Recipe: Trac via Nginx-front
Tuesday, April 23. 2013
Dojo custom build
Monday, April 22. 2013
Internet Bad Neighborhoods
Sunday, April 21. 2013
Earlier I've studied Chinese domain name scams (part 1 and part 2).
A while ago I read about a study made by Mr. Giovane César Moreira Moura. Actually, the study is his PhD thesis and it is available from his page at University of Twente, Netherlands. Anyway, he claims that roughly 50% of the crap in the Internet is originating from 20 rogue networks. He researched 42.000+ ISPs and found out that e-mail spam, scam attempts, etc. are originated pretty much from the same places. He does not do much finger-pointing, but provides the idea how to produce the results.
His study inspired me to investigate the origin networks of all the crap my honey pot was receiving and do some finger-pointing (I don't have any restrictions about that  ). My "honey pot" is a 20+ year old e-mail address. It is in every imaginable spammer/scammer/crap magnet -list. My results are badly skewed: when it receives junk, I'll manually tag it and report it to SpamCop (a spam-protecting service owned by Cisco Systems, Inc.), and eventually blocking the IP-address as a spammer. Since the mail server uses SpamCop blocking-list I won't receive any more junk from the IP, which for studying spammers is not good.
). My "honey pot" is a 20+ year old e-mail address. It is in every imaginable spammer/scammer/crap magnet -list. My results are badly skewed: when it receives junk, I'll manually tag it and report it to SpamCop (a spam-protecting service owned by Cisco Systems, Inc.), and eventually blocking the IP-address as a spammer. Since the mail server uses SpamCop blocking-list I won't receive any more junk from the IP, which for studying spammers is not good.
There is lot of evidence that most crap originates from hijacked computers, but not all. Some of spam arriving to me originates from VPS-boxes. I dunno if they are rented with real or stolen credit cards. Anyway, most spam I receive have some sort of forging attempt in the mail headers. So I'm utilizing tracing of non-forged e-mail origin with SpamCop's reporting tool. In his thesis Mr. Moura writes that the ultimate origin is almost always not discoverable. Hiding one's real location is way too easy in the Internet. Closing the sending IP typically helps, but leaves the criminal unidentified.
Anyway, here's my list:
- 30, IRINN-BROADCAST-ADDRESSES, India
- 9, GOOGLE, USA
- 8, PAET-FSS-IMPLI-1, USA
- 5, FR-OVH, France
- 3, 66-132-128-0-NET, USA
- 3, EGIHOSTING-4, USA
- 2, 1AN1-NETWORK, USA
- 2, DROPBOX, USA
- 2, NLYR-ARIN-BLK5, USA
The number is number of e-mails originating from that network followed by the network name. The list was gathered during 90 day period. In the list there were additional 80 networks with only single e-mail originating from them.
Most of the crap I receive originates from India. 2nd biggest seems to be Google. Also a huge virtual server renting company OVH-net is in the 4th place. Others I cannot explain. Another conclusion I can draw from these is that the 20 worst networks are not the ones bothering me.
Windows 7 not staying in sleep-mode
Thursday, April 18. 2013
Wuala (LaCie): Stop using the Java!
Wednesday, April 17. 2013
Linux 3.8 failing to operate as Hyper-V guest
Tuesday, April 16. 2013
Fedora 17: Ethernet interface lost
Monday, April 15. 2013
AbyssGuard 1.7.7 PHP source code de-obfuscated
Thursday, April 11. 2013
Linux guest running on Hyper-V crashing with IRQL LESS OR NOT EQUAL
Wednesday, April 10. 2013
Mac OS X Dolby Digital 5.1 with Mac Mini [Not solved]
Tuesday, April 9. 2013
Update 30th Dec 2013:
Anything I say below is subject to debate. This issue is not clear, see the new article about Mac Mini HDMI Dolby Digital audio output.
My mini is mainly for entertainment purposes and I chose to use it at living room. That should be an easy setup, right? Just plug the HDMi-output of the mini into my Yamaha amp which is connected to my Sony TV and everything will work out just fine. No.
Video-signal passes through the amp and TV displays it as supposed in correct resolution and frame rate. No glitches there. But the audio-signal has issues, there were only disappointing two channels. I was expecting to see 5.1 channels as my Yamaha amp has been set up already.
First I confirmed that my Mac Mini supported multichannel output (2 channels as stereo is not multi). There is no adapter in my setup (About Mini DisplayPort to HDMI adapters @ Apple support), so initially I had to assume that HDMi-port supports multichannel audio since my model is newer than mid 2010 and newer than early 2009 with adapter. To my understanding 2009 is the point where multichannel audio was possible without 3rd party add-ons. Anyway, I'm way above that line and should have the support.
Apple support forums have vast number of discussion threads about getting 5.1 sound. It is apparent, that for some reason, this is a problematic issue. I'm saying that the reason is: it does not work out-of-the-box as most Apple fans are used to doing everything in the Apple-land.
After numerous failing attempts I finally managed to get my setup working. At one point I realized that my mini is displaying audio status based on my TV, which obviously can produce only stereo sound. There is the amp in the HDMi-chain, and mini should detect audio by that. When I enable multichannel output from OS X:
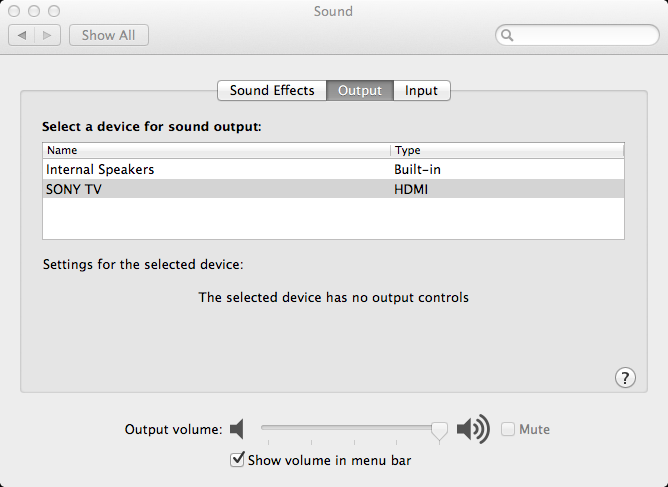
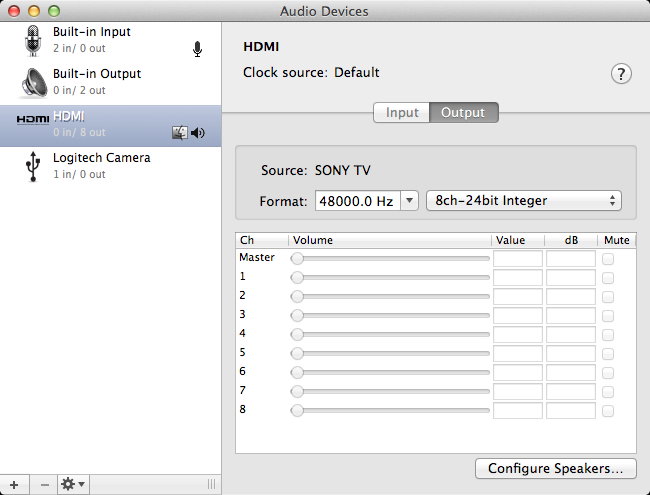

... my amp does not reflect the change. It still displays the input signal as stereo. This is not typical behaviour. My amp correctly detects the type of the audio signal on all of my other devices. The fact that I missed was, that I can force the amp to do 7-channel signal:
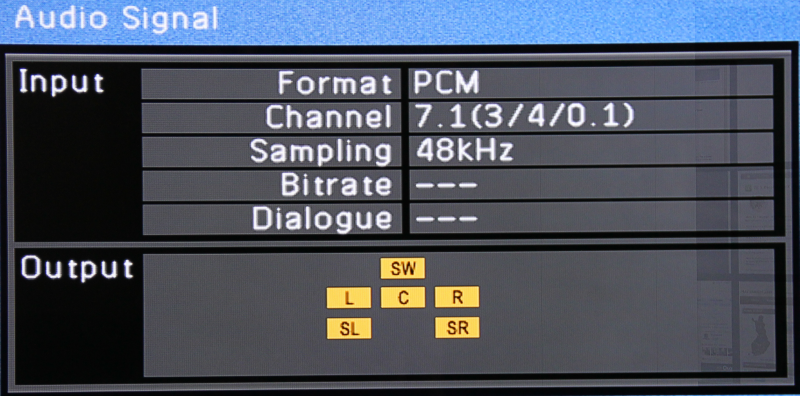
![]()
... then 5.1 sound works perfectly.
Testing that everything works ok is very simple: In the MIDI-sound app there is the test-button. When each channel produces sound correctly, I downloaded a couple of movie trailes from http://trailers.apple.com/ and verified that all was as it was supposed to be.
Hope this helps somebody struggling with multi-channel issues.

