Linux 3.8 failing to operate as Hyper-V guest
Tuesday, April 16. 2013
Fedora 17: Ethernet interface lost
Monday, April 15. 2013
Linux guest running on Hyper-V crashing with IRQL LESS OR NOT EQUAL
Wednesday, April 10. 2013
Mac OS X Dolby Digital 5.1 with Mac Mini [Not solved]
Tuesday, April 9. 2013
Update 30th Dec 2013:
Anything I say below is subject to debate. This issue is not clear, see the new article about Mac Mini HDMI Dolby Digital audio output.
My mini is mainly for entertainment purposes and I chose to use it at living room. That should be an easy setup, right? Just plug the HDMi-output of the mini into my Yamaha amp which is connected to my Sony TV and everything will work out just fine. No.
Video-signal passes through the amp and TV displays it as supposed in correct resolution and frame rate. No glitches there. But the audio-signal has issues, there were only disappointing two channels. I was expecting to see 5.1 channels as my Yamaha amp has been set up already.
First I confirmed that my Mac Mini supported multichannel output (2 channels as stereo is not multi). There is no adapter in my setup (About Mini DisplayPort to HDMI adapters @ Apple support), so initially I had to assume that HDMi-port supports multichannel audio since my model is newer than mid 2010 and newer than early 2009 with adapter. To my understanding 2009 is the point where multichannel audio was possible without 3rd party add-ons. Anyway, I'm way above that line and should have the support.
Apple support forums have vast number of discussion threads about getting 5.1 sound. It is apparent, that for some reason, this is a problematic issue. I'm saying that the reason is: it does not work out-of-the-box as most Apple fans are used to doing everything in the Apple-land.
After numerous failing attempts I finally managed to get my setup working. At one point I realized that my mini is displaying audio status based on my TV, which obviously can produce only stereo sound. There is the amp in the HDMi-chain, and mini should detect audio by that. When I enable multichannel output from OS X:
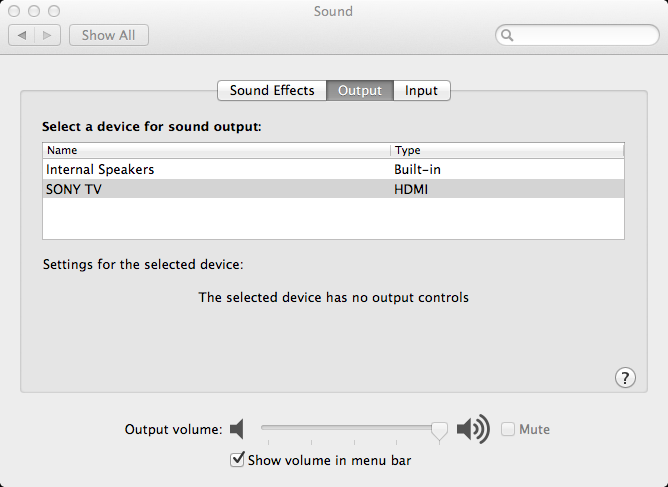
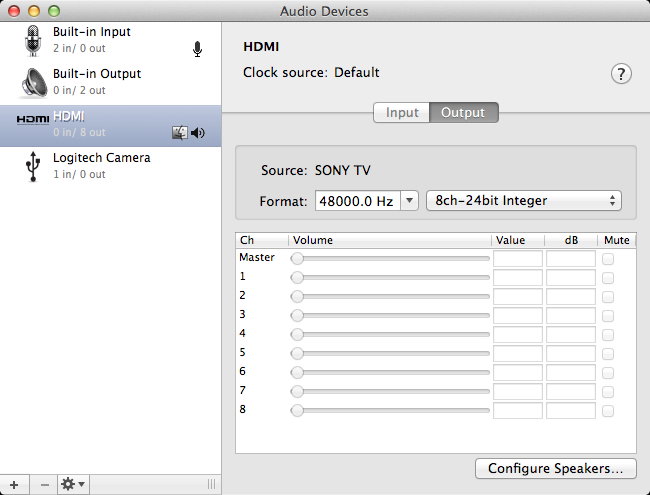

... my amp does not reflect the change. It still displays the input signal as stereo. This is not typical behaviour. My amp correctly detects the type of the audio signal on all of my other devices. The fact that I missed was, that I can force the amp to do 7-channel signal:
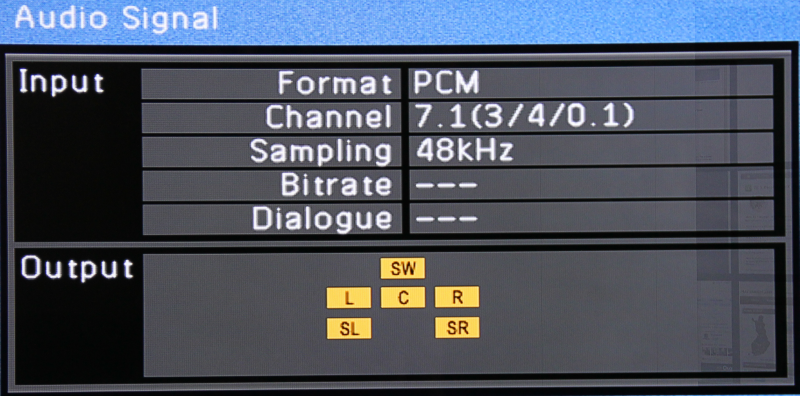
![]()
... then 5.1 sound works perfectly.
Testing that everything works ok is very simple: In the MIDI-sound app there is the test-button. When each channel produces sound correctly, I downloaded a couple of movie trailes from http://trailers.apple.com/ and verified that all was as it was supposed to be.
Hope this helps somebody struggling with multi-channel issues.

