OU=http://certs.godaddy.com/repository/,
CN=Go Daddy Secure Certificate Authority - G2
X509v3 extensions:
X509v3 Subject Key Identifier:
40:C2:BD:27:8E:CC:34:83:30:A2:33:D7:FB:6C:B3:F0:B4:2C:80:CE
X509v3 Authority Key Identifier:
keyid:3A:9A:85:07:10:67:28:B6:EF:F6:BD:05:41:6E:20:C1:94:DA:0F:DE
Oh yes x 2!! The CA certificate has the correct serial number. It issued the failing certificate. This proof of correct CA-chain. We found the correct file.
Establishing trust to the new CA root-certificate in OpenSSL
This is the easy part. This one I have done hundreds of times.
First get a hash of the certificate:
$ openssl x509 -hash -noout \
-in /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
For this particular certificate, the hash is 27eb7704. The next thing is to instruct OpenSSL that this newly downloaded certificate is trusted by our server. It can be done like this:
$ ln -s /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem \
/etc/pki/tls/certs/27eb7704.0
The idea is to symlink the downloaded file with a filename from the hash and suffix the file with a .0 (dot-zero).
Now we can verify, that our setup was done correctly (remember the "garbage" file we downloaded earlier):
$ openssl verify /tmp/packetstormsecurity.net.cert
The only valid output would be:
/tmp/packetstormsecurity.net.cert: OK
Anything else, and you fumbled it.
Additional step: Add all hashes of the certificate chain
Command line openssl-command is at level now, however that's not how applications access certificates. Now this is where the CLI-command and library functionality differ. My box has /usr/lib64/libssl.so.10 to do the work for an application.
Looking at the SSL_CTX_use_certificate documentation, it's evident that there are functions to add a known certificate bundle (/etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem in my box, symlinked via /etc/pki/tls/certs/ca-bundle.crt), or a single certificate file. Not a directory of certificates, what openssl-command does. An application has to iterate the directory and add every certificate individually. For example in Perl, HTTPS-connections are typically created via IO::Socket::SSL-library. It accempts two options: SSL_ca_path and SSL_ca_file.
As the option of modifying the ca-bundle.crt file was abandoned already, using option SSL_ca_file is out. It leaves us with SSL_ca_path, which requires every certificate hash to be symlinked to the appropriate certificate PEM-file. That's why the already done symlink won't do it completely, two additional ones are required to get IO::Socket::SSL working properly:
$ ln -s ca-bundle.crt cbf06781.0
$ ln -s ca-bundle.crt f081611a.0
Where those two hashes come from is bit complex, but here goes:
The intermediate CA certificate we downloaded, Go Daddy Secure Certificate Authority - G2, was issued by:
$ openssl x509 -noout -issuer_hash
-in Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
... a certificate which has hash of cbf06781, which is already packed into ca-bundle.crt. Here things go weird, the Go Daddy Root Certificate Authority - G2 having hash cbf06781 is self-signed. However, during web-access that exact same certificate (with same serial number and all) is issued by a certificate having hash of f081611a. In ca-bundle.crt there is one with subject Go Daddy Class 2 Certification Authority. So, we need to add both to keep applications happy. Looks like somebody at Go Daddy really dropped the ball. Why should there be two separate CA certificates? Insane.
Actually, for example OpenSuSE Linux distro does that automatically to all bundle-certificates. The system is so stupid, that symlinkin all certificates is the only working method.
Establishing trust to the new CA root-certificate in NSS
Ok, this is the impossible part.
By lot of googling, poking around, failing, reading docs, tracing Curl, etc. I found out that there is a tool called certutil - Utility to manipulate NSS certificate databases. It seems to belong to package nss-tools. There is a man-page and some documentation at Network Security Services. But what's happening and how should I proceed remains bit foggy.
There is a /etc/pki/nssdb/, which we found in the beginning of this. That directory contains the NSS database in form of bunch of files. I found out that cert8.db and key3.db are completely obsoleted and any access methods having certutil -d /etc/pki/nssdb/ are completely useless, because they access only those files. Nobody/nothing uses those. Why are they there?
The files having effect are cert9.db and key4.db. The correct way of accessing those includes certutil -d sql:/etc/pki/nssdb. Notice the sql: -part difference. That's the part causing most confusion.
To get the certificate into the DB run command on a single line:
certutil -d sql:/etc/pki/nssdb -A -t "C,C,C"
-n "Go Daddy Secure Certificate Authority - G2"
-i /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
Now your NSS DB should list:
# certutil -d sql:/etc/pki/nssdb -L
Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPI
Go Daddy Secure Certificate Authority - G2 C,C,C
The three Cs mean that the certificate in the DB is an authority for servers, e-mail and code signing. certutil docs say, that using 'C' for intermediate certificates is discouraged, and I didn't bother to check if that 'C' is needed at all. But having that doesn't break anything now the setup is done.
Testing
Now, running exactly the same command:
$ curl --verbose https://packetstormsecurity.net/
... will result in:
* About to connect() to dl.packetstormsecurity.net port 443 (#0)
* Trying 198.84.60.200...
* Connected to dl.packetstormsecurity.net (198.84.60.200) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt CApath: none
* SSL connection using TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
* Server certificate:
* subject: CN=packetstormsecurity.com,OU=Domain Control Validated
* start date: May 31 18:04:40 2015 GMT
* expire date: May 31 18:04:40 2016 GMT
* common name: packetstormsecurity.com
* issuer: CN=Go Daddy Secure Certificate Authority - G2,
OU=http://certs.godaddy.com/repository/,
O="GoDaddy.com, Inc.",L=Scottsdale,ST=Arizona,C=US
< HTTP/1.1 200 OK
Yesh! It works!
One hell of a thing to get fixed, but now the trust has been established so that it reaches also Curl and any applications using libcurl.
Final words
This is a multi-mess.
First: Go Daddy messes up their certs. Why isn't their Go Daddy Secure Certificate Authority - G2 in ca-bundle.crt? Why are there two version of Go Daddy Root Certificate Authority - G2?
Second: Having NSS in a Linux is insane! Nobody else is using that for certificate storage. libcurl's support for any own CAs is completely messed up and unusable.
The reason I run an adblocker
Thursday, June 2. 2016
Advertisement blocking is kind of hot topic in today's Internet. Pages with this type of content are becoming more popular:
Hell yeah I block every bit of JavaScript, IFrame and cookie that I don't like of.
The flipside of the issue is that monetization becomes a lot more difficult when no ads are being displayed. New York Times has a quite fresh article about that: Rise of Ad-Blocking Software Threatens Online Revenue. There is nothing new in that, Forbes wrote about the same issue an year ago: Is using ad-blocking software morally wrong? The debate continues. That article says:
"Some critics argue — as I did in a recent post — that the bigger problem is the advertising model that many media outlets are based on, and the fact that it requires them to rely on invasive tracking software, annoying popups and other low-quality advertising. In a sense, ad blockers are sending a message to these publications, telling them to come up with a better experience (and yes, I agree that we at Fortune could probably do a better job of that too)."
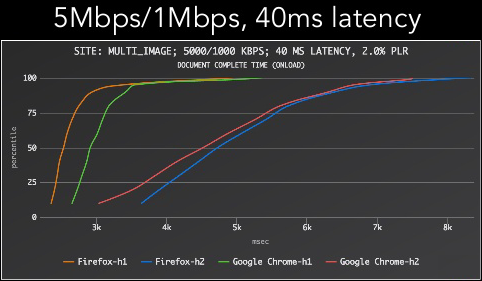
Back to reality. Let's make a practical measurement about those annoying ads. The example is from Wired, one of those who run extensive adblock detection and blocker blocking. Here is page load performance without any blocking:

When AdBlock Plus is enabled:
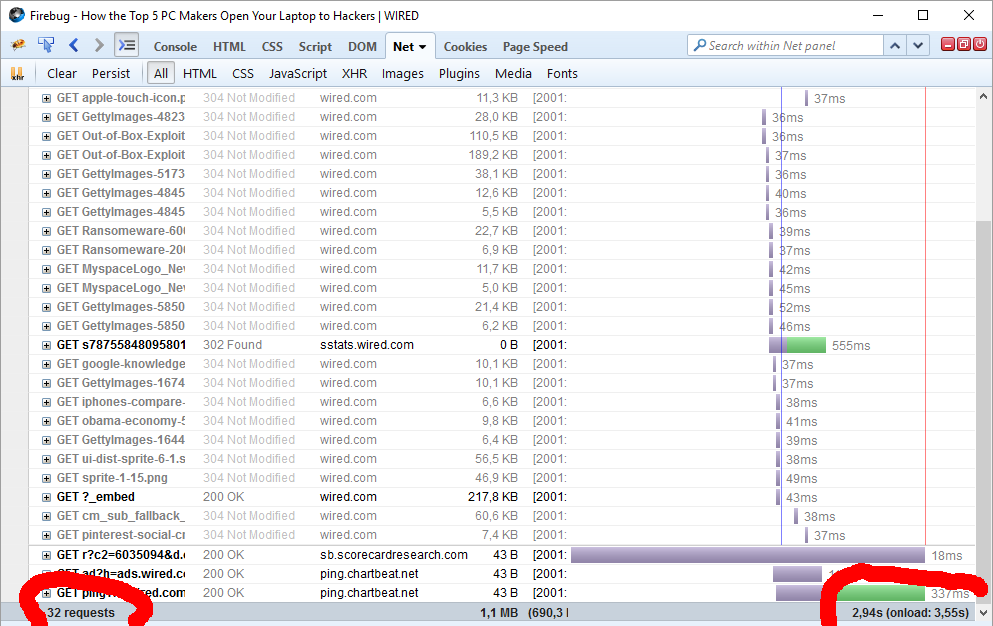
The number of requests goes down from 38 to 32 and total page load time from 5 seconds to 3 seconds. I'd say that's quite an improvement! And all I have to do is NOT to load their stupid and poorly implemented advertisements. You can argue, that it's just a meanigless timing, the end time measured doesn't have any meaning and the page is actually visible and browseable about the same time. Maybe, maybe not. It's my computer, my bandwidth and I choose not to waste it into their crap.
Another example: One of the most popular websites in Finland, Iltalehti:
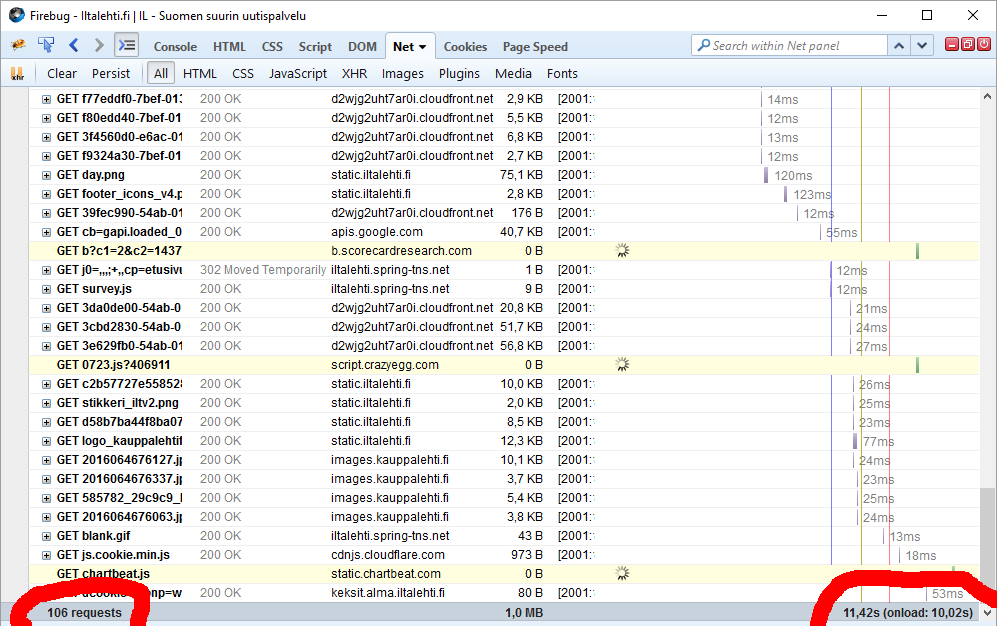
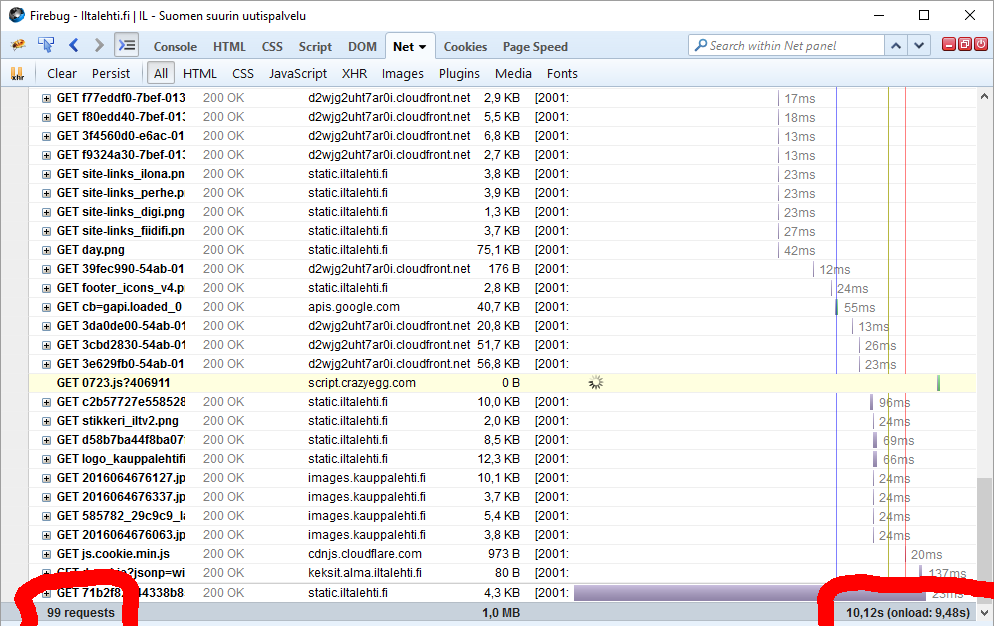
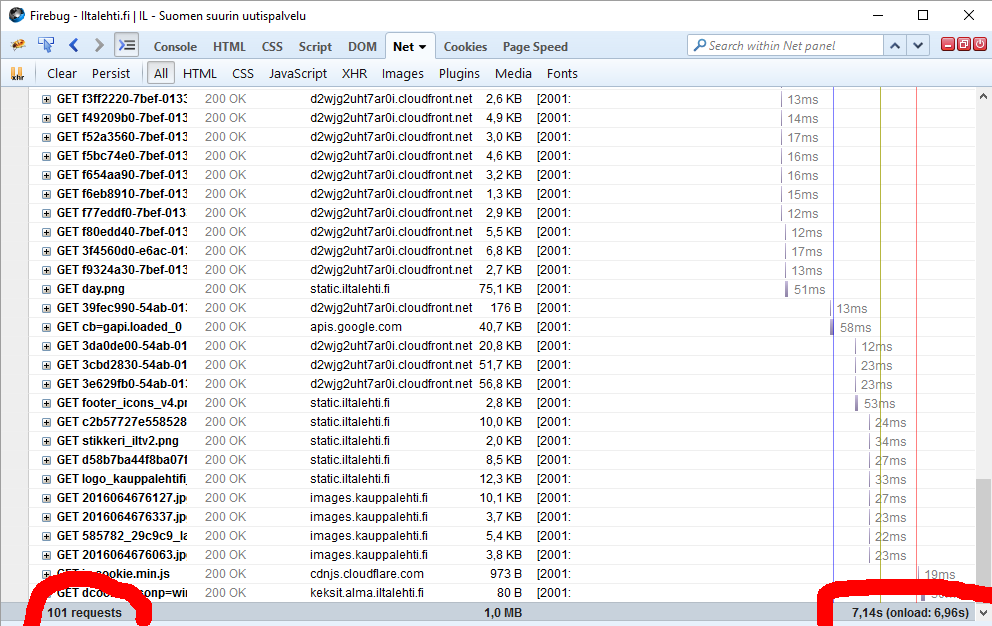
I have three measurements from that: one without blocking, one with only Adblock Plus enabled and finally the mode I normally run at, with NoScript and Adblock Plus. The number of requests made is high, above 100 but it is way too inconclusive. There are way too many dynamic requests being made to get a meaningful figure. The important thing is the page load times, they go down from 10 to 9,5 to 7 seconds. It is a very good indication of how much unnecessary crap a single page loads.
The obvious thing which nobody says aloud is that it is possible to improve page's performance, but nobody cares. There is something fundamentally wrong if a single page loads 100 additional pieces of data. If I'd create a website with that much dynamic loading, I'd probably be fired. But in the nation's most popular website, that's ok. Strange.
Let's look at another example: The same page, but this time on a low-end laptop running Windows 10 and one of the worst browsers there is, Microsoft Edge:
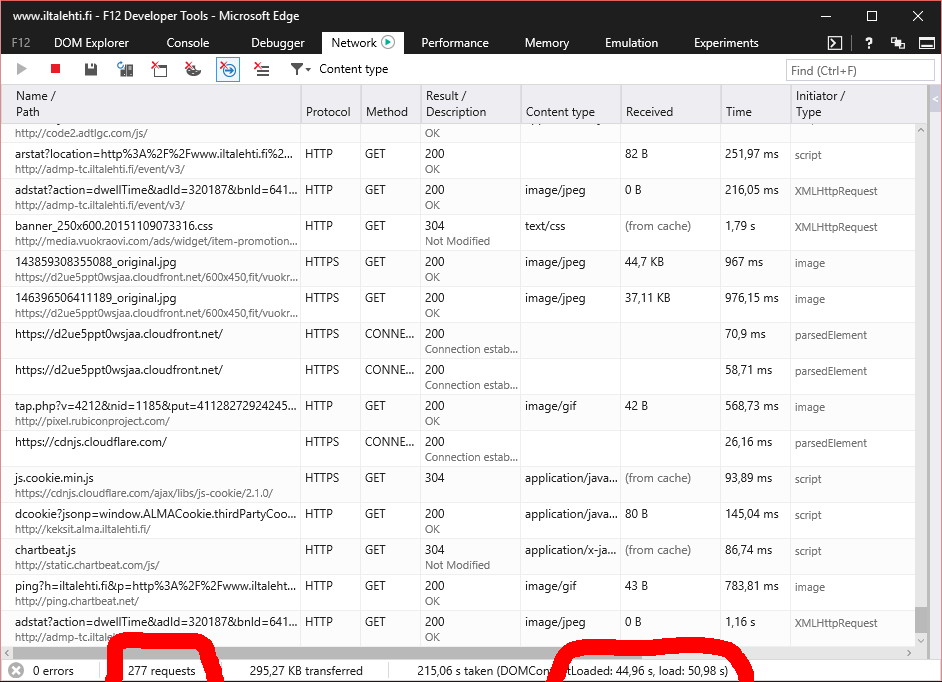
There is no adblocker available for that piece of crap. The page load time is around 45 seconds. On any reasonable browser that would be a fraction of that, not 10 seconds, but still much much faster than that. That poorly optimized turtle-of-a-browser would most definitely benefit from running a lot less bad tracking code and needless blinking ads.
As everything else, also blocking these unwated ads goes mobile, see 2016 Mobile Adblocking Report for details. It doesn't take any rocket surgery to figure out why is that. For example me playing my favorite mobile game:
Pretty much every game has those. The worst thing about those is, that they consume a lot of resources on your mobile. This is the article about the 2012 study: Free apps eat up your phone battery just sending ads and a summary of the scientific study made in Purdue University: Free apps drain smartphone energy on 'advertising modules'. The outcome is:
The free Angry Birds app was shown to consume about 75 percent of its power running "advertisement modules" in the software code and only about 25 percent for actually playing the game. The modules perform marketing functions such as sharing user information and downloading ads.
How do you comment that? You're just running advertisements, not the game.
Btw. I subscribed Wired for $1 USD / week and keep running my adblockers. Their material is good, it's definitely worth that money. I applaud them just because they are inventing such things like that.
Oracle Java download from command line
Friday, February 12. 2016
As Linux system administrator every once in a while you need to install something requiring Java. Open-source guys tend to gear towards OpenJDK, the GPL-licensed version of java. Still, java developers tend to write a lot of crappy code requiring a specific version of run-time-engine. So, you're in a desperate need of Oracle's java.
Now the Oracle people are very keen on you accepting their license before you can get your hands on their precious, leaky, JRE. At the same time all you have in front of you is a Bash-prompt and you're itching to go for a:
wget http://download.oracle.com/otn-pub/java/jdk/8u74-b02/jre-8u74-linux-x64.rpm
Yes. Everybody has tried that. No avail.
All you're going to get with that is a crappy HTML-page saying, that you haven't approved the license agreement and your request is unauthorized.

Darn!
But wait! There is a solution! All the Oracle is looking to see is a specific cookie oraclelicense set with a value accept-securebackup-cookie.
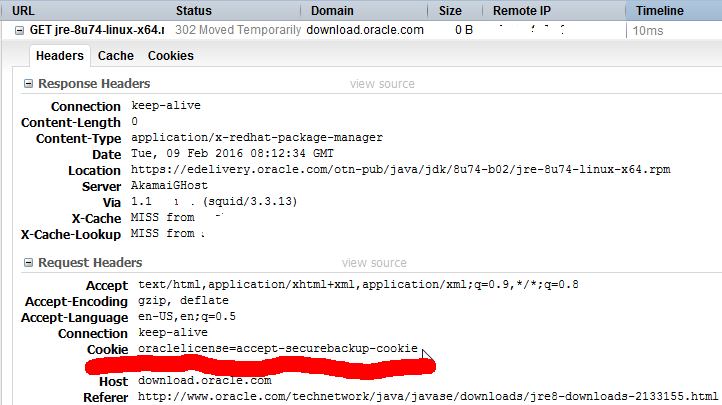
So, to leech the file into your box, you can do a:
wget --header='Cookie: oraclelicense=accept-securebackup-cookie' http://download.oracle.com/otn-pub/java/jdk/8u74-b02/jre-8u74-linux-x64.rpm
Ta daa! No you're rocking.
Apache mod_rewrite: Blocking unwated requests
Thursday, February 11. 2016
S9y plugins: Adding codeTag into CKEditor
Sunday, January 3. 2016
As you may have noticed, I blog a lot about code, computers and operating system configurations. In writtern form, it is very convenient to use Teletype Text -formatting. Here is a demo of the difference:
Do Until NoMoreSwaps = True
NoMoreSwaps = True
For Counter = 1 To (NumberOfItems - 1)
If List(Counter) > List(Counter + 1) Then
NoMoreSwaps = False
Temp = List(Counter)
List(Counter) = List(Counter + 1)
List(Counter + 1) = Temp
End If
Next
NumberOfItems = NumberOfItems - 1
Loop
and:
Do Until NoMoreSwaps = True
NoMoreSwaps = True
For Counter = 1 To (NumberOfItems - 1)
If List(Counter) > List(Counter + 1) Then
NoMoreSwaps = False
Temp = List(Counter)
List(Counter) = List(Counter + 1)
List(Counter + 1) = Temp
End If
Next
NumberOfItems = NumberOfItems - 1
Loop
(Code sample courtesy of Rosetta Code)
Any experienced software developer will prefer the fixed-width font. However, an out-of-the-box Serendipity blog software won't make that possible. I don't get the logic behind that, but there is a drastic change in functionality. To the not-so-user-friendly direction, I'd like to add.
Since version 2.0 S9y has been using CKEditor as HTML-editor on the admin-side. It is a pretty good component and has a number of excellent plugins already available. Getting a codeTag-plugin to work shouldn't be too hard, I guess. Yep! Guessed wrong.
Just downloading a zip-file, and uncompressing it at serendipity/htmlarea/ckeditor/ckeditor/plugins/-directory. Is a good start, but the editor won't react to that, something more is needed.
After a lot of investigating, I figured to add the name of the plugin into into serendipity/htmlarea/ckeditor_s9y_plugin.js. It has a line in it:
var customplugins = 'mediaembed,procurator,cheatsheet,';
adding codeTag into the list does absolutely nothing. It does load the plugin, but as a default, the plugin does nothing that you can see or touch. There is another file with list of editor's icons at serendipity/htmlarea/ckeditor_s9y_config.js. It has an array with list of icons to display:
config.toolbar_Default = []
It looks like this:

After adding this hash-definition into the config.toolbar_Default -array:
{ name: 'codetag', items: [ 'Code' ] }
makes the icon to appear:

... but it doesn't do much when you click it.
Yet another round of debugging revealed, that there is a fixed list of allowed HTML-tags in the same file. The variable is called config.extraAllowedContent. The line is very long, but abbreviated version is something like this:
config.extraAllowedContent = 'mediainsert[*]{*}(*); ... ;pre[*](*);';
I added this to the end of the list:
code;tt;
Now it works as expected!
If you're planning a patch, here are my changes. Run it in serendipity/htmlarea/:
--- ckeditor_s9y_plugin.js.orig 2015-07-24 15:02:54.000000000 +0300
+++ ckeditor_s9y_plugin.js 2016-01-01 15:52:18.333527235 +0200
@@ -17,7 +17,7 @@
// Plugin Dependencies: widget Add-on Dependencies: Line Utilities and Clipboard
// mediaembed is a fast and simple YouTube code CKEditor-Plugin: v. 0.5+ (https://github.com/frozeman/MediaEmbed, 2013-09-12) to avoid ACF restrictions
// procurator and cheatsheet are S9y only plugins
- var customplugins = 'mediaembed,procurator,cheatsheet,';
+ var customplugins = 'mediaembed,procurator,cheatsheet,codeTag,';
// for any new instance when it is created - listen on load
CKEDITOR.on('instanceReady', function(evt){
--- ckeditor_s9y_config.js.orig 2015-07-24 15:02:54.000000000 +0300
+++ ckeditor_s9y_config.js 2016-01-01 16:07:39.055518012 +0200
@@ -65,7 +65,7 @@
- Allow for custom attributes/classes in code blocks
*/
// protect
- config.extraAllowedContent = 'mediainsert[*]{*}(*);gallery[*]{*}(*);media[*]{*}(*);script[*]{*}(*);audio[*]{*}(*);div[*]{*}(*);span[*]{*}(*);img[height,width];pre[*](*);';
+ config.extraAllowedContent = 'mediainsert[*]{*}(*);gallery[*]{*}(*);media[*]{*}(*);script[*]{*}(*);audio[*]{*}(*);div[*]{*}(*);span[*]{*}(*);img[height,width];pre[*](*);code;tt;';
// Do not use auto paragraphs, added to these allowed tags (only!). Please regard that this was marked deprecated by CKE 4.4.5, but is a need for (our use of) extraAllowedContent - check this again by future versions!
config.autoParagraph = false; // defaults(true)
@@ -252,7 +252,8 @@
{ name: 'mediaembed', items: [ 'MediaEmbed' ] },
{ name: 'others', items: s9ypluginbuttons },
{ name: 'document', groups: [ 'mode', 'document', 'doctools' ], items: [ 'Source' ] },
- { name: 'about', items: [ 'About' ] }
+ { name: 'about', items: [ 'About' ] },
+ { name: 'codetag', items: [ 'Code' ] }
];
// console.log(JSON.stringify(config.toolbar_s9y));
Storix - Story of Anthony Johnson continues
Friday, January 1. 2016
Earlier I wrote about Storix and it's author Mr. Johnson.
The story developed further on 15th Dec when a jury gave its verdict about the copyright infrightment claim. A court decided that the copyrigt was transferred to company on 2003. Mr. Johnson claimed that a written memo of 2004 as an annual report didn't transfer the copyright:
It foolishly stated that my sole proprietorship was changed to an S Corp and "all assets" were
transferred over. Of course, I was referring to the cash in the business account, the furniture and
computers. But the jury, based on the courts generic instructions which were contrary to actual
copyright law, decided that it should include any personal assets related to the business,
or any "language that might encompass a copyright".
Obviously this is not the end of the story. There will be a round of appeals.
Btw. In their press release Storix claims to be "the #1 provider of disaster recovery solutions for more than 2,000 global customers". I think there has to be some other player in the disaster recovery business having more customers.

