Native IPv6 from Elisa FTTH
Thursday, September 25. 2025
My beloved ISP whom I love to hate has finally ... after all the two decades of waiting ... in Their infinite wisdom ... decided to grant us mere humans, humble payers of their monthly bills a native IPv6.
This is easily a day I thought would never happen. Like ever.
Eight years ago, when I was living in Stockholm, I had proper and good IPv6. There is a blog post of that with title Com Hem offering IPv6 via DHCPv6 to its customers.
By this post, I don't want to judge ongoing work nor say anything negative. This is just a heads-up. Something is about to happen. Everything isn't like it should be, but I have had patience this far. I can wait a bit longer.
Current Status
Here is a list of my observations as of 25th Sep 2025:
- There is no SLAAC yet. Delivery is via DHCPv6.
- One, as in a single, IPv6-address per DHCP-client host ID. I don't know how many addresses would I be able to extract. IPv6 has a "few" of them.
- No Prefix Delegation. 1 IPv6, no more. Not possible to run a LAN at this point.
- No default gateway in the DHCPv6 options. DNS ok. Connectivity to Internet is not there yet.
- No ISP firewall. Example: outgoing SMTP to TCP/25 egresses ok.
- Incoming IPv6 ok.
I'm sure many of these things will change to better and improve even during upcoming weeks and months.
Overcoming the obstacle: Figuring out a default gateway
Oh, did I mention there is no default gateway? That's a blocker!
Good thing is, that there is a gateway and it does route your IPv6-traffic as you'd expect. Getting the address is bit tricky and ISP doesn't announce it. (Credit: mijutu)
Running:
tcpdump -i eth0 -vv 'udp and (port 546 or port 547)'
while flipping the interface down&up will reveal something like this:
21:40:50.541022
IP6 (class 0xc0, hlim 255, next-header UDP (17) payload length: 144)
fe80::12e8:78ff:fe23:5401.dhcpv6-server > my-precious-box.dhcpv6-client:
[udp sum ok] dhcp6 advertise
That long porridge of a line is split up for clarity. The good bit is fe80::12e8:78ff:fe23:5401.dhcpv6-server. Now I have the link-local address of the DHCPv6-server. What would be the odds, it would also route my traffic if asked nicely?
ip -6 route add default via fe80::12e8:78ff:fe23:5401 dev eth0
Testing the Thing
Oh yes! My typical IPv6-test of ping -6 -c 5 ftp.funet.fi will yield:
PING ftp.funet.fi (2001:708:10:8::2) 56 data bytes
64 bytes from ipv6.ftp.funet.fi (2001:708:10:8::2): icmp_seq=1 ttl=60 time=5.42 ms
64 bytes from ipv6.ftp.funet.fi (2001:708:10:8::2): icmp_seq=2 ttl=60 time=5.34 ms
64 bytes from ipv6.ftp.funet.fi (2001:708:10:8::2): icmp_seq=3 ttl=60 time=5.29 ms
64 bytes from ipv6.ftp.funet.fi (2001:708:10:8::2): icmp_seq=4 ttl=60 time=5.31 ms
64 bytes from ipv6.ftp.funet.fi (2001:708:10:8::2): icmp_seq=5 ttl=60 time=5.39 ms
Outgoing SSH/HTTP/whatever works ok. Incoming SSH and HTTPS work ok. Everything works! Test-ipv6.com result:
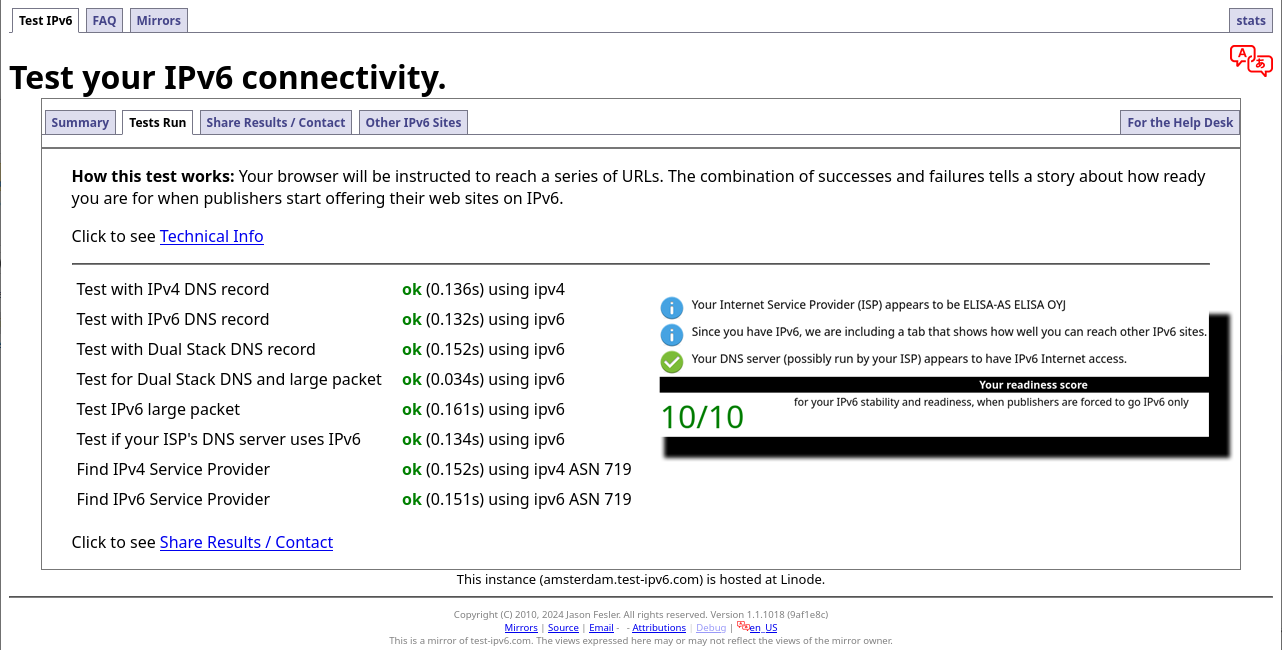
Cloudflare Speedtest result:
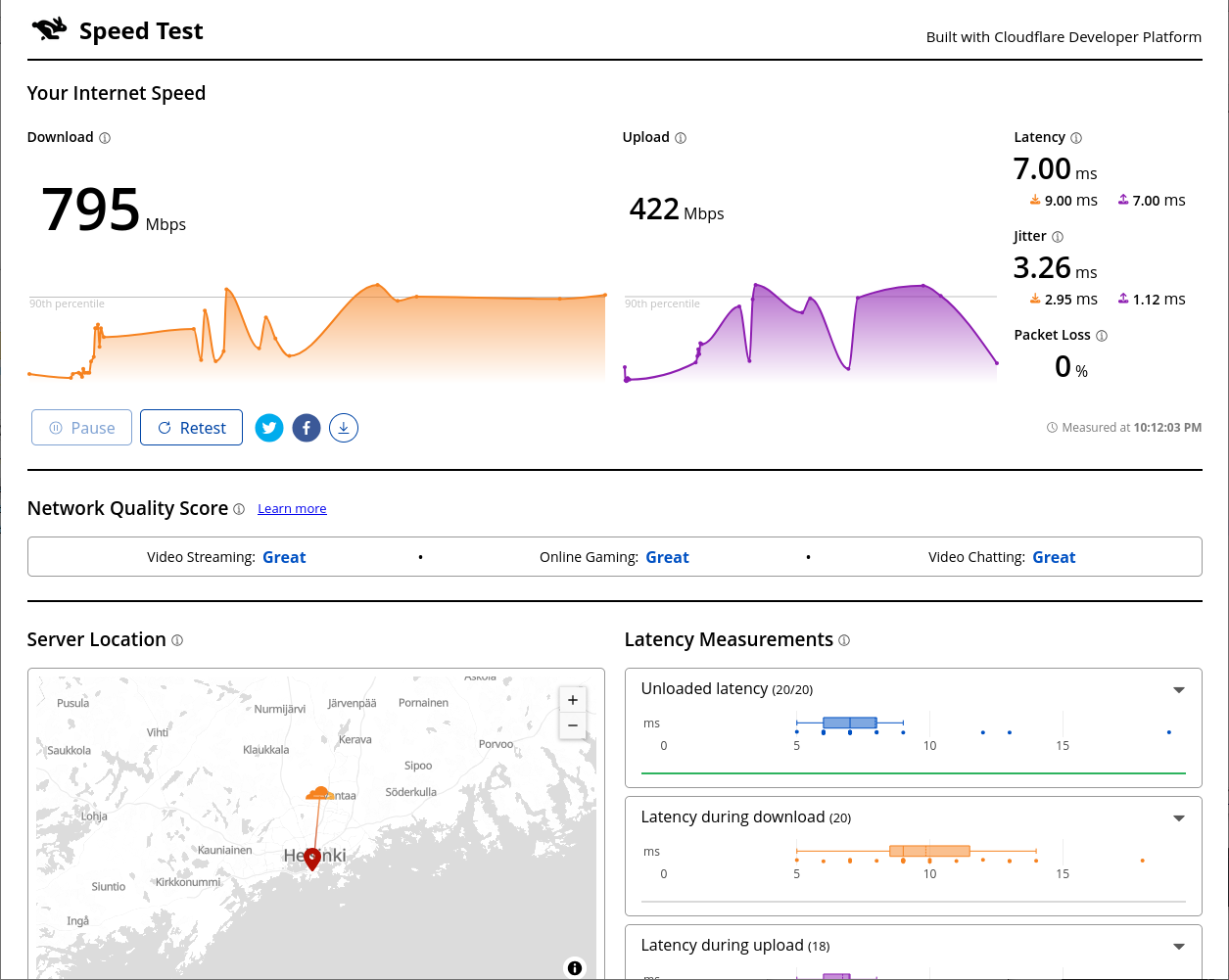
This is very flaky. I ran it from Linux console over X11.
Also, the typical Speedtest.net, which I'd typically run, won't support IPv6 at all.
Finally
I'm so excited! I can not wait for Elisa's project to complete
Signal - Linked Devices
Monday, March 17. 2025
For messaging, there are plenty of choices. I must admit, my thinking is similar to criminals: the less any government knows about me and my messaging, the better. Today, full anonymity is gone. Really, really bad actors were staying below law enforcement radar, and now those really good ones for messaging are gone.
So, I'm doing what Mr. Snowden does and am using Signal daily.
![]()
For governments to keep track on me, Signal works via phone number. My issue with using a phone number as identifying factor is, in any country, there are "like five" different phone numbers (in reality an area code has roughly 10 million different numbers).
As you must feel confused, let me clarify. The reason, I say "5" is because when numbering scheme was designed, 10 million amounted roughtly to infinite. Today, anybody can dial 1000 numbers per second and exhaust the entire number space in less than three hours. Obviously, there are multiple area codes and prefixes, so we have multiple sets of 10 million numbers. So, it would take a day to dial all possible numbers. With single computer. What if somebody could obtain two computers? Or three?
Let's face it phone number as a technical invention has been obsoleted for years. It should NOT be used to identify me in any messaging app. It's convenient to do so. Governments have been tracking phones for many decades and they can demand messaging protocol operators to enforce phone identification. Still, by any measure Signal is the safest option.
Moving on. Phone numbers: bad. Signal: good.
This is what happened the other day:
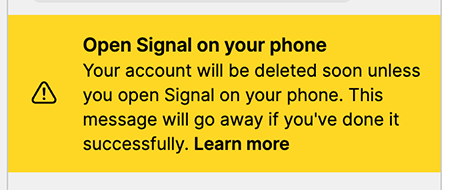
The text said:
Open Signal on your phone
Your account will be deleted soon unless you open Signal on your phone.
This message will go away if you're done it successfully.
For the past two years, I've never used Signal on a mobile device. To me typing messages with a non-keyboard is madness! So, I'm just using messaging from my computer(s).
It seems there is a limit to it.
Government wants to track you, so you must verify the existence of your phone number for every 2 years. Fair.
Old Computers and Hardware @ Museum of Technology, Finland
Friday, January 10. 2025
For a couple months, there is an exhibition of "operators and automated data processing designers" in Museum of Technology.
I visited the exhibit as tons of old hardware was shipped from Computer Museum of Finland, Jyväskylä. As there were so many interesting pieces of hardware, I'm presenting a few pictures here. On any typical blog post, I'd blanket my text with links. Here, on purpose, I'm omitting them. "Do your own research" as conspiracy lunatics say!
Funet Cisco AGS+

Back in the day, in 1988, when you visited ftp.funet.fi, your traffic when through this exact router. It was the first ever router manufactured by Cisco Systems.
Psion Revo

I owned one. It was a magnificant piece of pocket-size computing power! As a minus, any kind of transfer required the thing to be plugged into a PC. This minor drawback didn't slow me. Neither did the black&white screen.
Later Nokia purchased Epoc and made it Symbian.
Nokia Communicator 9210

While this wasn't the first ever communicator by Nokia, it was the best one. Proper screen, good keyboard, Symbian 5, ah.
Back-in-the-days, I was poached to a company to write Symbian C++ code for this device. Fun times!
IBM PC

As in - the first one. Ever! From 1981.
For this invention everybody on this globe owes a lot. If IBM had kept the system closed, there wouldn't be no ecosystem for hardware manufacturers nor software crafters. This ecosystem made all the next rounds of evolution possible landing us where we are today.
Ancient: IBM 3380 HDD

Moving to antics. Back in 60s this refridgerator-sized thing was one of the early HDDs invented by IBM. Capacity was 2,5 gigabytes. During that era RAM was in kilobytes, floppy disks barely reached megabyte.
Ancient: PDP-11

This DEC thing pre-dates me. Those things from 60s were so rare, I'm sure not many ever landed shores of Finland. The screen size is something from 2020s. However, the display is 1m x 1m x 1m and has to weigh a ton!
Ancient: DEC VT102 Terminal for the PDP-11

When you open a "terminal" in OS of your choice, it's a software version of that. Funny thing is, VT102 is still a common terminal type to emulate.
Ancient: IBM System/360 Control Panel

Your Windows 7 had a Control Panel. This is the same thing, but for IBM S/360. That's how you'd manage your computer's settings back in the 60s.
eSports - Superfest 2024
Monday, November 4. 2024
![]() Last weekend, I had the chance of visiting Superfest 2024. It's an eSports event organized by Supercell. Championship of three games were played:
Last weekend, I had the chance of visiting Superfest 2024. It's an eSports event organized by Supercell. Championship of three games were played:
- Clash of Clans World Championship Finals
- Clash Royale Leagure World Finals
- Brawl Stars World Finals
When entering the event, lounge:

Sunday finals schedule poster:

Saturday game of Clash of Clans. STMN players Darkstar, Fluxxy, Ninj, Synthé and VAD Hawk playing against Millesime MG players KingsMan, Natchoa, Teemper, TryHard and Max:


Sunday game of Clash Royale from lounge, two players from SKCalalas Sub vs Ryley. Ryley became 2nd:

Brawl Stars champions HMBLE players Symantec, BosS and Lukii after their victory:

Well organized event. I wish I would have understood the games bit better. Those games are pretty unknown to me.
Still: GG!
Azure and Friends Tampere #T07
Friday, October 18. 2024
My employer opted to host a meetup. As they needed somebody to give a presentation there, obviously, I stepped up.

Thanks for all the participants!
For those interested, my presentation on Microsoft Fabric Real-Time Intelligence.
On Technology Advancement - Does anybody really use generative AI?
Monday, June 17. 2024
According to this, not.
(Ref.: What does the public in six countries think of generative AI in news? survey)
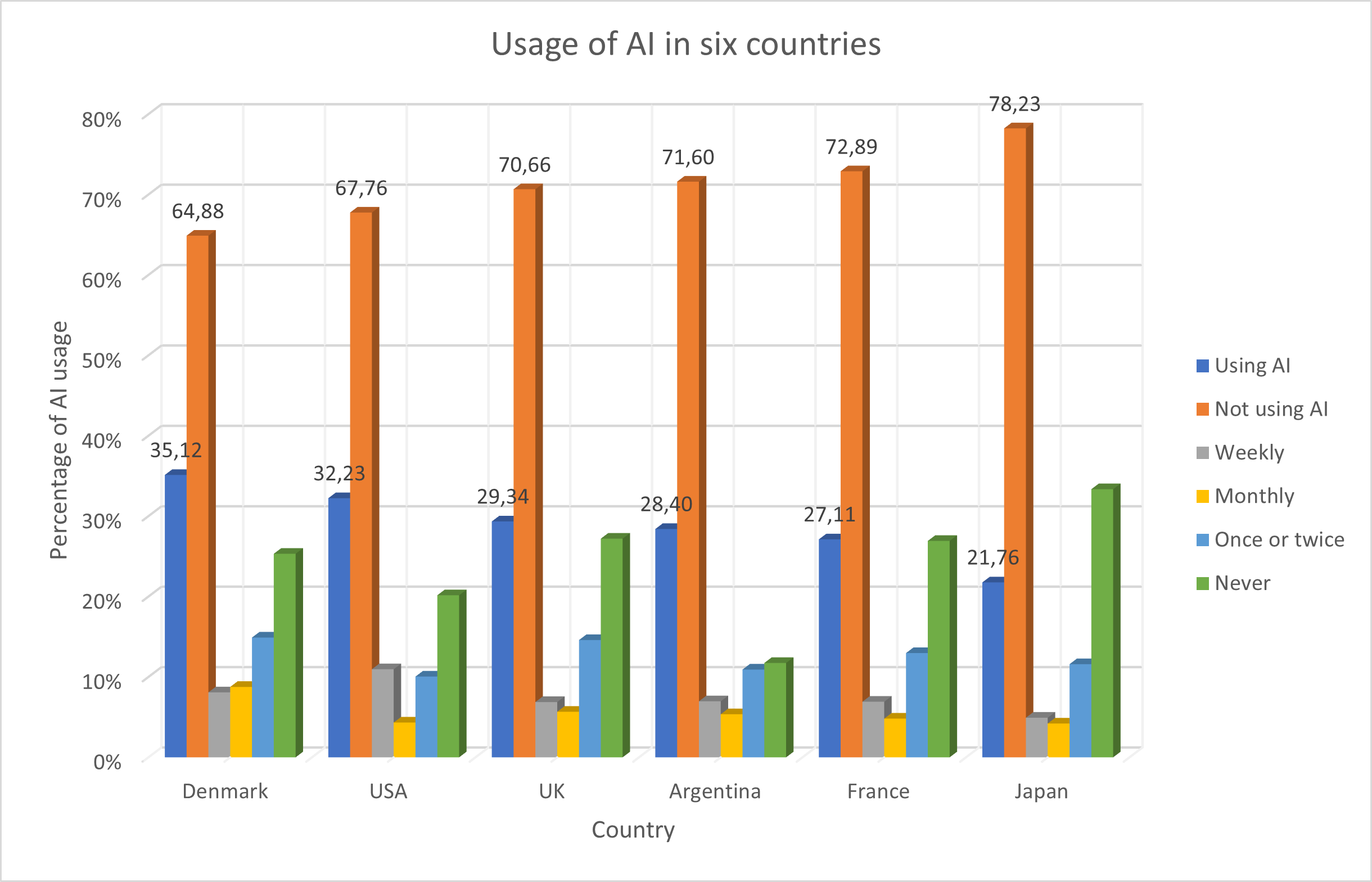
AI is still in its infancy. Those who lived the IT-bubble of 2000 can relate.

British newspaper Daily Mail wrote in its December 5th 2000 issue about Internet. At that point, it was obvious: Internet wasn't a passing fad. Publishing that article back in -95 might have been sane. Just before the bubble was about to burst, not so much.
Let's dig up more examples. When we're faced with technology leap, our reactions can be surprising.

On hindsight (that's always 20/20), it would have made sense to see the vastly improved user experience on communications. Spoken word versus written word isn't a fair fight. Spoken word wins when communication target is time-sensitive and message is brief. Today, most of use don't use our pocket computers for phoning, we use them for writing and reading messages.
How about transportation?
If I had asked people what they wanted, they would have said faster horses.
A phrase Henry Ford did not say. There is a Harvard Business Review story about this.
Not that the line makes sense in any case.
Because “faster” wasn’t the selling point of cars over horses.
Speed wasn’t the problem.
Spending huge amounts of money, time, and space on keeping horses alive and dealing with the literal horse shit was the problem.
So, yes. We will use AI. We are already using AI. It's just like with Internet, telephone or cars. We're learning how to use them. Gartner seems to place generative AI on top of their Hype Cycle for Emerging Technologies 2023:
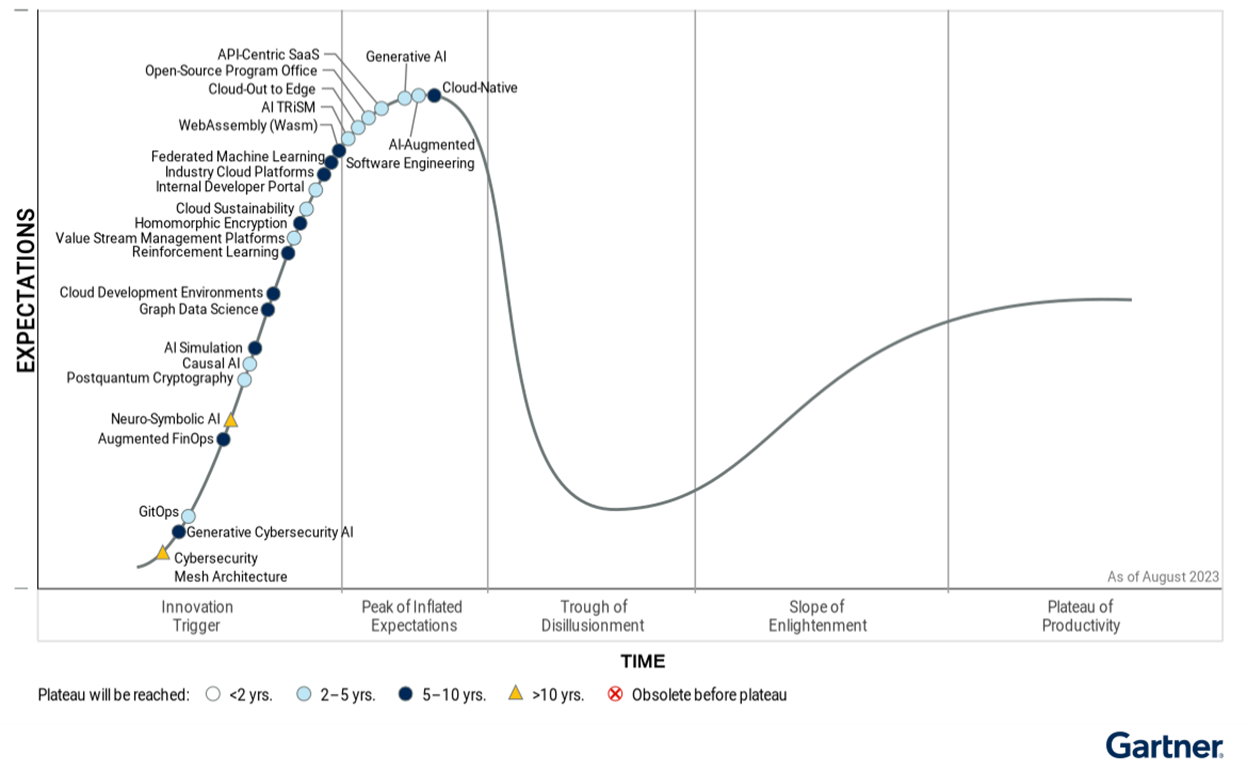
That translates into falling flat with most ridiculous use-cases of AI and sane ones remaining. Before that happens I'll keep using AI, chuckling when it makes a silly mistake and nodding in acceptance when it speeds up my task-at-hand.
Satellite Internet — Past & Present
Saturday, March 4. 2023
About satellites
ESA has a really good information package Space Transportation - Types of orbits.
When context is satellite Internet, there are pretty much three options: LEO, MEO or GEO. As satellites fly high, latency from Earth's surface to satellite and back is a factor. Low Earth Orbit is the most common choice, altough the lower you fly, the more satellites are required for reasonable coverage.
Past
Inspiration for this blog post came from my 1998 LUT course presentation of Satellite Internet. 25 years ago IT-bubble was still growing and it was about two years before it bursted. As I was a telecommunications major, I took a seminar course which contained a presentation. From the list of topics available, apparently I chose satellite Internet. Back in those days getting the bandwidth delivered to everybody was in rapid growth. Mobile Internet was mostly non-existent, fiber-to-the-home was non-existent, dial-up model, ADSL or cable-TV internet were the methods for getting to The Net.
Here is my PDF presentation about satellite networks Iridium, Globalstar and Teledesic (in Finnish):

This past can be considered as Round #1 of satellite internet.
Retrospective: Iridium
Went into production. 2nd generation begun deploying in 2017. Not generally known, nor common. Originally, not financially viable.
Retrospective: Globalstar
https://www.globalstar.com/, LEO
Went into production. 2013 2nd generation, 2018 3rd generation announcement. Apple iPhone 14 emergency messages are using 2nd gen Globalstar. Not generally known, nor common. Originally, not financially viable.
Retrospective: Teledesic
Never saw production. Project suspended 2002 as IT-bubble bursted and saw financial problems of Iridium and Globalstar. Completely vaporware and nobody knows this ever existed. Plan was to have hundreds of LEO satellites for really fast Internet connectivity.
I have to mention their tech. Instead of traditional approach all others have, relying on ground station being able to find a passing satellite, Teledesic originally planned having 840 satellites. As it was extremely expensive, they later reduced the number to 288. Their idea was to map Earth into regions and having enough capacity, multiple satellites were available at one "square" at a time to provide massive speeds. In theory, really good idea!
Other services
My presentation contained only three companies/services as the topic given to me dictates. At the time, other satellite services did exist.
Still today, Inmarsat Broadband is well known for its voice capabilities and mobile units made famous in popular culture. They do support broadband connection in their GEO satellites. This Satphone 2 is a well-known product:

Another not well-known service is ORBCOMM, an IoT service provider. As their service is targeted to hardware manufacturers, not consumers, nobody has not ever heard of this one. Their 50+ satellites are LEO.
Present
Fast-forward to today.
Obviously Iridium, Globalstar, Inmarsat and ORBCOMM do still exist. As there are some changes in service offering for the past 25 years, let's do a recap of the new players.
SpaceX Starlink
https://www.starlink.com/, very low LEO
Mr. Musk and his Starlink is getting tons of media attention, especially for his donation of terminals to Ukraine to help them in war against Russia. This well-known service is farthest from vaporware, is affordable and easily available. Broadband speed is reasonable, see Ookla Speedtest results comparison.
Notable fact about Starlink is, they are the only satellite broadband provider so far to have their own vehicle for orbiting their own satellites. This capability will give them much required longevity. Satellite Internet is not a sprint, after all.
HughesNet / EchoStar
https://www.hughesnet.com/, GEO
Originally Hughes Communications was owned by Hughes Aircraft, the company founded by Howard Hughes. They are a major service provider in Americas. Here in Europe, they're not well known.
Viasat
https://www.viasat.com/space-innovation/satellite-fleet/viasat-3/, GEO
This is an upcoming broadband service. Viasat is a known satellite-TV operator expanding its services to Internet.
Amazon / Project Kuiper
Obviously Mr. Bezos want's to compete against his nemesis, Mr. Musk and launch his own satellite Internet. His project is the most recent one and really doesn't even have a proper website.
Boeing
LEO
The legendary aircraft manufacturer wants their share of satellite Internet business. This very recent project has FCC approval for 147 satellites, but not much is known about the project.
Future?
As we learned back in 2002 when Teledesic folded, there isn't room for all above players. Some of them will fold and/or merge. Especially SpaceX is gaining lot of customers in rural areas with their modern service offering. Having a fierce battle-of-pricing won't be happening. Launching those satellites is v e r y expensive. Lacking financial stability, not everybody will survive in this Round #2.
There is plenty of space in the sky. It is already crowded and traffic jam is likely to get worse as more and more satellites are launched. Just take a look at Wikipedia's Satellites orbiting Earth -article.
Nokia 5.3 de-bricking after reset
Friday, March 3. 2023
Given the vast differences between Apple's iOS and Google's Android platforms, I own, run and operate both. For those interested: Apple I have as my daily mobile, Android, the more popular platform, I use for more experimental features which are not available on the other one. These features include: access to mobile radios, access to NFC and Bluetooth.
Nokia (or HMD Global to be precise) is a really good Android mobile manufacturer. Generally speasking, they don't bloat their firmware with mandatory always forced-on Facebook or any such crap. Also, my years old 5.3 got Android 12 update. Obviously, this was nice as most manufacturers sell you forgetware getting no updates, but ... (there is always a but-part). What typically happens with electronics, is the hardware becomes obsolete faster than consumer would like to. This puppy doesn't pack the oomph in it's Snapdragon CPU to fluently run Android 12. I had no problems with Androids 10 or 11, with 12 everything started feeling too sluggish. To shopping I went. I came back with a Nokia G21.
Resetting an Android
Onboarding new phone was almost painless. Most icons on my start screen were lost, apps were loaded from Play, icons not so much. Such a thing is easy to fix, so I made the call to do a full reset to the old mobile. That is the standard procedure when you're about to donate/sell/hand out your old computing hardware.
Aftermath – Reset bricked my Nokia!
Crap! The thing failed to boot after reset.
What! What? How is this possible?
Yes, I wasn't alone. Nokia Community forum has following post: WARNING - Do NOT factory reset Nokia 5.3 -- Bricked phone. Factory resetting stuff is such a basic operation done commonly, I didn't much do any research for it. On hindsight (it is 20-20 always) I should have done some.
De-brick
On above thread Mr. Adam Howard faced the same situation and presented a solution.
Prerequisites
Following is needed:
- A computer capable of running Android SDK.
- I used macOS, no drivers or such needed
- I know Linux will work fine, my understanding is no drivers are needed there either
- Windows is known to work, but will require device driver for Android. Which one? No idea here.
- Enough permissions and skills to run Android tools on your computer.
- USB-C cable to connect Android to your computer
- Make sure the device is unconnected, it will be connected later
- Android SDK Platform Tools
- Available @ https://developer.android.com/studio/releases/platform-tools
- Install and test run Android Remote Debugger
adb
- Nokia 5.3 Android 12 firmware
- Available @ https://android.googleapis.com/packages/ota-api/package/d50cb0137919fd20d43cb67a7cb47a073966269d.zip
- Do NOT unzip! Package is needed by
adbin zipped form.
- That's it! Time and your favorite beverages (don't spill, electronics and liquids won't match).
Hard reset / Recovery mode
Apparently you can manually reset any Nokia 5.3 enough to force it into a mode suitable for force installing a new firmware. In this situation, obviously very helpful for recovery purposes. Scary as hell if you have a habit of losing your mobile to dishonest people. They can do nasty stuff to your mobile.
Instructions are here: HardReset.info: How to put NOKIA 5.3 in recovery mode?
Here is the sequence:
- Power off device
- Power on. This is your typical turn-it-on -sequence. Press power-button for ~4 seconds.
- This is your typical turn-it-on -sequence. Release power button.
- Press and hold: power button & volume down.
- Keep pressing the buttons until recovery screen appears: "START"
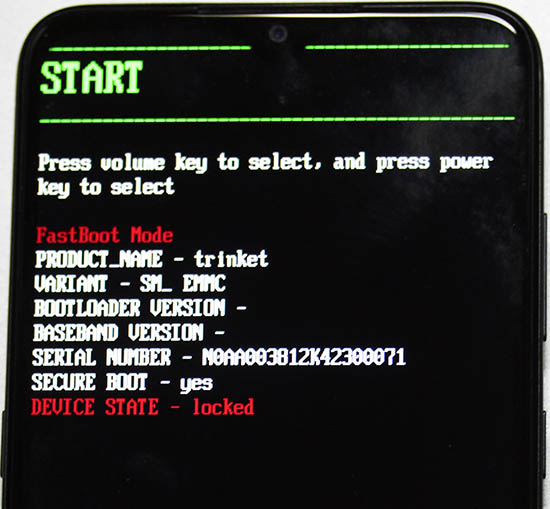
- Tap volume down 2 times: "Recovery mode"
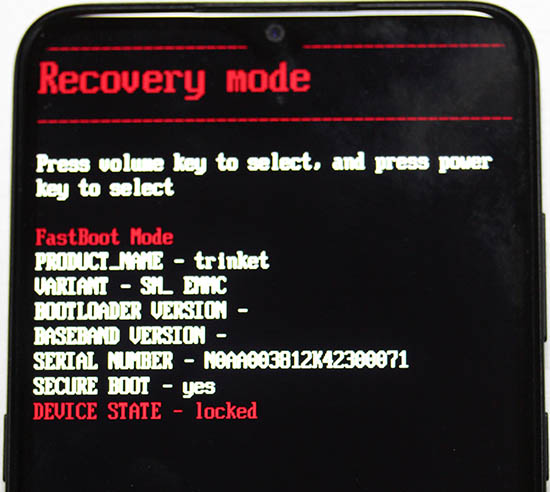
- Press power button to select Recovery mode
- Device will restart.
- Wait for Android with side open to appear. Note: there are no options in this screen.

- Press and release: power button & volume up.
- Android Recovery menu will appear
- Tap volume down 3 times, "Apply update from ADB"
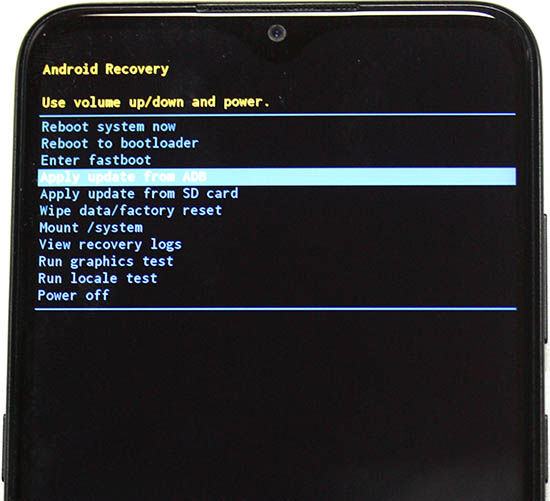
- Connect cable
- Press power button to select Apply update from ADB
- Leave you mobile be, next operation will be done on your computer.
On your computer: Upload firmware
Here is the sequence:
- Requirement: Your mobile must be waiting for firmware to be uploaded
- Info: Android Platform Tools (directory
platform-tools) will contain utilityadb - Info: You will be using sideload-function of
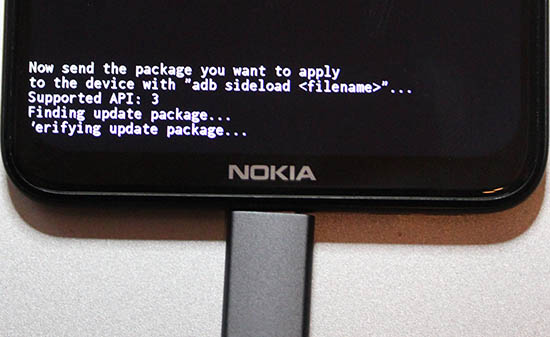
adb. Info @ Sideload ROMs and Mods Using ADB Sideload - Run adb and point it to downloaded firmware, adapt your filename:
adb sideload ../Nokia\ 5.3\ firmware.zip - On your mobile following will happen:
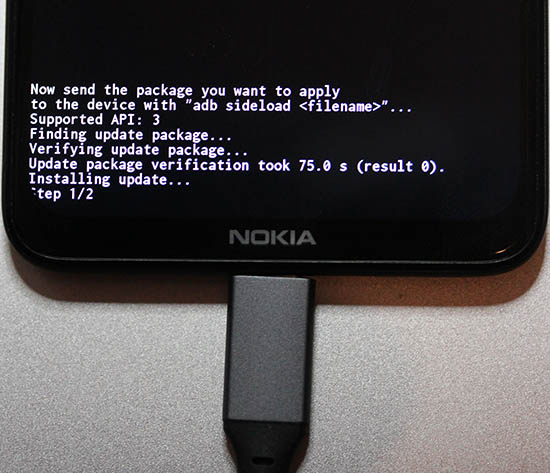
- As time passes, progress will be updated:
- Firmware update done
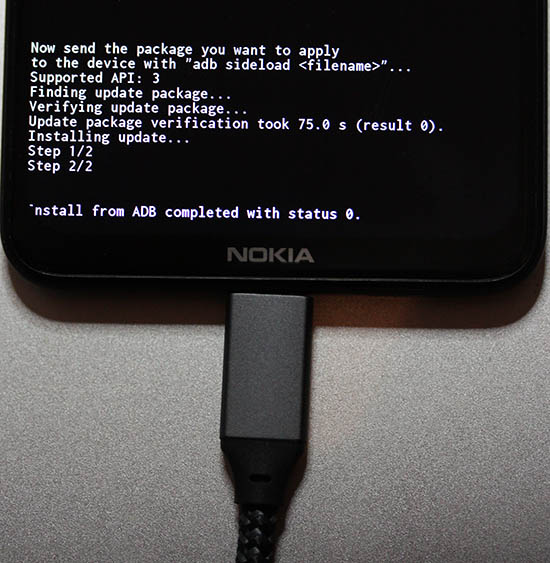
- That's it!
Done
Observe out-of-box -experience on your mobile:
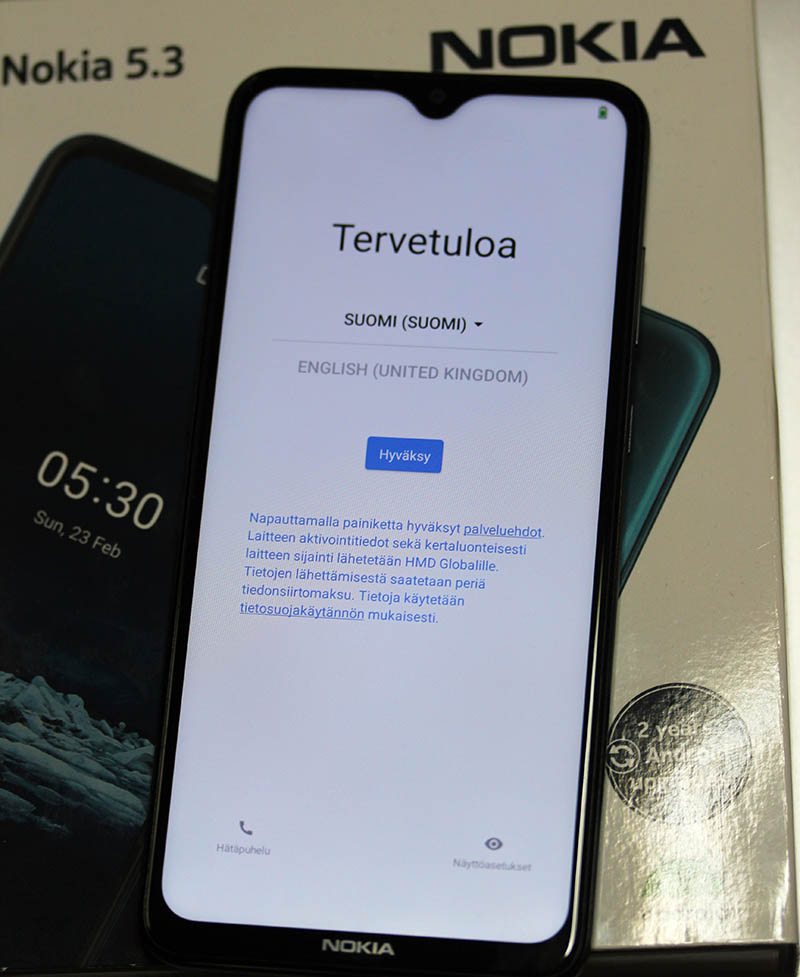
This is a major blooper by HMD guys. The community forum is full of angry people who bricked their 5.3 with Android 12.
Monitor Arm installation
Sunday, November 20. 2022
This is one of my computing setups at home office:

This one has a MacBook Pro 16" at desk and some extra display real estate on top of it. It's a Samsung 4K screen. As there are other computers on this desk, this display has no room anywhere else and it has to go high.
An open lid of this MBP will take ~24 cm in height. On this particular Samsung, there is couple centimeters of frame. For the display area to start at 24 cm, bottom of screen has to be at ~22 cm. Like this:

Most inexpensive no-brand solutions (like my previous one) at their arm can go up to to 50 cm. Then at the end of arm, there is the VESA mount, which will be attached to back of the monitor. Like this:

Again, on this particular Samsung the VESA D-mount is a 75x75 mm and it is located at nearly at the top of the screen making the bottom go low. Most displays have a 100x100 and the VESA-mount is typically at center of the thing. Looking at the picture, notice how commonly sold monitor arms have both 100x100 and 75x75 end. This Samsung has a really beautiful round space for all connectors and VESA-mount (invisible to user at the back of the thing). Nobody at Samsung thought how a bigger 100x100 mount would fit inside this obviously-too-small-ring. I couldn't use the regular M4 screws and had to use extra long ones.
Here is a picture of the problem with this Samsung's let's-place-the-mount-at-top -design:

When I go to max height of 50 cm on my arm, I'm missing ~3 cm at the bottom. Monitor is only at 19, but need to be at 22 for the MBP's lid to not obstruct anything at the 4K display. Crap! My old arm clearly has grown too small. There is an illustration of the problem:

Should my MBP be a 13" model or Samsung have its mount in a more reasonable location, this old monitor arm would do it for me. To monitor arm shopping, then. This is the one I got:

It's a Kensington SmartFit® One-Touch Height Adjustable Single Monitor Arm. This more expensive baby can go the required height and much more! Problem solved by throwing money at it.
State of Ubisoft in 2022
Sunday, September 18. 2022
Hetzner outgoing mail - SMTP blocked on TCP/25
Sunday, August 28. 2022
For ages spammers' tactic has been to use either free trial of a service or payment via "liberated" credit card. As public cloud service providers want to lure in new customers, there is a habit of offering non-paid services for a period of time. All major providers like AWS, Azure and Google Cloud Platform have such free-of-charge use available.
Also smaller companies have such offering. Smaller companies (are still quite big, but not as big as biggest ones) would include Hetzner and OVHcloud. Both have number of data centers around the Europe and for any postmaster, are a royal pain in the ass. You can get a really cheap VM on either and start spewing spam email into unsuspecting SMTP-servers, like the one I maintain.
This type of free-spam-for-all isn't sustainable, or hasn't been for years, but these companies still allow it to happen. In 2021 Hetzner made a change for better. Lot wasn't communicated, however, this information was published to its customers:
Microsoft Blacklist
Microsoft maintains their own internal blacklists, which are used to reject emails coming from specific IP addresses.
Note: Entire info is available @ Hetzner website.
As a customer of Hetzner having an operational VM, I bumped into a new undocumented restriction applied to new accounts. On my own box, everything still works as usual. Has been for years. To my surprise, outgoing TCP/25 on a new account having a new VM is blocked. What!? Investigating this, led me to Hetzner customer support site, as it has following options for support request:
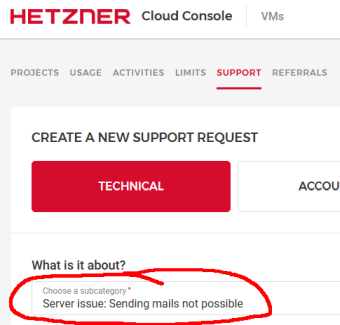
There is a drop-list with different types of problems having a specific category of Sending mails not possible. Apparently somebody designed the support pipeline for that particular need.
Lack of official documentation made me look in The Net. There I found a confirmation of this policy change. In June 2021 Bjørn Erling Fløtten of Norway wrote in his blog post Ditching Windows and AWS, diving into Linux and Hetzner following story:
Step 8: Setting up an email server
...
(This reminds me of the good old days when a mail server by default usually would be an open relay. Now you definitely get a more secure basic install)
Now I could actually also telnet to port 25 from my Amazon instance, and the connection appeared in the Postfix log. I have no clue why it did not work on the first attempt.
Time to ask Hetzner to open port 25 outbound (SMTP port).
(There is no mentioning of port 25 blocking anywhere on Hetzner's pages. But it is of course natural to assume that port 25 is blocked, even though the firewall administration page of Hetzner's Cloud Console says "All outbound traffic is allowed. Add a rule to restrict outbound traffic.").
So I decided to open a Support ticket, which suggest:
"Server issue"
and
"Server issue: Sending mails not possible"
Choosing the latter gives this:
"Outgoing traffic to ports 25 and 465 are blocked by default on all Cloud Servers.
A request for unblocking these ports and enabling the send mail option is only possible after the first paid invoice."Fair enough, some thrust needs to be established.
Invoice information says:
"Invoice information
You currently receive 1 invoice a month.
The invoice will be created on the following day:
...th of the month"...
Bjørn: Hint! Get a free-of-charge TLS-certificate somewhere. Most browsers refuse to enter your site. Thanks, though, for sharing your experience. Now I know to first wait for the invoice and then request for the ports to be opened.
Hetzner: Hint! Would it be smart to document all of this somewhere? Thanks for this change in your policy, though. Anybody needing SMTP will eventually get access. Deactivating option to spam at will makes life of criminals looking for the-easy-way look for other alternatives. This new policy leaves plenty of details about perpetrator's identity for police to investigate.
Update 19th Sep 2022:
Hetzners rules are both of these need to be true:
- First invoice must be paid
- Account must be at least month old
By paying, your SMTP-ports won't open. They open only after bit of a wait.
eSIM in iPhone
Friday, July 29. 2022
For vacation / touristing purposes, I did some travel. When leaving the comfort of EU/ETA-region cell phone mobile data changes into something tricky. Most telcos here in Finland offer you 15 GiB of roaming transfer per month inside EU/ETA. As I travelled into post-brexit UK, the gravity of current roaming agreements hit me. For those unaware (like me on London Heathrow airport): nothing works and if works, expect to pay per-GiB on gold bullions.
At hotel, free Wi-Fi was more than welcome addition to their service offering. With that I was able to figure out what the heck happened to my iPhone data and what measures could I take to enable it.
After weighing all the options, my solution was to purchase an eSIM. That's something I never even considered before. Being in "the spot" I just went for Holafly eSIM. I'm 99,9% sure their offering is not the best nor cheapest, their product simply was easily available. Their marketing must be superb!
List of options considered, but abandoned for different reasons included following:
- Not having data in my phone.
- Relying on public Wi-Fis. They were generally available in many sights and locations.
- Enabling non-EU/ETA data roaming on my subscription.
- Purchasing a prepaid SIM from nearby groceries store. They were generally available, not too expensive and easy to obtain.
This is what I paid with a credit card:

$19 USD. Living in Finland, the country most of the mobile stuff was invented at, the price for unlimited 5 day data was horrible. This is what Holafly delivered me via email:

A QR-code! What! Are eSIMs distributed as QR-codes? Really?
More googling revealed: yes, that's correct. An eSIM is essentially a QR-code.
Payload of above matrix barcode would be as follows:
LPA:1$h3a.prod.ondemandconnectivity.com$8083B8A60025B1BA0E92A460388592035501C61BB74516AB176BA714D64AD60B
Studying the topic more with eSIM Whitepaper - The what and how of Remote SIM Provisioning and How Does an eSIM Work? Acronym LPA from the QR-code stands for Local Profile Assistant. Most stuff encoded into a QR-code I've ever seen has some sort of classifier as the initial value, so having something there would be expected. Next section with $-signs contain a hostname to contact followed by a password to provide for a server answering to requests on mentioned hostname to issue details of my newly purchased subscription for my phone. Host h3a.prod.ondemandconnectivity.com translates into 91.240.72.102, property of Thales group.
After walking through iPhone new data profile wizard, this is what I ended up with:
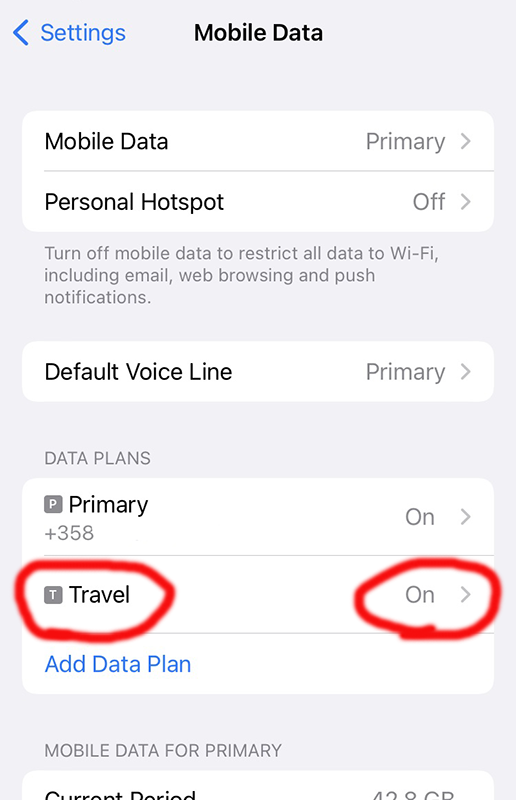
For unknown reason, the name of my eSIM was "Travel". That's something that can be chosen and renamed, even. Taking a look into the settings of my Travel-profile reveals following:
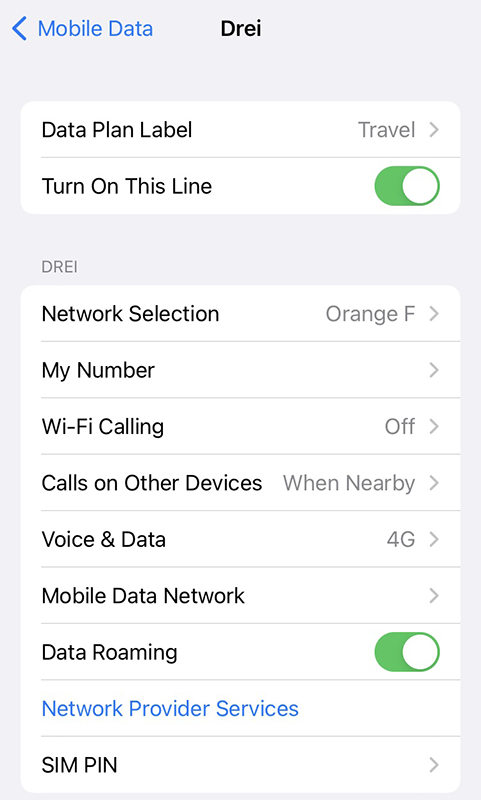
Whoo! That's an Austrian telco 3 subscription. The name "Drei" is German and means three (3). There are number of subsidiaries on 3 or Hutchison 3G Enterprises S.A.R.L., in case you are unaware of such telco group.
Now that I had mobile data, the obvious first thing was to verify where my Internet exit-node was located at. It seemed, my IPv4-range 91.223.100.0/26 was operated by Nexthop AS from Norway. A closer look on their geo-feed at https://geofeed.wgtwo.com/geofeed.csv revealed two network ranges of /26 or 62 available addresses:
# prefix,country_code,region_code,city,postal
91.223.100.0/26,GB,ENG,London,EC2V
91.209.212.0/26,GB,ENG,London,EC2V
Ultimately I was happy. Everything worked well, my iPhone had data connection for maps, googling, mail and iMessage.
To summarize:
- My iPhone is designed in California, USA and manufactured in China.
- I purchased an eSIM from Holafly, a Spanish company.
- I paid US dollars for the product on their website located in an UK server.
- What I got delivered from the purchase was credentials to connect to a French server.
- Response payload of from the French server was an Austrian mobile data subscription.
- Subscription's public Internet exit was located at United Kingdom, operated by a Norwegian company.
That's what I call an international operation! 
PS. If you can hack the above eSIM to work for you, please inform me. It's a pre-paid, so I won't be the one taking the loss.
123RF Leak - Fallout
Sunday, July 3. 2022
Your and my data is leaked left and right all the time by organizations who at the time of you entering your precious PII (or Personally Identifiable Information) solemny swear to take really good care of it. Still they fail at it. By adapting the famous speech by John F. Kennedy: "Not because it is easy, but because it is hard." Even companies whose business is information security get hacked, or mis-configure their systems or human administrators fail at a minor thing causing major disasters, causing data to leak. Because it is very very hard to protect your data. Let alone companies whose business is not information security, they simply want to conduct their business on-line and not to focus in nurturing YOUR information. When a flaw in their system or procedures is found by malicious actors, data will be leaked.
I don't think this is about to change anytime soon. Unfortunately.
Back in 2020, a site called 123RF.com was pwned. How, or by whom is irrelevant. They failed protecting MY data. More details are available in Bleeping Computer article Popular stock photo service hit by data breach, 8.3M records for sale.
As anybody can expect, there are negative effects on such leaks. Today, such negativity manifests itself in my mailbox as follows:
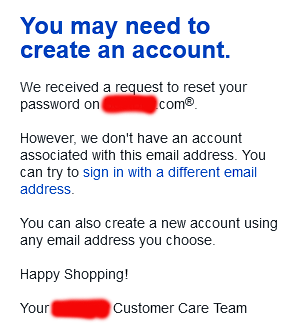
A company, who has nothing to do with me is sending email to my unique 123RF-dedicated address, stating my attempt to request password recovery on their on-line service has failed. Ok, intersting. Not cool.  However inconvenient this is to me, I fail to find the attacker's angle on this. By sending 8.3 million password recovery attempts to a public endpoint is a far fetch. They might by shear luck get access to somebody's account on the targeted site. Most likely not. But it's worth the try as it won't cost them anything and very easy to do.
However inconvenient this is to me, I fail to find the attacker's angle on this. By sending 8.3 million password recovery attempts to a public endpoint is a far fetch. They might by shear luck get access to somebody's account on the targeted site. Most likely not. But it's worth the try as it won't cost them anything and very easy to do.
This exact same has happened to me multiple times. An example from 2018 is my blog post DocuSign hacked: Fallout of leaked E-mail addresses. Given all the time and effort I put into creating mail system where I can have unique addresses to all possible use-cases it will be easy to identify the leaking source. Me and many others thought EU's GDPR was supposed to help every single Internet user with this, but still Wired is writing in their May 2022 article How GDPR Is Failing (sorry about the paywall, I'm a subscriber).
I'd like to end this by expressing my generic despair and agony not targeted towards anybody in particular while still targeted towards all stakeholders. It's a movie quote from the original -68 Planet of the Apes where at the end of the film Charlton Heston's character understands what had happened and how he ended up in that mess:
Ah, damn you! God damn you all to hell!
FTC-case: Cafepress leak
Thursday, June 30. 2022
Couple days ago I got an email to a really old address of mine. I happen to own number of domains and most of them are connected to the mail system on my home Linux server. Many many years ago I stopped using a single email address for the simple reason that I couldn't identify to whom I had given that address to. This is a design flaw in archaic asynchronous messging methods like snail mail, telephone calls or SMTP. You simply don't know who is contacting you and where did they obtain your information from.
To defeat this design flaw I have an unique email address for every single service I ever hand my information to. That particular address in question pre-dates my system and is roughly 20 years old. So, no way of knowing who originally leaked it or how many times the address has been leaked. As I don't use it anywhere anymore, an email sent there is with 99,9% confidence junk.
Why I'm writing about that email is obvious, it had very interesting content. Sender claimed to be (a company?) called CafePress. Something I've never head of. Another reason why I kept investigating this maybe-spam was the subject of "Notice of FTC Settlement - 2019 Data Breach". Ok. Federal Trade Commission of USA was addressing me via CafePress. Really interesting!
First the technical ones. To deduce if this was spam or not, I always check the mail headers. This baby had both SPF and DKIM verified correctly. Both technical measures are pretty much a must for anybody to accept the incoming set of bytes. Well, also spammers know this and typically use Google or Microsoft as spam platforms via their free-of-charge mail offerings.
As technical details checked out, next the actual sending server. It originated to something called https://www.sparkpost.com/. Again, something I've never heard of. Ultimately this mail passed all techical checks. My thinking started leaning towards this being the Real Deal.
Email contents:
Dear Valued Customer,
We are contacting you about the 2019 breach of your information collected by the prior owners of CafePress. This notice is about that breach, which you may have already been notified of.
We recently reached a settlement with the Federal Trade Commission, the nation's consumer protection agency, to resolve issues related to the 2019 data breach, and to make sure CafePress keeps your information safe. What happened?
Before November 2019, CafePress didn't have reasonable practices to keep your information safe. When the company had a security breach, the following information about you may have been stolen: your email address, password, name, address, phone number, answers to your security questions, and the expiration date and last four digits of your credit card.
What you can do to protect yourself
Here are some steps to reduce the risk of identity theft and protect your information online:
<blah blah removed>
Sincerely,
Chris Klingebiel
General Manager, CafePress
Hm. Interesting.
Somebody in a company I've never heard of leaked my data in 2019 by a hack. Well, why did they have my information on the first place!
Googling the topic for more details:

Article Commission orders e-commerce platform to bolster data security and provide redress to small businesses is available on FTC.gov. It was legit after all!
Press release mentionded following: "Residual Pumpkin Entity, LLC, the former owner of CafePress, and PlanetArt, LLC, which bought CafePress in 2020". Whoa! Even more companies which I never heard of.
Some highlights:
According to the complaint, a hacker exploited the company’s security failures in February 2019 to access millions of email addresses and passwords with weak encryption; millions of unencrypted names, physical addresses, and security questions and answers; more than 180,000 unencrypted Social Security numbers; and tens of thousands of partial payment card numbers and expiration dates.
Obviously this CafePress (or whoever it is) didn't do much of a job for protecting their stolen/bought/downloaded-from-DarkNet -data. It's a good thing FTC gave them a slap-on-the-wrist -punishment as the company is clearly crooked. Why an earth didn't FTC do more follow up on the origins of the data? I'd definitely love to hear how this CafePress got my data into their hands. I didn't volunteer it, that's for sure!
Really puzzling case this. I suppose it speaks volumes about the modern state of Internet.
Breaking the paywall - Follow up
Wednesday, June 22. 2022
Back-in-the-day, roughly three years ago, I wrote a JavaScriptlet for breaking trough a press website's paywall. At the time I promised not to "piss" into their proverbial coffee pot and not publish updated versions of my hack. I kept my word. It was surprisingly easy! They didn't change a thing. Until now.
This particular ICT-media finally realized their client tell to contain mostly smart people with good computer skills. Just clicking a button on your shortcuts-bar of your chosen web browser after reading 5 articles was too easy. They finally went into full-blown hedgehog defense and enabled two measures:
- Without authentication, your IPv4-address is tracked.
- No cookies required
- Doesn't care which browser on which computer you're using
- There is a very small number of free-of-charge articles you can read per day. I'd say 5.
- Unfortunately their AWS-setup doesn't have IPv6 enabled. With that I'd have much more IP-addresses at my disposal.

- With authentication, the number of free-of-charge articles is limited. I'd guess to 10 of them.
For proper paywall breakage, lots of IPv4-addresses would be required. I do have some, but I'd rather not play this game anymore. I'll call it quits and stick with the headers of their RSS-feed. Obviously, they'll limit the feed into last 10 articles, but if you keep reading and accumulating the data 24/7, you'll get all of them.
Good job! One potential customer lost.

