Breaking the paywall
Wednesday, April 3. 2019
Newspaper media and magazines have been suffering from digitalization for two decades. Quite few of the traditional publishers have been struggling to keep their revenue stream flowing.
Back in the 90s Internet-boom they simply went to net "because they had to". No clue what to do there, though. Paper sales were going strong, no actions required. Then the obvious happened, people stopped subscribing their paper services. Meanwhile, same people who cancelled their subscriptions, were reluctant to pay for the service on the net. Reasons were multitude: bad implementation of the site, bad implementation of subscription and payment, etc.
Past couple years the trend has been to simply block readers out of the site by erecting a paywall. That will keep the free leechers out (like me), but I'm not certain it would improve the sales. Maybe it does, because lot of the media is doing that. However, yet again the implementation is really bad. There must be enough complexity in the paywall that people like me cannot simply run something like this in Javascript console:
javascript:(function(d){d.cookie='Bhb2CdOB3V=; expires=Thu, 01 Jan 1970 00:00:00 UTC; path=/; domain=.tivi.fi;'})(document)
If you have no idea what a Javascript console is (most non-developer don't), don't worry. Here is the same thing as a bookmarklet. Concept of bookmarking sites into your browser is past gone, everybody just googles everything. Since nobody maintains bookmarks, it is not-so-user-friendly to manage bookmarks in a modern browser. However, the idea of you is to create a Javascript bookmark, aka. bookmarklet. In chrome, something like this:
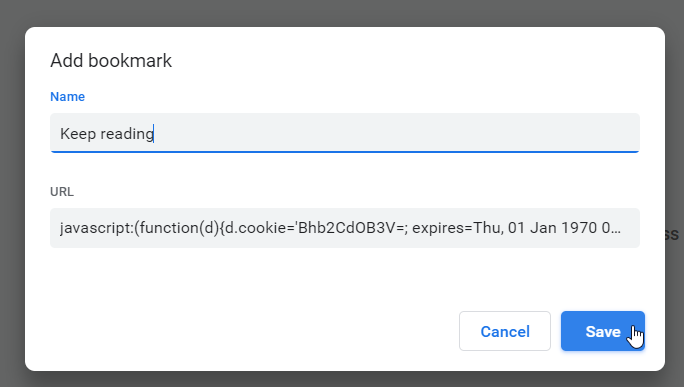
Then it is easy to just click the bookmark when you run out of reads. Reload the page and keep reading!
Finally:
Apologies for the newspaper publisher for pissing in their coffee pot. Your product is good and I have enjoyed reading the articles, it's just the price point, you're too expensive! My motivation here is to offer you a pro-bono implementation evaluation. Hint: you failed badly.
I totally expect them to improve their implementation. Also I promise not to maintain any possible hacks their future versions may include. Also I'd like to offer a piece of advice.
There are two real options you can go with:
1) implement mandatory login
or
2) keep some articles free, some behind paywall. That seems to be the only working option of keeping people like me out of your system.

