Signal - Linked Devices
Monday, March 17. 2025
For messaging, there are plenty of choices. I must admit, my thinking is similar to criminals: the less any government knows about me and my messaging, the better. Today, full anonymity is gone. Really, really bad actors were staying below law enforcement radar, and now those really good ones for messaging are gone.
So, I'm doing what Mr. Snowden does and am using Signal daily.
![]()
For governments to keep track on me, Signal works via phone number. My issue with using a phone number as identifying factor is, in any country, there are "like five" different phone numbers (in reality an area code has roughly 10 million different numbers).
As you must feel confused, let me clarify. The reason, I say "5" is because when numbering scheme was designed, 10 million amounted roughtly to infinite. Today, anybody can dial 1000 numbers per second and exhaust the entire number space in less than three hours. Obviously, there are multiple area codes and prefixes, so we have multiple sets of 10 million numbers. So, it would take a day to dial all possible numbers. With single computer. What if somebody could obtain two computers? Or three?
Let's face it phone number as a technical invention has been obsoleted for years. It should NOT be used to identify me in any messaging app. It's convenient to do so. Governments have been tracking phones for many decades and they can demand messaging protocol operators to enforce phone identification. Still, by any measure Signal is the safest option.
Moving on. Phone numbers: bad. Signal: good.
This is what happened the other day:
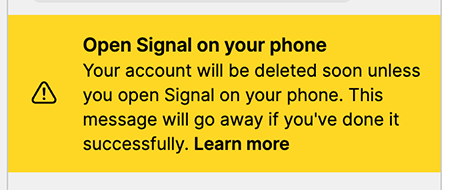
The text said:
Open Signal on your phone
Your account will be deleted soon unless you open Signal on your phone.
This message will go away if you're done it successfully.
For the past two years, I've never used Signal on a mobile device. To me typing messages with a non-keyboard is madness! So, I'm just using messaging from my computer(s).
It seems there is a limit to it.
Government wants to track you, so you must verify the existence of your phone number for every 2 years. Fair.
PostgreSQL 17 upgraded into Blog
Monday, October 14. 2024
On 26th of September, PostgreSQL Global Development Group announced the release of version 17.
Here is an easy one: Can you guess at which point I made the upgrade?

The slope is a maintenance break. Datadog wasn't measuring HTTP-performance while I was tinkering to make the actual upgrade.
What worries me is the performance being itsy-bitsy worse with version 17. Graph is smooth as silk. However, crunching the numbers to smooth the zig-zag, 16 seems to have better performance on average. Difference isn't big, but it is there. Maybe I'm missing a new setting to improve cache performance or something?
On Technology Advancement - Does anybody really use generative AI?
Monday, June 17. 2024
According to this, not.
(Ref.: What does the public in six countries think of generative AI in news? survey)
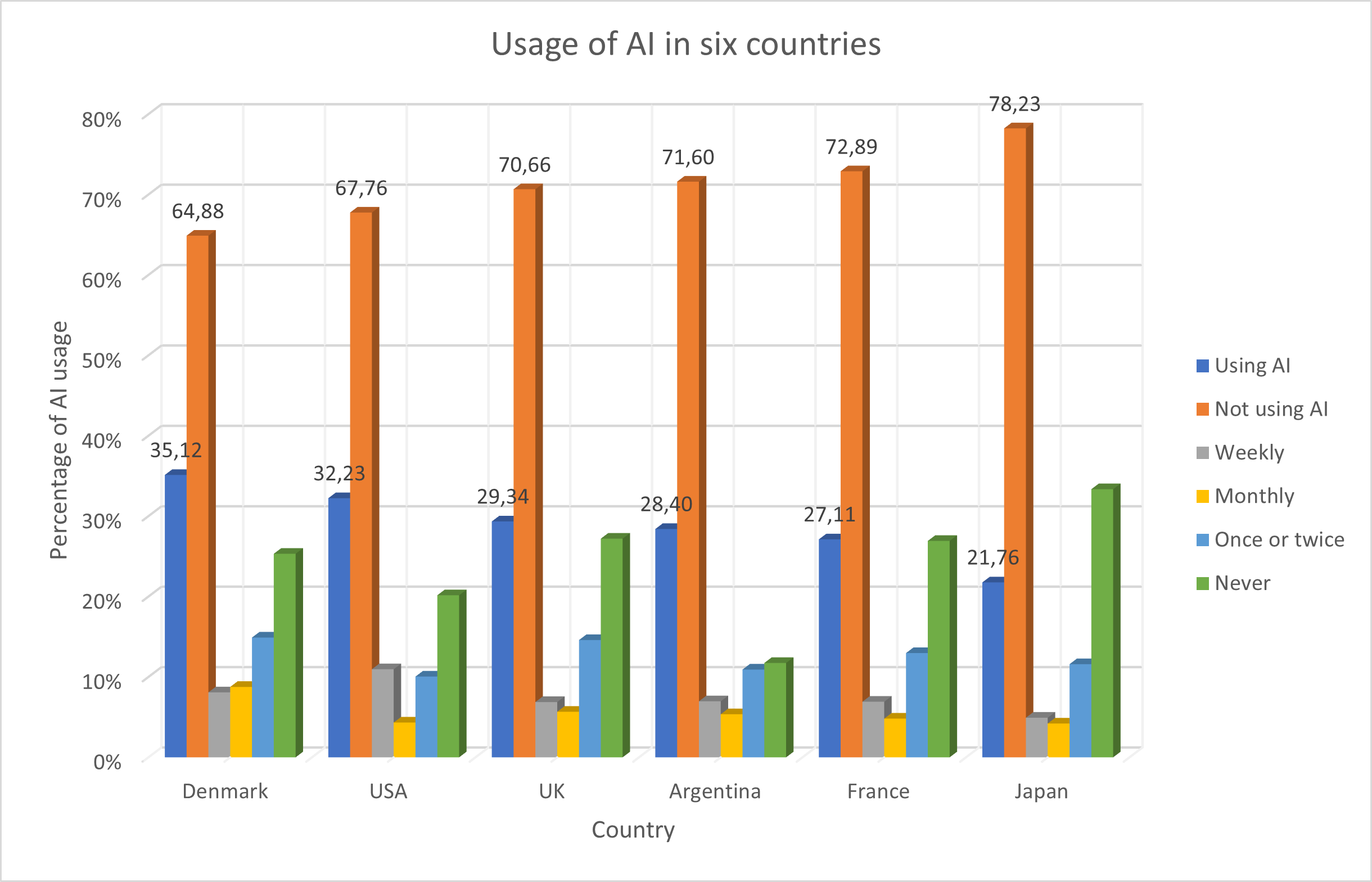
AI is still in its infancy. Those who lived the IT-bubble of 2000 can relate.

British newspaper Daily Mail wrote in its December 5th 2000 issue about Internet. At that point, it was obvious: Internet wasn't a passing fad. Publishing that article back in -95 might have been sane. Just before the bubble was about to burst, not so much.
Let's dig up more examples. When we're faced with technology leap, our reactions can be surprising.

On hindsight (that's always 20/20), it would have made sense to see the vastly improved user experience on communications. Spoken word versus written word isn't a fair fight. Spoken word wins when communication target is time-sensitive and message is brief. Today, most of use don't use our pocket computers for phoning, we use them for writing and reading messages.
How about transportation?
If I had asked people what they wanted, they would have said faster horses.
A phrase Henry Ford did not say. There is a Harvard Business Review story about this.
Not that the line makes sense in any case.
Because “faster” wasn’t the selling point of cars over horses.
Speed wasn’t the problem.
Spending huge amounts of money, time, and space on keeping horses alive and dealing with the literal horse shit was the problem.
So, yes. We will use AI. We are already using AI. It's just like with Internet, telephone or cars. We're learning how to use them. Gartner seems to place generative AI on top of their Hype Cycle for Emerging Technologies 2023:
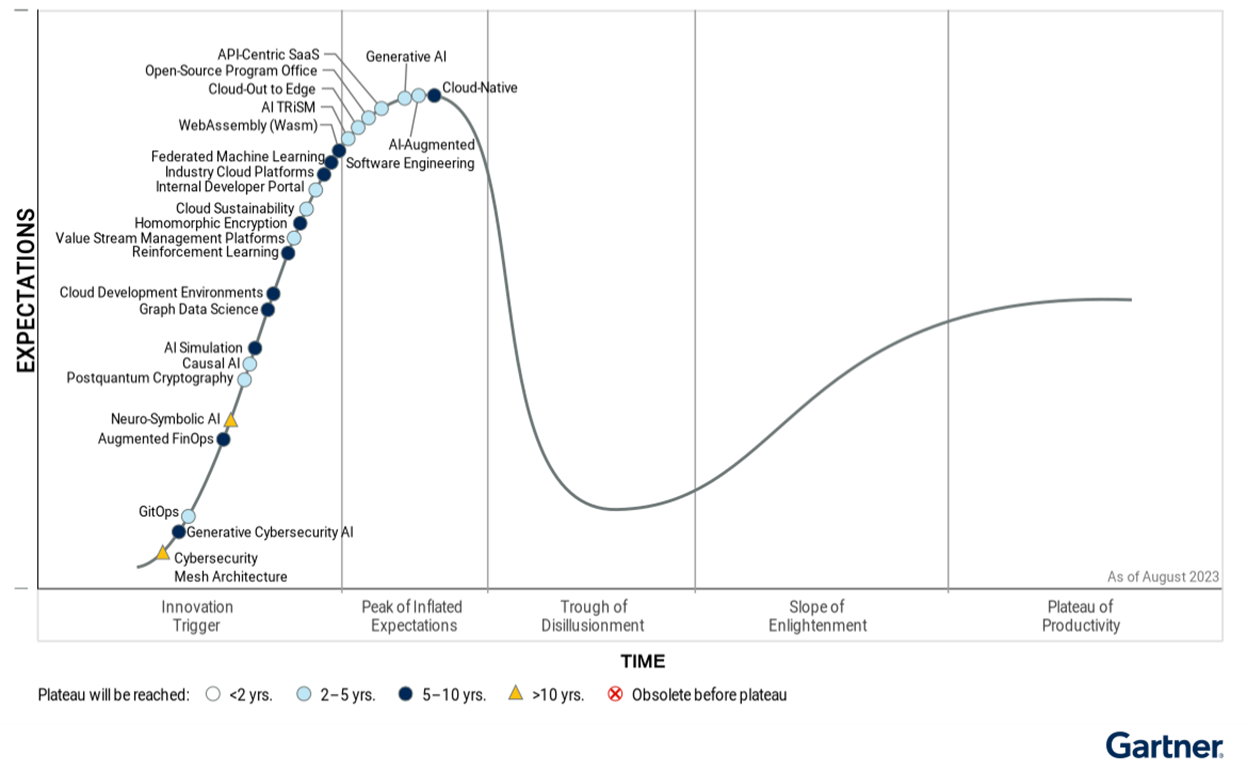
That translates into falling flat with most ridiculous use-cases of AI and sane ones remaining. Before that happens I'll keep using AI, chuckling when it makes a silly mistake and nodding in acceptance when it speeds up my task-at-hand.
Bare Bones Software - BBEdit - Indent with tab
Saturday, October 28. 2023
As a software developer I've pretty much used all text editors there is. Bold statement. Fact remains there aren't that many of them commonly used.
On Linux, I definitely use Vim, rarely Emacs, almost never Nano (any editor requiring Ctrl-s over SSH is crap!).
On Windows, mostly Notepad++ rarely Windows' own Notepad. Both use Ctrl-s, but won't work over SSH-session.
On Mac, mostly BBEdit.
Then there is the long list of IDEs available on many platforms I've used or am still using to work with multiple programming languages and file formats. Short list with typical ones would be: IntelliJ and Visual Studio.
Note: VScode is utter crap! People who designed VScode were high on drugs or plain old-fashioned idiots. They have no clue what a developer needs. That vastly overrated waste-of-disc-space a last resort editor for me.
BBEdit 14 homepage states:
It doesn’t suck.®
Oh, but it does! It can be made less sucky, though.
Here is an example:
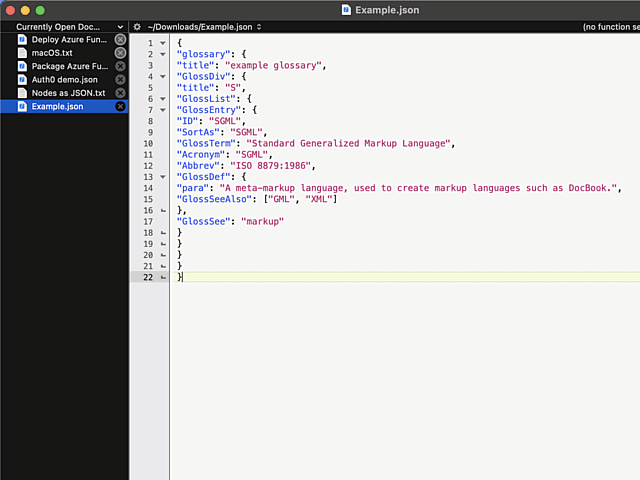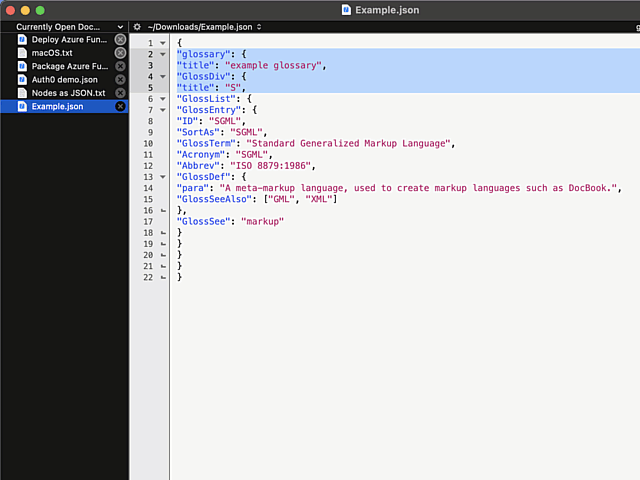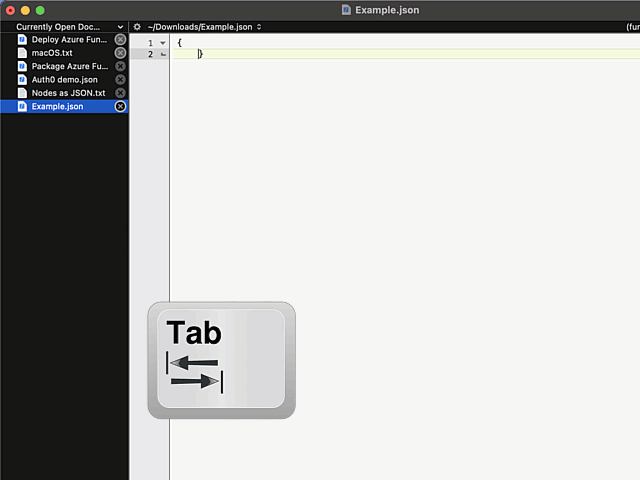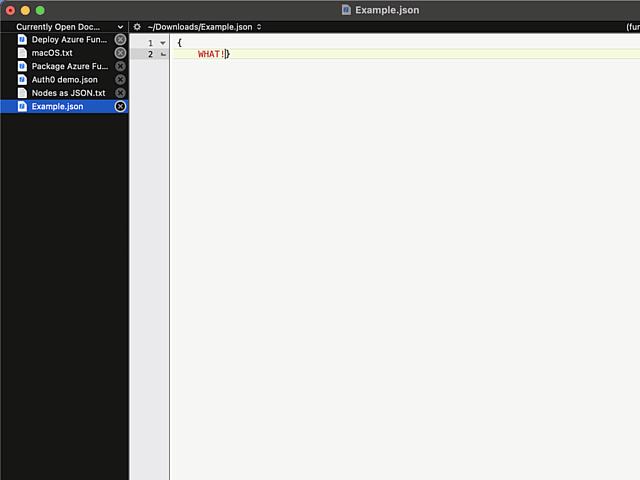
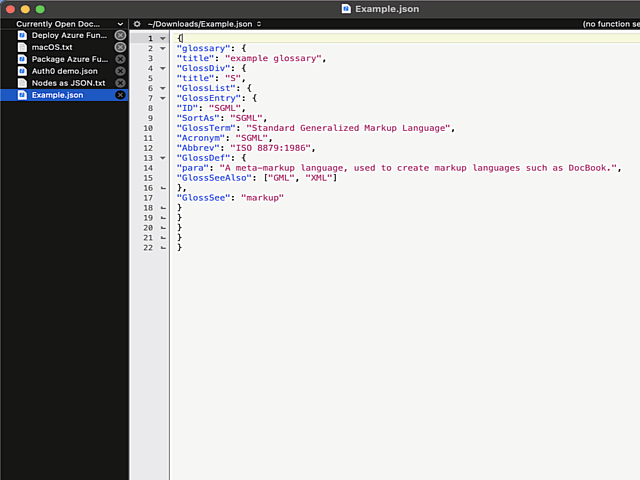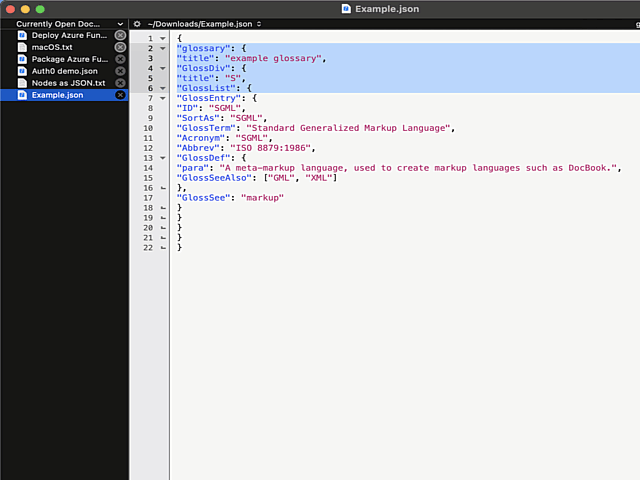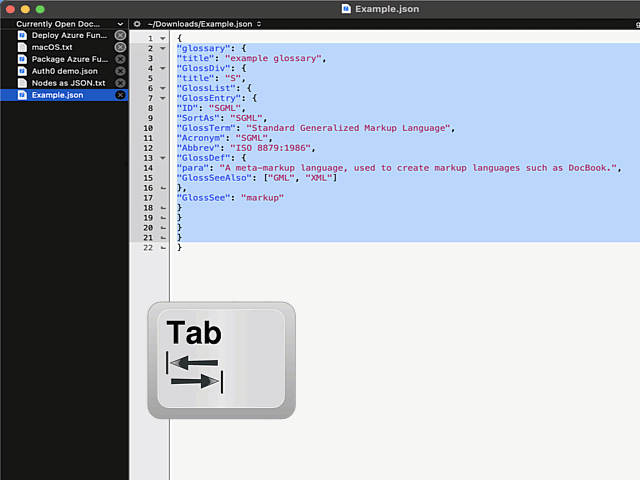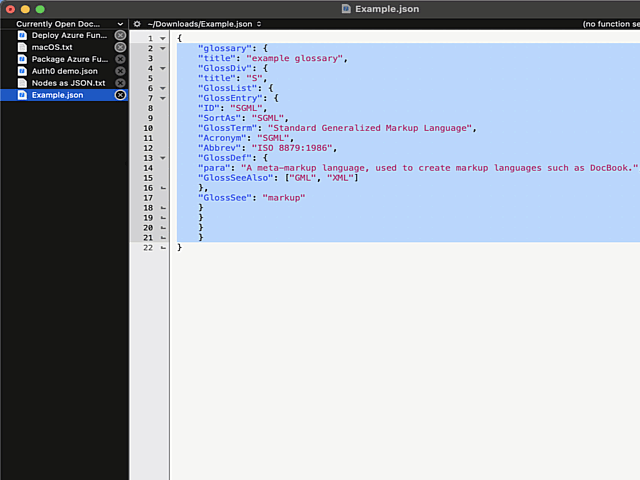
In above example, I'm editing a JSON-file. It happens to be in a rather unreadable state and sprinkling bit of indent on top of it should make the content easily readable.
Remember, earlier I mentioned a long list of editors. Virtually every single one of those has functionality to highlight a section of text and indent selection by pressing Tab. Not BBEdit! It simply replaces entire selection with a tab-character. Insanity!
Remember the statement on not sucking? There is a well-hidden option:
The secret option is called Allow Tab key to indent text blocks and it was introduced in version 13.1.2. Why this isn't default ... correction: Why this wasn't default behaviour from get-go is a mystery.
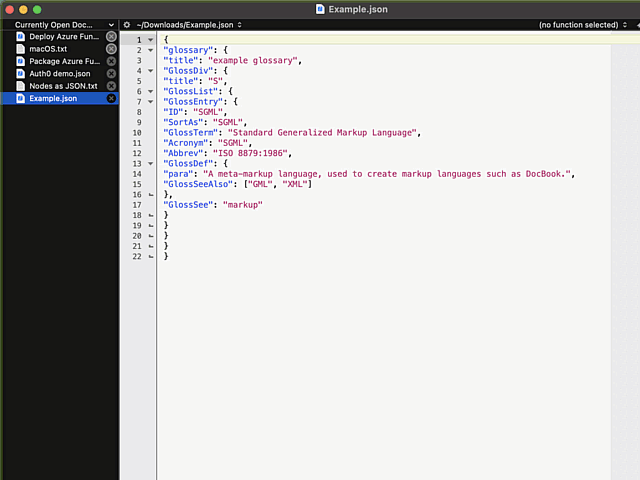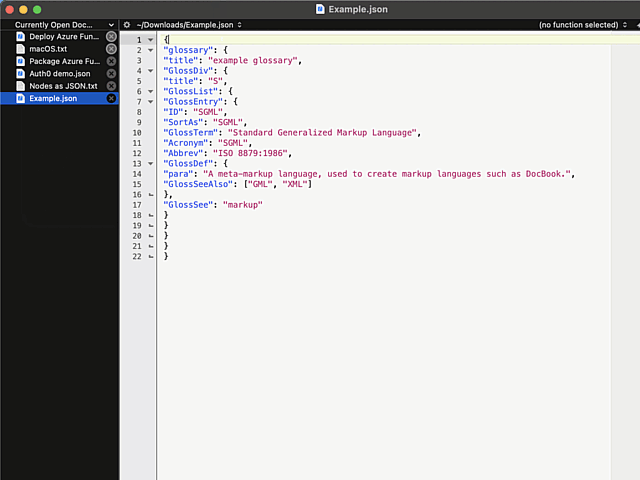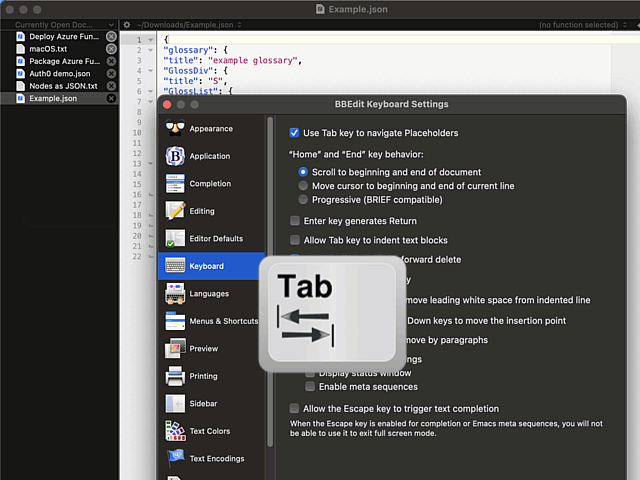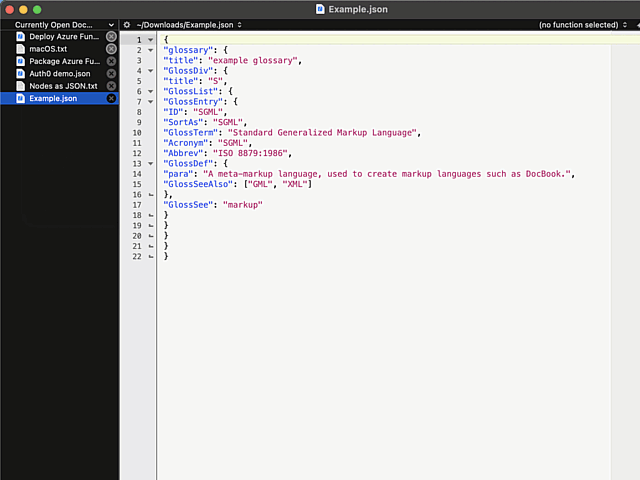
Now the indention works as expected:
What puzzles me is the difficulty of finding the option for indenting with a Tab. I googled wide & far. No avail. Those technical writers @ Barebones really should put some effort on making this option better known.
Postman Making it Mandatory to Store All Information Into Postman's Servers
Monday, June 19. 2023
Postman. Not the guy delivering letters to your mailbox, the software which makes API-development much easier.
Earlier this year I was mighty shocked to learn Postman is tightening its grip on developers.
First they made using a Postman-account mandatory. Any new installation into a workstation MUST login to a Postman-account. Earlier it was a strong suggestion, but there existed a skip-button. Anybody having an old installation can keep their way-of-working. When ever there is a need for new installation, surprise is imminent.
For the record: I do have a Postman-account. On some of my machines, I do login into it to collaborate with other developers. There are number of machines where I do not.
The traditional way-of-working is called "Scratch Pad" in the new world order. This scratchpad will contain any locally stored information such as collections of requests, URL endpoints, variables and secrets. Not sharing such delicate information with anybody is my preferred approach.
Hint: For any logged in user, getting to your scratchpad is surprisingly easy. Access to it is well hidden, but available:
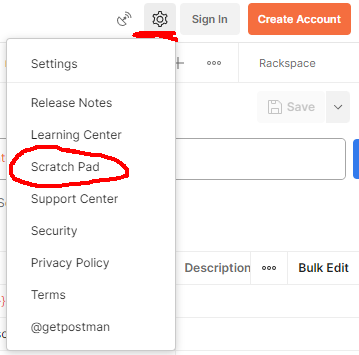
Settings sprocket-wheel will contain the option for Scratch Pad.
There is a change coming.
In September 2023 Postman will force to store all passwords, API-keys, secrets, customer's endpoints to their server. There is a blog post from May 2023: Announcing the new lightweight Postman API Client and sunsetting Scratch Pad.
It remains to be seen if this "lightweight" Postman is a piece of usless crap or not. Somehow I don't see the option of storing precious secrets my customers handed me for safe-keeping to a 3rd party who can do whatever they want with it. In some cases, contractually I'm pretty sure I'm not even allowed do to that!

Custom authentication with Postman Pre-request script
Friday, May 19. 2023
Postman. Not the guy delivering letters to your mailbox, the software which makes API-development much easier.
![]()
With APIs, there are number of authentication mechanisms. All kinds of passwords and keys are used to make sure I'm allowed to make the request. Also, modern authentication mechanisms include OAuth 2.0, OpenID Connect and such. Postman does support OAuth 2.0 out-of-the-box. For those less informed, here is a brief description by Auth0:
OAuth 2.0, which stands for “Open Authorization”, is a standard designed to allow a website or application to access resources hosted by other web apps on behalf of a user.
For the record, OAuth 2.0 is a good protocol. Getting a JWT and making subsequent requests with it is among many things secure & sensible. If you didn't guess it by this far, yes, there is a glitch. RFC 6749 states following in subsection 4.3.2. Access Token Request:
The client makes a request to the token endpoint by adding the following parameters using the "application/x-www-form-urlencoded" format per Appendix B with a character encoding of UTF-8 in the HTTP request entity-body:
grant_type REQUIRED.
Value MUST be set to "password".
username REQUIRED.
The resource owner username.
password REQUIRED.
The resource owner password.
Since 1999 when RFC 2617 was written, we kinda have grown out of sending URL-encoded payloads as form responses. Today, it is 20s and JSON is the way to go. This is the glitch I mentioned, computer says: NO! Spec doesn't state "you may use JSON if you prefer to use it". I do. Many others do too. As Postman is per spec, they don't support JSON-encoded request bodies in OAuth 2.0 in their boxed authentication code. They do support all of the bells/whistles OAuth 2.0 has, but only per-spec.
Again, Postman is a good product, it does support freedom in form of a Pre-request script. I chose to exercise my freedom and crafted a plan is to following:
- Write couple lines of JavaScript to be run as Postman Pre-request script to handle authentication
- Script will be run for every request.
- It is possible to override this mechanism by writing a per-request pre-request script, in which case the collection one will be ignored.
- Per-request script can be as short as "
return" to do a no-op.
- Required authentication credential in form of JWT is stored into Postman collection variables and is generally available for authenticating any request in the collection
- Pre-request script needs to be smart:
- It will contain logic to determine if any further steps to execute an authentication is required or already existing token can be used to save time and resources.
- We don't want to flood the authentication provider by requesting a JWT for everey single time. They might get angry and kick us out if we're too greedy.
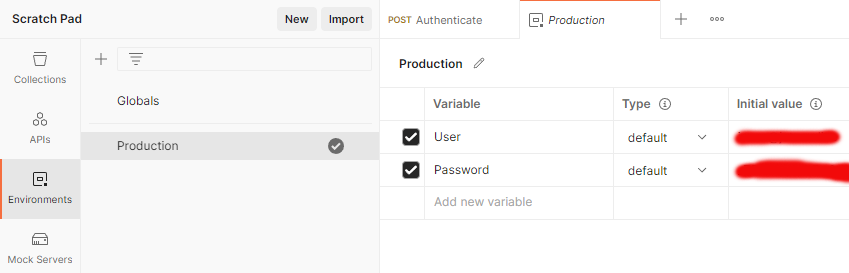
- Script is capable of reading the required authentication credentials for username and password from Postman environment.
- NOTE! Credentials are not read from Collection, from Environment.
- These credentials will be exhcnaged into a token. The token will be used for actual authentication.
- Authentication protocol used is OAuth 2.0 ish, using JSON-body and expecting a JSON-response.
- That's it. Done!
This is my Postman request-collection with the pre-request script:
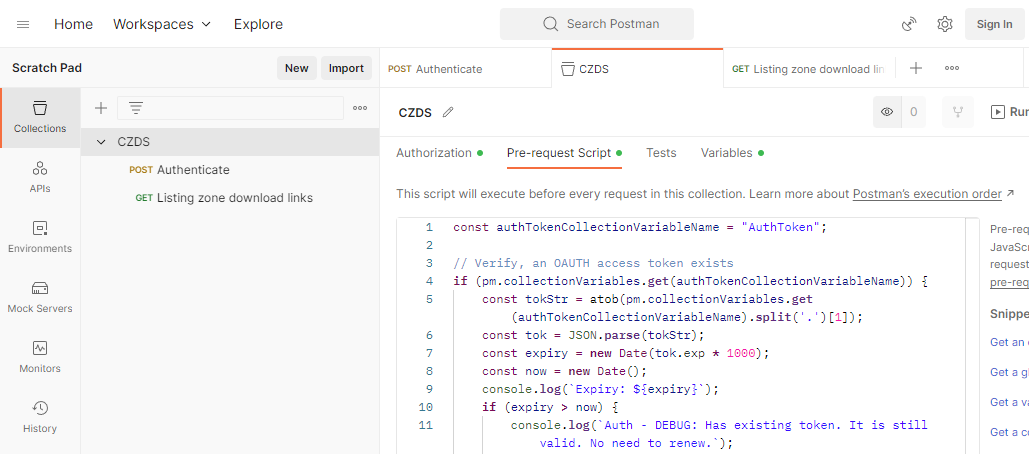
Further, I have collection variables and the environment (the name I have for this environment is Production):

Here is one request using the pre-request -script from collection:
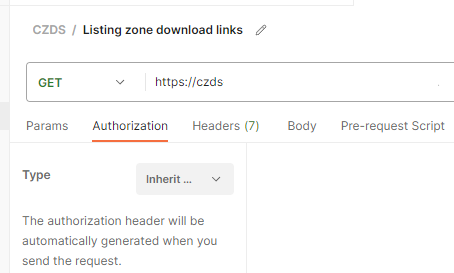
There isn't much setup needed. It just inherits the authorization setting from collection. Simple!
Full script I have is as follows:
const authTokenCollectionVariableName = "AuthToken";
// Verify, an OAUTH access token exists
if (pm.collectionVariables.get(authTokenCollectionVariableName)) {
const tokStr = atob(pm.collectionVariables.get(authTokenCollectionVariableName).split('.')[1]);
const tok = JSON.parse(tokStr);
const expiry = new Date(tok.exp * 1000);
const now = new Date();
console.log(`Expiry: ${expiry}`);
if (expiry > now) {
console.log(`Auth - DEBUG: Has existing token. It is still valid. No need to renew.`);
return;
}
console.log(`Auth - DEBUG: Has existing token. Renewing expired one.`);
} else {
console.log(`Auth - DEBUG: No existing token found. Requesting one.`);
}
// Refresh the access token and set it into environment variable
pm.sendRequest({
url: pm.collectionVariables.get("Account_API_BaseURL") + "/api/authenticate",
method: 'POST',
header: {
'Accept': 'application/json',
'Content-Type': 'application/json'
},
body: {
mode: 'raw',
raw: JSON.stringify({
username: pm.environment.get("User"),
password: pm.environment.get("Password")
})
}
}, (error, response) => {
pm.expect(error).to.equal(null);
pm.expect(response).to.have.property('code', 200);
pm.collectionVariables.set(authTokenCollectionVariableName, response.json().accessToken);
console.log(`Auth - INFO: Saved token ok.`);
});
To repeat: This script will run only inside Postman as embedded script. If you just whip up a random JavaScript environment, it most certainly will not have a pm-object in it and if it does, you cannot do all those fancy things I'm doing there.
Now the problem is solved. My requests run as smoothly and effortlessy as they would run with 100% per-RFC OAuth 2.0.
AMD Software: Adrenalin Edition - Error 202
Saturday, April 29. 2023
GPU drivers are updated often. The surprise comes from the fact, the update fails. What! Why! How is this possible?
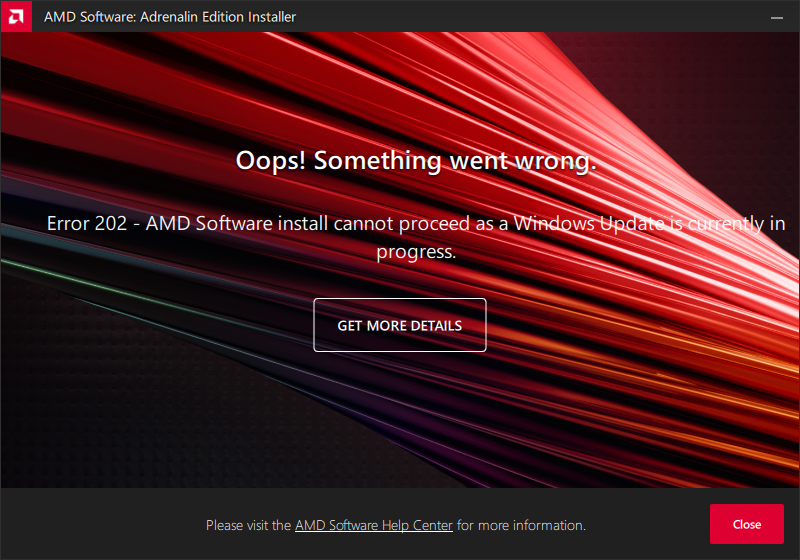
Error 202 – AMD Software Installer Cannot Proceed as a Windows Update Is Currently in Progress
Making sure, this isn't a fluke. I did retry. A few times, actually. Nope. Didn't help.
I'm not alone with this. In AMD community, there is a thread Error 202 but there's no pending Windows Update. Also, on my Windows, there was nothing pending:
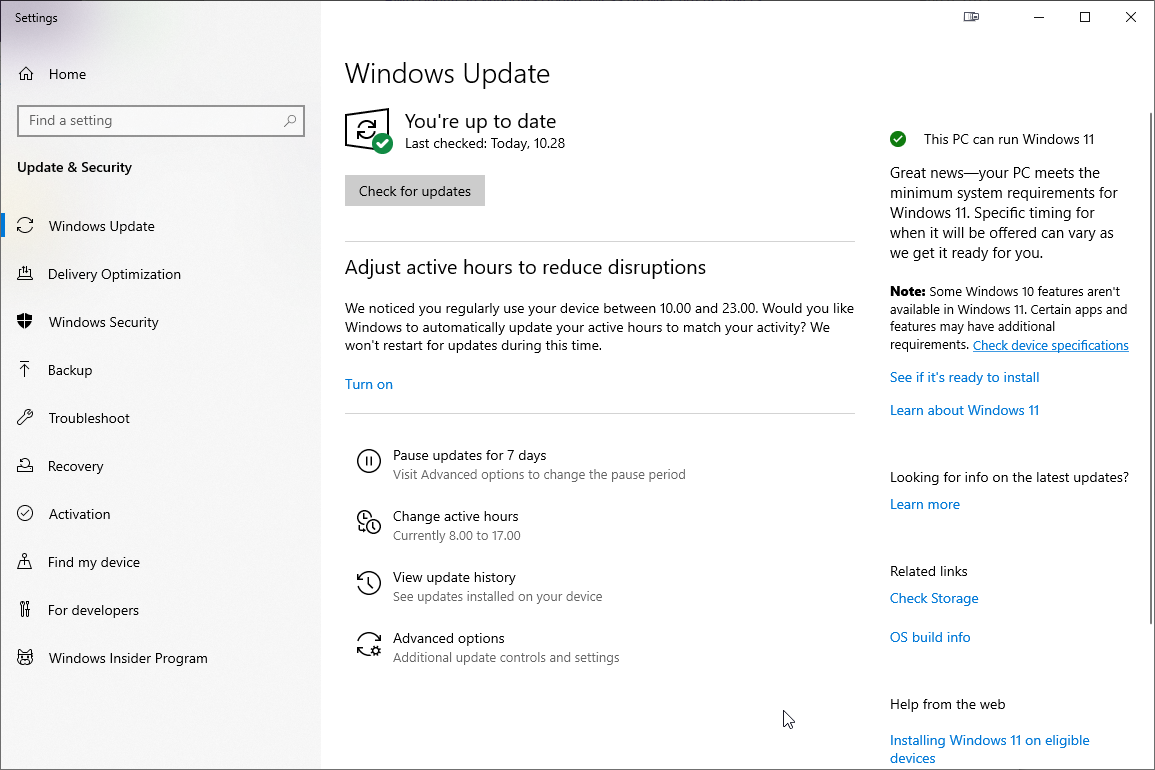
As this was the first time I had a hiccup, I realized I knew nothing about the installer. Always on Windows, it pays off to run setup.exe with switch /?. This is what will be displayed:
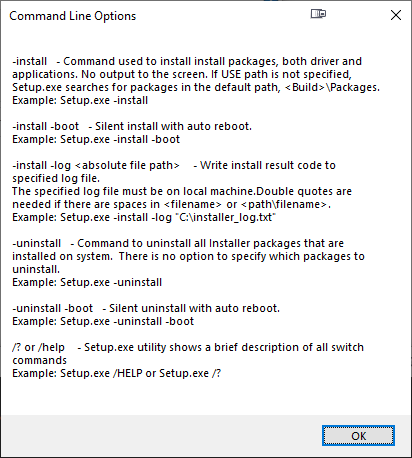
Haa! Options. Going for: .\Setup.exe -install -boot -log inst.log
After, the expected failure, log reveals:
InstallMan::isDisplayDriverEligibleToInstall :6090 Display driver Eligible to Install
isWindowsServiceStopped :4102 Queried Windows Update Status: 4
pauseWindowsUpdate :5244 drvInst.exe is currently running
InstallMan::performMyState :5177 ERROR --- InstallMan -> Caught an AMD Exception. Error code to display to user: 202. Debug hint: "drvInst.exe is currently running"
No idea where the claim of drvInst.exe is currently running comes from. It isn't! Obviously something is reading Windows Update status wrong. Let's see what'll happen if I'll bring the Windows Update service down with a simple PowerShell-command: Stop-Service -Name wuauserv
Ta-daa! It works! Now installation will complete.
OpenSSH 8.8 dropped SHA-1 support
Monday, October 25. 2021
OpenSSH 8.3 client fails with: load pubkey invalid format - Part 2
Sunday, September 13. 2020
load pubkey: invalid formatThe original blog post is here.
Now Mr. Stott approached me with a comment. He suggested to check the new OpenSSH file format.
I was like "What?! New what? What new format!".
The obvious next move was to go googling the topic. And yes, indeed there exists two common formats for stored OpenSSH keys. Two pieces of articles I found most helpful were The OpenSSH Private Key Format and Openssh Private Key to RSA Private Key. Reading ssh-keygen man-page states:
-m key_format
Specify a key format for key generation, the -i (import), -e (export) conversion options, and the -p change passphrase operation.
The latter may be used to convert between OpenSSH private key and PEM private key formats.
The supported key formats are: “RFC4716” (RFC 4716/SSH2 public or private key), “PKCS8” (PKCS8 public or private key) or “PEM” (PEM public key).
The commonly used two formats can be identified by first line of the private key. Old format has the header of
-----BEGIN EC PRIVATE KEY-----. Obviously, those who are using RSA or Ed25519 keys, the word "EC" would be different. I've been using ECDSA for a while and am considering moving forward with Ed25519 when all of my clients and servers have proper support for it.
I've always "loved" (to hate) SSH's (non-)intuitive user experience. As suggested by all source, to convert my existing key to new PEM-format all I need is to whip up a key generator and use it to change the passphrase. Yeah. 
As my OpenSSH-client is OpenSSH_8.3p1 31 Mar 2020, its ssh-keygen will default to output keys in the new format. Depending on your version, the defaults might vary. Anyway, if you're on a really old version, you won't be having the mentioned problem in the first place.
Warning: Changing private key passphrase will execute an in-place replace of the file. If you'll be needing the files in old format, best backup them first. Also, you can convert the format back if you want. It won't produce an exact copy of the original file, but it will be in old format.
For those not using passphrases in their private files: you can always enter the same passphrase (nothing) to re-format the files. The operation doesn't require the keys to have any.
Example conversion:
$ ssh-keygen -p -f my-precious-SSH-key
Enter old passphrase:
Enter new passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved with the new passphrase.
Now the first line of the private key stands at:
-----BEGIN OPENSSH PRIVATE KEY-----
Notice how the key type has been changed into "OPENSSH". The key is still an ECDSA-key, but has been stored in a different.
Testing with the new key indicates a success. Now more warnings, but connectivity is still there. After the conversion, my curves are still elliptic in the right places for the server to grant access! Nice.
Arpwatch - Upgraded and explained
Friday, July 24. 2020
For many years I've run my own systems at home. Its given most of you do much less system running than I. There are servers and network switches and wireless routers, battery-backed power supplies and so on. Most of that I've written about in this blog earlier.
There is many security aspects any regular Jane lay-person won't spend a second thinking of. One of them is: What hardware runs on my home network? In my thinking that question is in top 3 -list.
The answer to that one is very trivial and can be found easily from your own network. Ask the network! It knows.
ARP - Address Resolution Protocol
This is in basics of IPv4 networking. A really good explanation can be found from a CCNA (Cisco Certified Network Associate) study site https://study-ccna.com/arp/: a network protocol used to find out the hardware (MAC) address of a device from an IP address. Well, to elaborate on that. Every single piece of hardware has an unique identifier in it. You may have heard of IMEI in your 3G/4G/5G phone, but as your phone also supports Wi-Fi, it needs to have an identifier for Wi-Fi too. A MAC-address.
Since Internet doesn't work with MAC-addresses, a translation to an IP-address is needed. Hence, ARP.
Why would you want to watch ARPs?
Simple: security.
If you know every single MAC-address in your own network, you'll know which devices are connected into it. If you think of it, there exists a limited set of devices you WANT to have in your network. Most of them are most probably your own, but what if one isn't? Wouldn't it be cool to get an alert quickly every time your network sees a device it has never seen before. In my thinking, yes! That would be really cool.
OUIs
Like in shopping-TV, there is more! A 48-bit MAC-address uniquely identifies the hardware connected to an Ethernet network, but it also identifies the manufacturer. Since IEEE is the standards body for both wired and wireless Ethernet (aka. Wi-Fi), they maintain a database of Organizationally unique identifiers.
An organizationally unique identifier (OUI) is a 24-bit number that uniquely identifies a vendor, manufacturer, or other organization.
OUIs are purchased from the Institute of Electrical and Electronics Engineers (IEEE) Registration Authority by the assignee (IEEE term for the vendor, manufacturer, or other organization).
The list is freely available at http://standards-oui.ieee.org/oui/oui.csv in CSV-format. Running couple sample queries for hardware seen in my own network:
$ fgrep "MA-L,544249," oui.csv
MA-L,544249,Sony Corporation,Gotenyama Tec 5-1-2 Tokyo Shinagawa-ku JP 141-0001
$ fgrep "MA-L,3C15C2," oui.csv
MA-L,3C15C2,"Apple, Inc.",1 Infinite Loop Cupertino CA US 95014
As we all know, CSV is handy but ugly. My favorite tool Wireshark does pre-process the ugly CSV into something it can chew without gagging. In Wireshark source code there is a tool, make-manuf.py producing output file of manuf containing the information in a more user-friendly way.
Same queries there against Wireshark-processed database:
$ egrep "(54:42:49|3C:15:C2)" manuf
3C:15:C2 Apple Apple, Inc.
54:42:49 Sony Sony Corporation
However, arpwatch doesn't read that file, a minor tweak is required. I'm running following:
perl -ne 'next if (!/^([0-9A-F:]+)\s+(\S+)\s+(.+)$/); print "$1\t$3\n"' manuf
... and it will produce a new database usable for arpwatch.
Trivial piece of information: Apple, Inc. has 789 OUI-blocks in the manuf-file. Given 24-bit addressing they have 789 times 16M addresses available for their devices. That's over 13 billion device MAC-addresses reserved. Nokia has only 248 blocks.
Practical ARP with a Blu-ray -player
Let's take a snapshot of traffic.
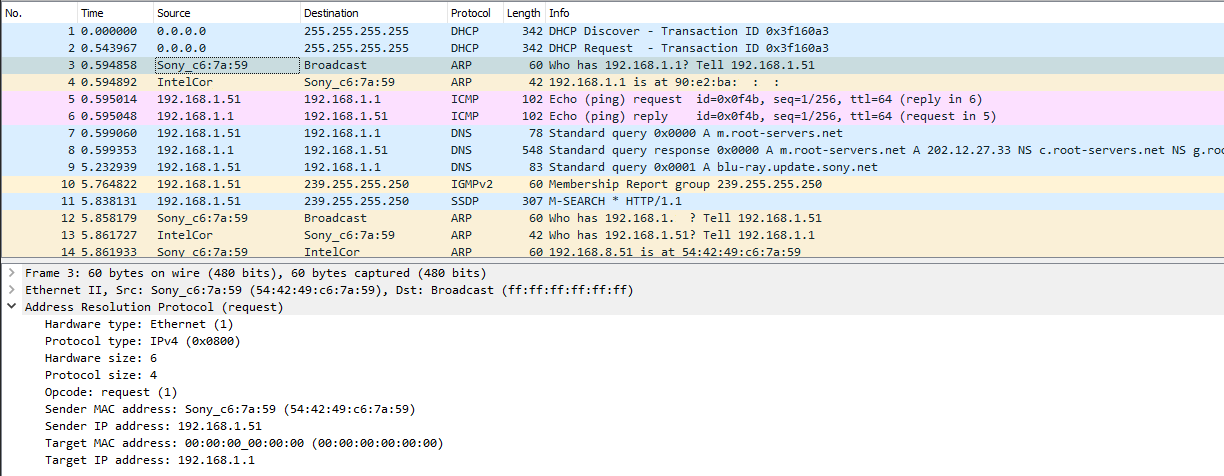
This s a typical boot sequence of a Sony Blu-ray player BDP-S370. What happens is:
- (Frames 1 & 2) Device will obtain an IPv4-address with DHCP, Discover / Offer / Request is missing the middle piece. Hm. weird.
- (Frame 3) Instantly after knowing the own IPv4-address, the device will ARP-request the router (192.168.1.1) MAC-address as the device wants to talk into Internet.
- (Frames 5 & 6) Device will ping (ICMP echo request) the router to verify its existence and availability.
- (Frames 7-9) Device won't use DHCP-assigned DNS, but will do some querying of its own (discouraged!) and check if a new firmware is available at
blu-ray.update.sony.net. - (Frame 12) Device starts populating its own ARP-cache and will query for a device it saw in the network. Response is not displayed.
- (Frames 13 & 14) Router at 192.168.1.1 needs to populate its ARP-cache and will query for the Blu-ray player's IPv4-address. Device will respond to request.
- Other parts of the capture will contain ARP-requests going back and forth.
Practical ARP with a Linux 5.3
Internet & computers do evolve. What we saw there in a 10 year old device is simply the old way of doing things. This is how ARP works in a modern operating system:
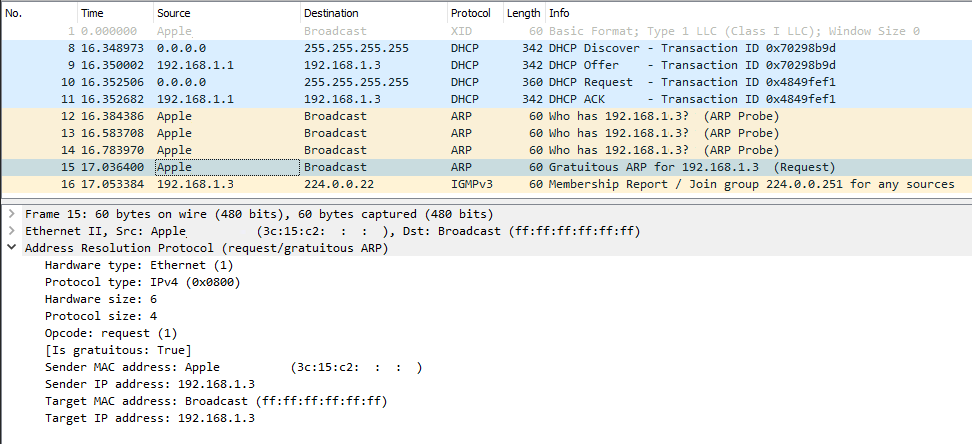
In this a typical boot sequence. I omitted all the weird and unrelated stuff and that makes the first frame as #8. What happens in the sequence is:
- (Frames 8-11) Device will obtain an IPv4-address with DHCP, Discover / Offer /Request / Ack -sequence is captured in full.
- (Frames 12-14) Instantly after knowing the own IPv4-address, the device will ARP-request the IPv4 address assigned into it. This is a collision-check to confirm nobody else in the same LAN is using the same address.
- (Frame 15) Go for a Gratuitous ARP to make everybody else's life easier in the network.
- Merriam-Webster will define "gratuitous" as:
not called for by the circumstances :
not necessary, appropriate, or justified :
unwarranted - No matter what, Gratuitous ARP is a good thing!
- Merriam-Webster will define "gratuitous" as:
- (Frame 16) Join IGMPv3 group to enable multicast. This has nothing to do with ARP, though.
The obvious difference is the existence of Gratuitous ARP "request" the device did instantly after joining the network.
- A gratuitous ARP request is an Address Resolution Protocol request packet where the source and destination IP are both set to the IP of the machine issuing the packet and the destination MAC is the broadcast address ff:ff:ff:ff:ff:ff. A new device literally is asking questions regarding the network it just joined from itself! However, the question asking is done in a very public manner, everybody in the network will be able to participate.
- Ordinarily, no reply packet will occur. There is no need to respond to an own question into the network.
- In other words: A gratuitous ARP reply is a reply to which no request has been made.
- Doing this seems no-so-smart, but gratuitous ARPs are useful for four reasons:
- They can help detect IP conflicts. Note how Linux does aggressive collision checking by its own too.
- They assist in the updating of other machines' ARP tables. Given Gratuitous ARP, in the network capture, there are nobody doing traditional ARPing for the new device. They already have the information. The crazy public-talking did the trick.
- They inform switches of the MAC address of the machine on a given switch port. My LAN-topology is trivial enough for my switches to know which port is hosting which MAC-addresses, but when eyeballing the network capture, sometimes switches need to ARP for a host to update their MAC-cache.
- Every time an IP interface or link goes up, the driver for that interface will typically send a gratuitous ARP to preload the ARP tables of all other local hosts. This sums up reasons 1-3.
How can you watch ARPs in a network?
Simple: run arpwatch in your Linux-router.
Nice people at Lawrence Berkeley National Laboratory (LBNL) in Berkeley, California have written a piece of software and are publishing it (among others) at https://ee.lbl.gov/. This ancient, but maintained, daemon has been packaged into many Linux-distros since dawn of time (or Linux, pick the one which suits you).
As already established, all devices will ARP on boot. They will ARP also later during normal operations, but that's beside the point. All a device needs to do is to ARP once and it's existence is revealed. When the daemon sees a previously unknown device in your network, it will emit a notification in form of an email. Example:
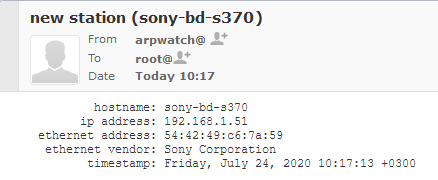
Here, my router running arpwatch saw a Sony Blu-ray player BDP-S370. The ethernet address contains the 24-bit OUI-part of 54:42:49 and remaining 24-bits of a 48-bit MAC will identify the device. Any new devices are recorded into a time-stamped database and no other notifications will be made for that device.
Having the information logged into a system log and receiving the notification enables me to ignore or investigate the device. For any devices I know can be ignored, but anything suspicious I'll always track.
IPv6 and ARP
Waitaminute! IPv6 doesn't do ARP, it does Neighbor Discovery Protocol (NDP).
True. Any practical implementation does use dual-stack IPv4 and IPv6 making ARP still a viable option for tracking MAC-addresses. In case you use a pure-IPv6 -network, then go for addrwatch https://github.com/fln/addrwatch. It will support both ARP and NDP in same tool. There are some shortcomings in the reporting side, but maybe I should take some time to tinker with this and create a patch and a pull-request to the author.
Avoiding ARP completely?
Entirely possible. All a stealth device needs to do is to piggy-back an existing device's MAC-address in the same wire (or wireless) and impersonate that device to remain hidden-in-plain-sight. ARP-watching is not foolproof.
Fedora updated arpwatch 3.1 RPM
All these years passed and nobody at Fedora / Red Hat did anything to arpwatch.
Three big problems:
- No proper support for
/etc/sysconfig/in systemd-service. - Completely outdated list of Organizationally Unique Identifier (OUIs) used as Ethernet manufacturers list displaying as unknown for anything not 10 years old.
- Packaged version was 2.1 from year 2006. Latest is 3.1 from April 2020.
Here you go. Now there is an updated version available, Bug 1857980 - Update arpwatch into latest upstream contains all the new changes, fixes and latest upstream version.
Given systemd, for running arpwatch my accumulated command-line seems to be:
/usr/sbin/arpwatch -F -w 'root (Arpwatch)' -Z -i eth0
That will target only my own LAN, both wired and wireless.
Finally
Happy ARPing!
OpenSSH 8.3 client fails with: load pubkey invalid format
Saturday, July 11. 2020
Update 13th Sep 2020:
There is a follow-up article with a key format conversion infromation.
Ever since updating into OpenSSH 8.3, I started getting this on a connection:
$ ssh my-great-linux-server
load pubkey "/home/me/.ssh/id_ecdsa-my-great-linux-server": invalid format
Whaaaat!
Double what on the fact, that connection works. There is no change in connection besided the warning.
8.3 release notes won't mention anything about that (OpenSSH 8.3 released (and ssh-rsa deprecation notice)). My key-pairs have been elliptic for years and this hasn't bothered me. What's going on!?
Adding verbosity to output with a -vvv reveals absolutely nothing:
debug1: Connecting to my-great-linux-server [192.168.244.1] port 22.
debug1: Connection established.
load pubkey "/home/me/.ssh/id_ecdsa-ecdsa-my-great-linux-server": invalid format
debug1: identity file /home/me/.ssh/id_ecdsa-ecdsa-my-great-linux-server type -1
debug1: identity file /home/me/.ssh/id_ecdsa-ecdsa-my-great-linux-server-cert type -1
debug1: Local version string SSH-2.0-OpenSSH_8.3
Poking around, I found this article from Arch Linux forums: [SOLVED] openssh load pubkey "mykeyfilepath": invalid format
Apparently OpenSSH-client now requires both the private AND public keys to be available for connecting. Mathematically the public key isn't a factor. Why would it be needed? I cannot understand the decision to throw a warning about assumed missing key. I do have the key, but as I won't need it in my client, I don't have it available.
Simply touching an empty file with correct name won't clear the warning. The actual public key of the pair needs to be available to make the ridiculous message go away.
After little bit of debugging points to the problem in ssh.c:
check_load(sshkey_load_public(cp, &public, NULL),
filename, "pubkey");
Link: https://github.com/openssh/openssh-portable/blob/V_8_3_P1/ssh.c#L2207
Tracking the change:
$ git checkout V_8_3_P1
$ git log -L 2207,2207:ssh.c
.. points to a commit 5467fbcb09528ecdcb914f4f2452216c24796790 (Github link), which was made exactly two years ago in July 11th 2018 to introduce this checking of loaded public key and emitting a hugely misleading error message on failure.
To repeat:
Connecting to a server requires only private key. The public key is used only at the server end and is not mathematically required to establish encrypted connection from a client.
So, this change is nothing new. Still the actual reason for introducing the check_load()-call with most likely non-existing public key is a mystery. None of the changes made in the mentioned commit or before it explains this addition, nor there are no significant changes made in the actual public key loading. A check is added, nothing more.
Fast forward two years to present day. Now that the 8.3 is actually used by a LOT of people, less than a month ago the problem was fixed. Commit c514f3c0522855b4d548286eaa113e209051a6d2 (Github link) fixes the problem by simulating a Posix ENOENT when the public key was not found from expected locations. More details about that error are in errno (7) man page.
Problem solved. All we all need to do is wait for this change to propagate to the new clients. Nobody knows how long that will take as I just updated this. 
Practical Internet Bad Neighborhoods with Postfix SMTPd
Sunday, April 26. 2020
Bad what?
Neighbourhood. In The Internet. There is a chance you live in one. It is not likely, but entirely possible. Most ISPs offering services to you are NOT bad ones.
This idea of a "bad neighbourhood" comes from University of Twente. Back in 2013 Mr. Moura did his PhD thesis titled "Internet Bad Neighborhoods". Summary:
Of the 42,000 Internet Service Providers (ISPs) surveyed, just 20 were found to be responsible for nearly half of all the internet addresses that send spam. That just is one of the striking results of an extensive study that focused on “Bad Neighborhoods” on the internet (which sometimes correspond to certain geographical areas) that are the source of a great deal of spam, phishing or other undesirable activity.
In plain text for those allergic to scientific abstracts: Based on 2013 study, 0.05% of all Internet Service Providers are responsible for 50% of the trouble. (Some of you'll say 99% of all studies are crap, but this one falls into the 1%.)
How can you detect a "bad neighbourhood"?
Oh, that's easy! Somebody from such a neighbourhood will send you spam. They'll send you links to malware. They port-scan you. They try to guess your passwords in SMTPd, SSHd or whatever their scanning revealed about you.
The theory is: That person "lives" (not necessarily IRL live, but Internet live) near other such criminals and wanna-be-criminals. Such people will find safe harbour within ISPs or hosting providers with lax security and/or low morale. Offenders find other like-minded cohorts and commit their cyber crime from that "neighbourhood".
Ok, I know an IP-address of a spam sender, what next?
Today, most people are using their email from Google or Microsoft or whatever cloud service. Those companies hire smart people to design, develop and run software to attempt to separate bad emails from good emails. Since I run an email server of my own, I have the option (luxury!) of choosing what to accept. One acceptance criteria is the connecting client's IP-address.
Off-topic: Other accepting criteria I have is standards compliance. Any valid email from Google or Microsoft or other cloud service provider will meet bunch of standards, RFCs and de-facto practices. I can easily demand a connecting client to adhere those. A ton of spammers don't care and are surprised that I'll just kick them out for not meeting my criteria. Obviously it won't stop them, but it will keep my mailbox clean.
On a connection to my SMTPd I'll get the connecting client's IP-address. With that I do two things:
- Check if its already blacklisted by spam blockers
- I'm mostly using Zen by Spamhaus. Read https://www.spamhaus.org/zen/ for more.
- Check if its already blacklisted by me based on an earlier spam that passed standards criteria and blacklisting by spam blockers
For a passing spam a manual process is started. From connecting client's IP-address first I'll determine the AS-number (see: Autonomous system (Internet) @ Wikipedia). Second, from the AS-number I'll do a reverse listing of CIDRs covered by that ASN.
Example illustration:
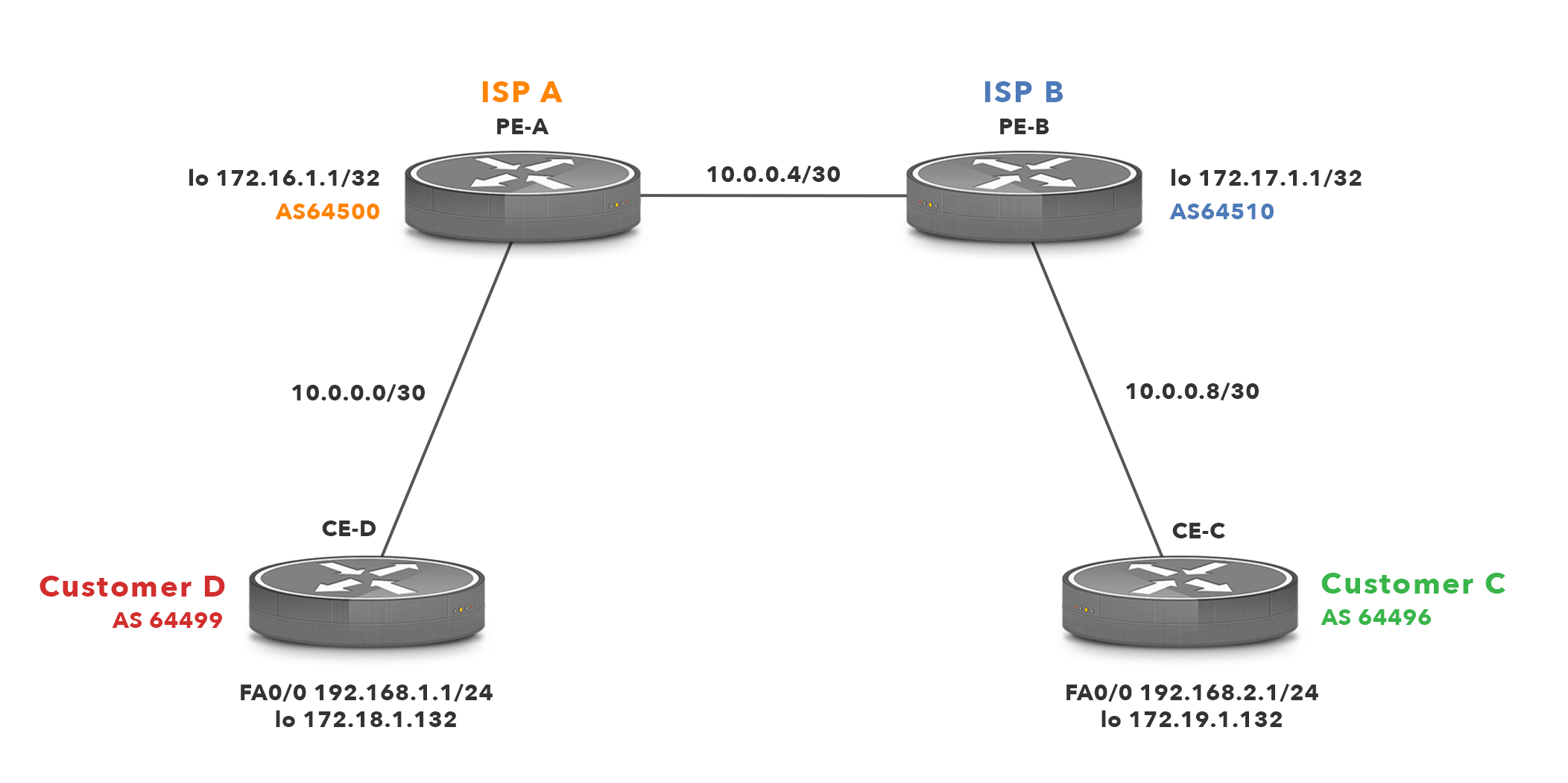
Credit: Above picture is borrowed from https://www.noction.com/knowledge-base/border-gateway-protocol-as-migration.
In the above picture, I'm Customer C on green color. The CIDR assigned to me by my ISP B is 192.168.2.1/24. The spammer attempting to send me mail is at Customer D on red color. As an example, let's assume the sending mail server will have IP-address of 192.168.1.10. Doing an ASN-query with that IPv4 will result in AS 64499. Then I'll do a second ASN-query to query for all the networks assigned for AS 64499. That list will contain one entry: 192.168.1.1/24. Now I can block that entire CIDR as a "bad" one. Effectively I have found one "Internet Bad Neighborhood" to be added into my blocking list. In reality I don't know if all IP-addresses in that network are bad, but I can assume so and won't get punished by doing so.
The only real "punishment" for me is the cardinal sin of assuming. I do assume, that everybody in that neighbourhood are as evil as the one trying to spam me. Unfortunately for the "good ones" in that network, blocking the entire network so is very very effective. The level of trouble originating from that neighbourhood comes down really fast.
Practical approach with Postfix
Doing all the queries and going to different databases manually is obviously tedious, time-consuming and can be easily automated.
A tool I've used, developed an ran for many years is now polished enough and made publicly available: Spammer block or https://github.com/HQJaTu/spammer-block
In the README.md, I describe my Postfix configuration. I do add a file /etc/postfix/client_checks.cidr which I maintain with the list CIDRs of known spammers. The restriction goes into Postfix main.cf like this:
smtpd_client_restrictions =
permit_mynetworks
permit_sasl_authenticated
check_client_access cidr:/etc/postfix/client_checks.cidr
An example output of running ./spammer-block.py -i 185.162.126.236 going into client_checks.cidr would be:
# Confirmed spam from IP: 185.162.126.236
# AS56378 has following nets:
31.133.100.0/24 554 Go away spammer! # O.M.C.
31.133.103.0/24 554 Go away spammer! # O.M.C.
103.89.140.0/24 554 Go away spammer! # Nsof Networks Ltd (NSOFNETWORKSLTD-AP)
162.251.146.0/24 554 Go away spammer! # Cloud Web Manage (CLOUDWEBMANAGE)
185.162.125.0/24 554 Go away spammer! # O.M.C.
185.162.126.0/24 554 Go away spammer! # O.M.C.
That's it. No need to map a CIDR-file. Just remember to reload the postfix after changing the CIDR-list to make sure the new list is in effect of Postfix listener.
Problem with ipwhois-library
This is the reason I didn't publish the Spammer block -project year ago. My Python-tool is using ipwhois-library for the heavy lifting (or querying). It is a well-written handy library doing just the thing I need in this project. However, (yes even this one has a however in it) ipwhois is using RADb (https://www.radb.net/) for source of information. My experience is, that when specifically talking about list of CIDRs contained in an AS-number, RADb is not perfect source of information. To fix this, I wrote an improvement of ipwhois adding ipinfo.io as an alternate ASN data source. A developer can make a choice and use the one source suiting the project.
There is a catch. ipinfo.io doesn't allow free users more than 5 ASN-queries / day / IP-address. By creating an account and paying for their API-usage that limitation can be lifted. Also, their information about CIDRs in AS-number is accurate. This is a prime example why I love having options available.
Unfortunately for me and most users requiring ASN-queries, the author of ipwhois didn't approve my improvement. You may need to install my version from https://github.com/HQJaTu/ipwhois instead. Obviously, this situation is not ideal. Having a single version would be much better for everybody.
Finally
That's it. If you receive spam from unknown source, run the script and add results to your own block-list. Do that couple weeks and your amount of spam will reduce. Drastically!
Beware! Sometimes even Google or Microsoft will send you spam. Don't block reliable providers.
I'm open for any of your comments or suggestions. Please, don't hesitate to send them.
Running PHP from Plesk repo
Sunday, December 8. 2019
In 2013 I packaged PHP versions 5.4, 5.5 and 5.6 into RPMs suitable for installing and running in my Plesk-box. PHP is a programming language, more about that @ https://www.php.net/. Plesk is a web-hosting platform, more about that @ https://www.plesk.com/.
As I chose to distribute my work freely (see announcement https://talk.plesk.com/threads/centos-6-4-php-versions-5-4-and-5-5.294084/), because there wasn't that much innovation there. I just enabled multiple PHP versions to co-exist on a single server as I needed that feature myself. In 2015 Plesk decided to take my freely distributed packages and started distributing them as their own. They didn't even change the names! A sucker move, that.
However, I said it then and will say it now: that's just how open-source works. You take somebody else's hard work, bring something of your own and elevate it to the next level. Nothing wrong with that. However, a simple "Thanks!" would do it for me. Never got one from big greedy corporation.
In this case, the faceless corpo brought in stability, continuity and sustained support. Something I would never even dream of providing. I'm a single man, a hobbyist. What they have is teams of paid professionals. They completed the parts I never needed and fixed the wrinkles I made. Given the high quality of my and their work, ultimately all my boxes have been running PHP from their repo ever since.
This summer, something changed.
My /etc/yum.repos.d/plesk-php.repo had something like this for years:
baseurl=http://autoinstall.plesk.com/PHP_7.2/dist-rpm-CentOS-$releasever-$basearch/
I was stuck at PHP 7.2.19, something that was released in May 2019. Six months had passed and I had no updates. On investigation I bumped into https://docs.plesk.com/release-notes/obsidian/change-log/#php-191126. It states for 26th November 2019 for PHP 7.2.25 to be available for Plesk. That's like a big WHAAAAAAT!
More investigation was needed. I actually got a fresh VM, downloaded Plesk installer and started installing it to get the correct URL for PHP repo. It seems to be:
baseurl=http://autoinstall.plesk.com/PHP73_17/dist-rpm-CentOS-$releasever-$basearch/
Ta-daa! Now I had PHP 7.3.12:
# rpm -q -i plesk-php73-cli
Name : plesk-php73-cli
Epoch : 1
Version : 7.3.12
Release : 1centos.8.191122.1343
Architecture: x86_64
Source RPM : plesk-php73-cli-7.3.12-1centos.8.191122.1343.src.rpm
Build Date : Fri 22 Nov 2019 01:43:45 AM EST
Build Host : bcos8x64.plesk.ru
Packager : Plesk <info@plesk.com>
Vendor : Plesk
Summary : Command-line interface for PHP
Description :
The php-cli package contains the command-line interface
executing PHP scripts, /usr/bin/php, and the CGI interface.
Actually PHP 7.4 is also available, just replace PHP73_17 with PHP74_17, to get the desired version.
PS.
Most of you are super-happy about your Apache/PHP -pair your distro vendor provides. If you're like me and ditched Apache, getting Nginx to run PHP requires some more effort. And if your requirements are to run a newer version of PHP than your vendor can provide, then you really short on options. Getting tailored PHP from Plesk's repo and pairing that with you Nginx takes one stresser out.
Vim's comment line leaking fix! Part 3
Wednesday, June 5. 2019
Bacula 9 vchanger: Tape count fix
Sunday, June 2. 2019
![]()
One of the first ever blog posts I've written here is about Bacula, the open-source backup software (more at https://www.bacula.org/). I published Fedora 17 binaries for the virtual tape changer running for Bacula 7. The post from year 2013 is here.
Running Bacula in Fedora Linux isn't much of a trick, ready-made binaries are available by the distro and configuring one is covered in Bacula's documentation. Then again, running Bacula with a NAS (see Wikipedia for Network-attached storage) as storage backend is where things get very very tricky. I've written about my Qnap NAS-device's support earlier, see the post about that.
Since its inception, Bacula is baked to require a tape drive (or drives) and a set of tapes (a single tape is supported also). Given modern day computing environment, actual physical tapes aren't used that much. Even I stopped using DLT (Wikipedia Digital Linear Tape) or LTO (Wikipedia Linear Tape-Open) tapes years ago and went for an easy, fast and inexpensive solution for storing my backups on a NAS. So, I really do need to have a concept of a "tape" somehow. That's where the virtual Bacula tape changer steps in. It is a piece of software attaching to Bacula autochanger API emulating a virtual "tape" drive and set of tapes with all the necessary operations, but doing all that on a filesystem. More details about autochangers can be found from Bacula Autochanger Resource page.
The obvious idea is to create a set of files to act as a set of "tapes". For system administration purposes, the tapes are just files in a subdirectory. Smart thing to do is to make that particular subdirectory located on a NAS to store the backups where there is plenty of external capacity outside your system. In my case, I'll access them over an iSCSI-mounted filesystem. More details about iSCSI on a Linux can be found from RedHat Enterprise Linux 7 manual pages at https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/storage_administration_guide/online-storage-management#osm-target-setup. For those planning something similar: I chose NOT to go with a NFS. A NFS-connection get stuck very easily and you will be rebooting your stuff a lot. See How-To: Release Stuck NFS Mounts without a Reboot @ Linux Journal for more about that.
When I went to Fedora 29, my Bacula setup got an automatic bump to version 9. My previous setup was for Bacula version 7 and quite soon I realized that I needed to alter my vchanger somehow to get it to support version 9. Bacula-guys did make changes to autochanger-API in their version-bump process. Luckily vchanger author was ahead of me and I got the code from http://sourceforge.net/projects/vchanger/. Soon realized that when I did a simple command of vchanger /etc/qnap.conf LIST, it displayed an extra tape which didn't exist in reality. I was puzzled. Old setup displayed the tape count correctly.
I did some C++ debugging and found out an obvious bug in the code. In src/diskchanger.cpp, DiskChanger-class InitializeVirtSlots()-method calculates the last changer slot numer incorrectly. It is guaranteed to be one-off. After fixing this, I contacted the vchanger author Mr. J. Fisher about my findings, and he agreed, there was a bug in his code.
Unfortunately, couple of months have passed and there is no 1.0.3 release yet, so the fix isn't in the SourceForge git-repo yet. For Fedora-users, my RPMs are available at http://opensource.hqcodeshop.com/Bacula/vchanger for B9/. Go get them there! I've been using those since last December, so I think my fix is correct and doesn't introduce any issues.

