Databricks CentOS 9 Stream containers
Thursday, October 20. 2022
Earlier this year I was tinkering with Databricks and got fed up with Ubuntu 18 and 20 with pretty old Python in it. Easy fix! I just made containers with CentOS so I could have more recent versions of stuff in my nodes.
Natural next move was to bump CentOS version from 8 to 9. While at it I discarded the previous hierarchy. Here is the original pic:
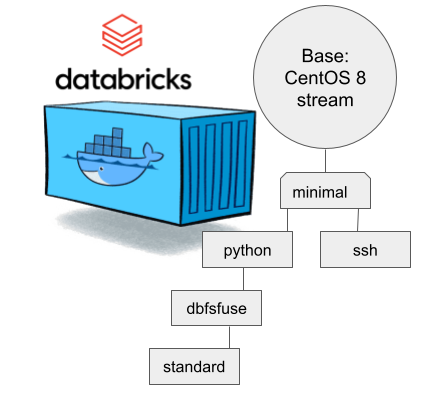
CentOS 8 containers explained:
- Minimal: CentOS 8 Stream + stuff to make CentOS work in Apache Spark / Databricks
- SSH: Minimal + OpenSSH server for those running Databricks on top of their own VNets. If you aren't this won't do you any good. TCP/22 won't be open from The World.
- Python: This here is the beef in Databricks! Running a Jupyter Notebook / IPython will absolutely definitely need this.
- DBFS FUSE: Linux user file system to attach the container into DatabricksFS / HadoopFS
- Standard: DBFS FUSE + OpenSSH, see disclaimer from SSH container about connectivity
The hierachy originates from https://github.com/databricks/containers/tree/master/experimental. Initially I just went with the flow, but as always, gaining more information and experience on Databrics, it became apparent to me this separation wasn't working.
New hierarchy for CentOS 9:
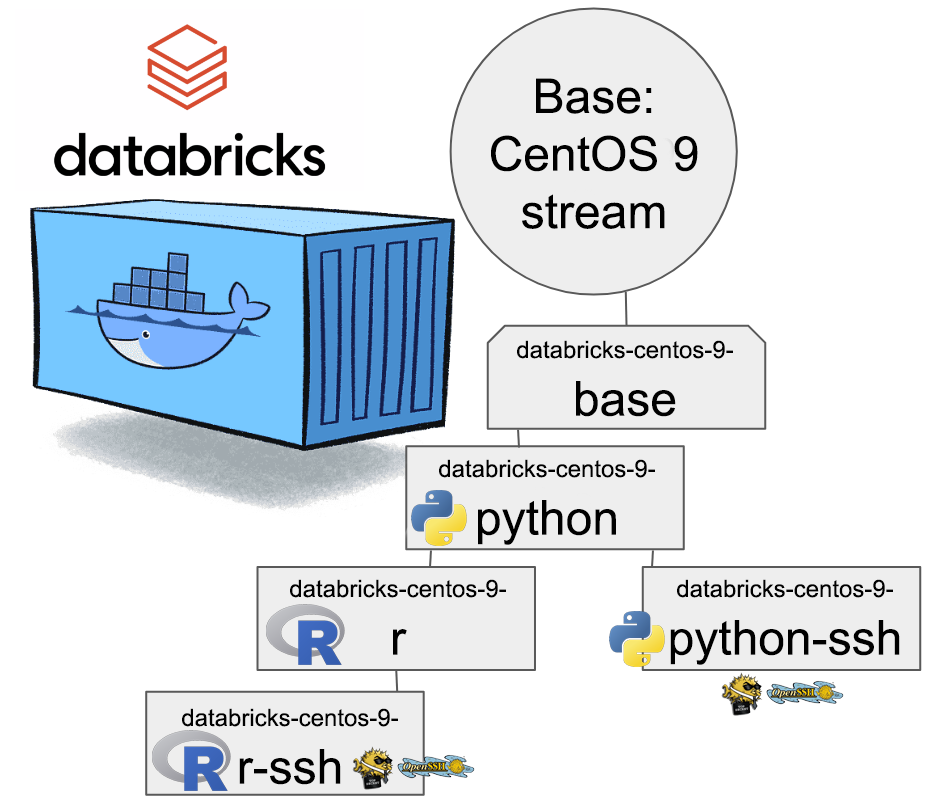
CentOS 8 containers explained:
- Base: CentOS 9 Stream + stuff to make CentOS work in Apache Spark / Databricks + FUSE
- Rationale: You will want to have DBFS mounted to your container anyway. It won't be a security risk and FUSE is a very light piece of software in a Linux.
- Note: This will not work as an Apache Spark / Databricks node.
- Python: Running a Jupyter Notebook will absolutely definitely need this.
- Rationale: A Spark node without proper Python won't boot. This should be in minimal/base to begin with, but I just wanted to separate all the required Linux components and settings from a Python.
- Note: This is the minimal. This will boot and work.
- Python-SSH: Python + OpenSSH
- Note: You will need your own VNet to get SSH-access into your Spark Driver -node.
- Note 2: If you don't specify your own, a managed VNet will be used. You just won't have any access into it.
- R: For statistical computing needs, quite a few users prefer R programming language. This here container-type will enable you to do that from a Jupyter Notebook in Databricks. Will contain Python.
- Rationale: R is a huge chunk of container. If you won't be needing this, stick with Python which is so much lighter to load and operate.
- R-SSH: R + OpenSSH
- See disclaimer from above
Python components version table
To verify what Databicks puts into their nodes, I gathered versions following Python components.
| Python component | CentOS 9 | 11.2 | 11.1 | 11.0 | 10.4 LTS | 9.1 LTS |
|---|---|---|---|---|---|---|
| ipykernel | 6.16.0 | 6.12.1 | 6.12.1 | 6.12.1 | 5.3.4 | 5.3.4 |
| ipython | 7.32.0 | 7.32.0 | 7.32.0 | 7.32.0 | 7.22.0 | 7.22.0 |
| Jinja2 | 2.11.3 | 2.11.3 | 2.11.3 | 2.11.3 | 2.11.3 | 2.11.3 |
| jupyter-core | 4.11.1 | 4.8.1 | 4.8.1 | 4.8.1 | 4.7.1 | 4.7.1 |
| matplotlib | 3.4.3 | 3.4.3 | 3.4.3 | 3.4.3 | 3.4.2 | 3.4.2 |
| numpy | 1.20.3 | 1.20.3 | 1.20.3 | 1.20.3 | 1.20.1 | 1.19.2 |
| pandas | 1.3.4 | 1.3.4 | 1.3.4 | 1.3.4 | 1.2.4 | 1.2.4 |
| pyarrow | 4.0.0 | 7.0.0 | 7.0.0 | 7.0.0 | 4.0.0 | 4.0.0 |
| six | 1.16.0 | 1.16.0 | 1.16.0 | 1.16.0 | 1.15.0 | 1.15.0 |
| virtualenv | 20.16.5 | 20.8.0 | 20.8.0 | 20.8.0 | 20.4.1 | 20.4.1 |
Comparison of other differences:
| Component | CentOS 9 | 11.2 | 11.1 | 11.0 | 10.4 LTS | 9.1 LTS |
|---|---|---|---|---|---|---|
| Scala | 2.12.14 | 2.12.14 | 2.12.14 | 2.12 | 2.12 | 2.12 |
| Spark | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.2.1 | 3.2.1 |
| Python | 3.9.14 | 3.9.5 | 3.9.5 | 3.9.5 | 3.8.10 | 3.8.10 |
| R | 4.2.1 | 4.1.3 | 4.1.3 | 4.1.3 | 4.1.2 | 4.1.2 |
| Linux | CentOS 9 Stream |
Ubuntu 20.04.5 LTS |
Ubuntu 20.04.5 LTS |
Ubuntu 20.04.5 LTS |
Ubuntu 20.04.5 LTS |
Ubuntu 20.04.5 LTS |
These two tables explain very well my motivation of doing all this. Getting a full control of what goes into those containers. Second motivation is to publish the recipe for anybody to tailor their own custom made containers containing the versions of software they'll be needing.
Testing my container
Here is a sample notebook I used while develping this:
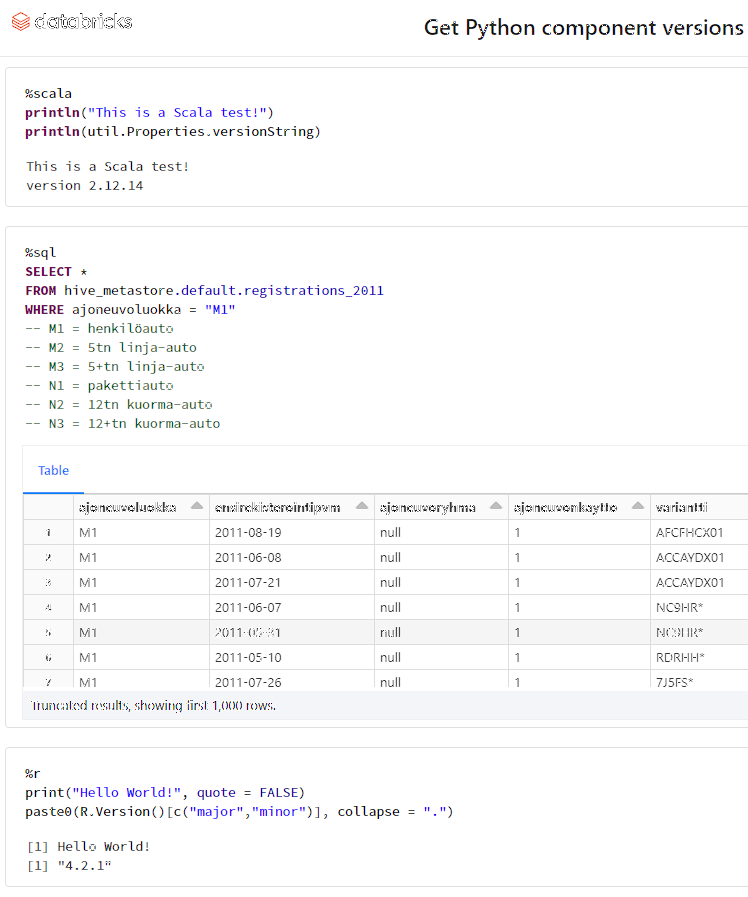
Modern Databricks notebook supports SQL, R and Scala with ease. I absolutely wanted to see what'll be needed to get all of those running.
To repeat: Python will be needed to get the entire Databricks node booting. On top of that, Scala will be included by Apache Spark. SQL will be handled by Spark. R will be provided by Rserve and interface to that is via notebook's R Python-client.
Final words
Databricks: Please, publish your own work also. For unknown reason you aren't doing that.

