Worst mobile app ever? Danske Bank's mobile pay
Monday, December 16. 2013
Danske has a huge ad campaign here in Finland about the new mobile payment system. You can send and receive money simply by using a phone number. I'm not going to dwell into the security issues of such a system today, because what could possibly go wrong!  Ok, I'll give them that they have limited the damage by built in a cap of the amount you can transfer, 250,- € per day and 15.000,- € per year. So, in any unfortunate event people are not going to much (if 250,- € is all you have, then ... it's another story).
Ok, I'll give them that they have limited the damage by built in a cap of the amount you can transfer, 250,- € per day and 15.000,- € per year. So, in any unfortunate event people are not going to much (if 250,- € is all you have, then ... it's another story).
Anyway. I got the app from the App Store and started their registration process. It's long. It's tedious. It'll drive you crazy. Looks like they don't want your business.
The information they ask during registration:
- First name, last name
- E-mail address
- Phone number
- Credit card number
- IBAN-number of your bank account
Not a problem. I have all of those. But guess who has all the information in the same phone, you're supposed to enter the data. Typically that's not a problem. A simple task switch to password vault software, copy the numbers and back to registration.
Now the idiots who designed and wrote the app expect everybody to know and type long series of input data. Nobody ever does that! That's what the mobile computers are for: they store data and make it possible to copy and paste it between apps. But these design geniuses chose not to use anything standard. If you switch apps between registration, the entire process needs to be started over. Nice! Really nice thinking. The paste won't work anyway, so ...
Definitely this is a good example of now not to write apps.
Getting the worst of Windows 7 - Install updates automatically (recommended)
Friday, December 13. 2013
Windows 8.1 upgrade and Media Center Pack
Wednesday, December 11. 2013
Earlier I wrote about upgrading my Windows 8 into Windows 8.1. At the time I didn't realize it, but the upgrade lost my Media Center Pack.
At the time I didn't realize that, but then I needed to play a DVD with the laptop and noticed, that the OS is not capable of doing that anymore. After Windows 8 was released it didn't have much media capabilities. To fix that, couple months after the release Microsoft distributed Media Center Pack keys for free to anybody who wanted to request one. I got a couple of the keys and installed one into my laptop.
Anyway, the 8.1 upgrade forgot to mention that it would downgrade the installation back to non-media capable. That should be an easy fix, right?
Wrong!
After the 8.1 upgrade was completed, I went to "Add Features to Windows", said that I already had a key, but Windows told me that nope, "Key won't work". Nice. 
At the time I had plenty of other things to take care of and the media-issue was silently forgotten. Now that I needed the feature, again I went to add features, and hey presto! It said, that the key was ok. For a couple of minutes Windows did something magical and ended the installation with "Something went wrong" type of message. The option to add features was gone at that point, so I really didn't know what to do.
The natural thing to do next is to go googling. I found an article at the My Digital Life forums, where somebody complained having the same issue. The classic remedy for everything ever since Windows 1.0 has been a reboot. Windows sure likes to reboot. I did that and guess what, during shutdown there was an upgrade installing. The upgrade completed after the boot and there it was, the Windows 8.1 had Media Center Pack installed. Everything worked, and that was that, until ...
Then came the 2nd Tuesday, traditionally it is the day for Microsoft security updates. I installed them and a reboot was requested. My Windows 8.1 started disliking me after that. The first thing it did after a reboot, it complained about Windows not being activated! Aow come on! I punched in the Windows 8 key and it didn't work. Then I typed the Media Center Pack key and that helped. Nice. Luckily Windows 8 activation is in the stupid full-screen mode, so it is really easy to copy/paste a license key. NOT!
The bottom line is: Media Center Pack is really poorly handled. I'm pretty sure nobody at Microsoft's Windows 8 team ever installed the MCP. This is the typical case of end users doing all the testing. Darn!
Younited cloud storage
Monday, December 9. 2013
I finally got my account into younited. It is a cloud storage service by F-Secure, the Finnish security company. They boast that it is secure, can be trusted and data is hosted in Finland out of reach by those agencies with three letter acronyms.
The service offers you 10 GiB of cloud storage and plenty of clients for it. Currently you can get in only by invite. Windows-client looks like this:
Looks nice, but ...
I've been using Wuala for a long time. Its functionality is pretty much the same. You put your files into a secure cloud and can access them via number of clients. The UI on Wuala works, the transfers are secure, they are hosted on Amazon in Germany, company is from Switzerland owned by French company Lacie. When compared with Younited, there is a huge difference and it is easy to see which one of the services has been around for years and which one is in open beta.
Given all the trustworthiness and security and all, the bad news is: In its current state Younited is completely useless. It would work if you have one picture, one MP3 and one Word document to store. The only ideology of storing items is to sync them. I don't want to do only that! I want to create a folder and a subfolder under it and store a folder full of files into that! I need my client-storage and cloud storage to be separate entity. Sync is good only for a handful of things, but in F-Secure's mind that's the only way to go. They are in beta, but it would be good to start listening to their users.
If only Wuala would stop using Java in their clients, I'd stick with them.
CentOS 6 PHP 5.4 and 5.5 for Parallels Plesk Panel 10+
Friday, November 29. 2013
One of my servers is running Parallels Plesk Panel 11.5 on a CentOS 6. CentOS is good platform for web hosting, since it is robust, well maintained and it gets updates for a very long time. The bad thing is that version numbers don't change during all those maintenance years. In many cases that is a very good thing, but when talking about web development, once a while it is nice to get upgraded versions and the new features with them.
In version 10 Parallels Plesk introduced a possibility of having a choice for the PHP version. It is possible to run PHP via Apache's mod_php, but Parallels Plesk does not support that. The only supported option is to run PHP via CGI or FastCGI. Not having PHP via mod_php is not a real problem as FastCGI actually performs better on a web box when the load gets high enough. The problem is, that you cannot stack the PHP installation on top of each other. Different versions of a package tend to reside in the same exact physical directory. That's something that every sysadmin learns in the beginning stages of their learning curve.
CentOS being a RPM-distro can have relocatable RPM-packages. Still, if you install different versions of same package to diffent directories, the package manager complains about a version having been installed already. To solve this and have my Plesk multiple PHP versions I had to prepare the packages myself.
I started with Andy Thompson's site webtatic.com. He has prepared CentOS 6 packages for PHP 5.4 and PHP 5.5. His source packages are mirrored at http://nl.repo.webtatic.com/yum/el6/SRPMS/. He did a really good job and the packages are excellent. However, the last problem still resides. Now we can have a choice of the default CentOS PHP 5.3.3 or Andy's PHP 5.4/5.5. But only one of these can exist at one time due to being installed to the same directories.
My packages are at http://opensource.hqcodeshop.com/CentOS/6 x86_64/Parallels Plesk Panel/ and they can co-exist with each other and CentOS standard PHP. The list of changes is:
- Interbase-support: dropped
- MySQL (the old one): dropped
- mysqlnd is there, you shouldn't be using anything else anyway
- Thread safe (ZTS) and embedded versions: dropped
- CLI and CGI/FastCGI are there, the versions are heavily optimized to be used in a Plesk box
- php-fpm won't work, guaranteed!
- I did a sloppy job with that. In principle, you could run any number of php-fpm -daemons in the same machine, but ... I didn't do the extra job required as the Plesk cannot benefit from that.
After standard RPM-install, you need to instruct Plesk, that it knows about another PHP. Read all about that from Administrator's Guide, Parallels Plesk Panel 11.5 from the section Multiple PHP Versions. This is what I ran:
/usr/local/psa/bin/php_handler --add -displayname 5.4 \
-path /opt/php5.4/usr/bin/php-cgi \
-phpini /opt/php5.4/etc/php.ini \
-type fastcgi
After doing that, in the web hosting dialog there is a choice: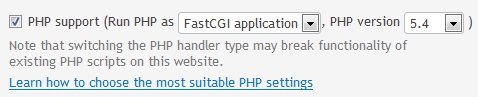
Note how I intentionally called the PHP version 5.4.22 as 5.4. My intention is to keep updating the 5.4-series and not to register a new PHP-handler for each minor update.
Also on a shell:
-bash-4.1$ /usr/bin/php -v
PHP 5.3.3 (cli) (built: Jul 12 2013 20:35:47)
-bash-4.1$ /opt/php5.4/usr/bin/php -v
PHP 5.4.22 (cli) (built: Nov 28 2013 15:54:42)
-bash-4.1$ /opt/php5.5/usr/bin/php -v
PHP 5.5.6 (cli) (built: Nov 28 2013 18:20:00)
Nice! Now I can have a choice for each web site. Btw. Andy, thanks for the packages.
Parallels Plesk Panel: Disabling local mail for a subscription
Thursday, November 28. 2013
The mail disable cannot be done via GUI. Going to subscription settings and un-checking the Activate mail service on domain -setting does not do the trick. Mail cannot be disabled for a single domain, the entire subscription has to be disabled. See KB Article ID: 113937 about that.
I found a website saying that domain command's -mail_service false -setting would help. It does not. For example, this does not do the trick:
/usr/local/psa/bin/domain -u domain.tld -mail_service false
It looks like this in the Postifx log /usr/local/psa/var/log/maillog:
postfix/pickup[20067]: F2B5222132: uid=0 from=<root>
postfix/cleanup[20252]: F2B5222132: message-id=<20131128122425.F2B5222132@da.server.com>
postfix/qmgr[20068]: F2B5222132: from=<root@da.server.com>, size=4002, nrcpt=1 (queue active)
postfix-local[20255]: postfix-local: from=root@da.server.com, to=luser@da.domain.net, dirname=/var/qmail/mailnames
postfix-local[20255]: cannot chdir to mailname dir luser: No such file or directory
postfix-local[20255]: Unknown user: luser@da.domain.net
postfix/pipe[20254]: F2B5222132: to=<luser@da.domain.net>, relay=plesk_virtual, delay=0.04, delays=0.03/0/0/0, dsn=2.0.0, status=sent (delivered via plesk_virtual service)
postfix/qmgr[20068]: F2B5222132: removed
not cool.
However KB Article ID: 116927 is more helpful. It offers the mail-command. For example, this does do the trick:
/usr/local/psa/bin/mail --off domain.tld
Now my mail exits the box:
postfix/pickup[20067]: 5218222135: uid=10000 from=<user>
postfix/cleanup[20692]: 5218222135: message-id=<mediawiki_0.5297385c4d15f5.15419884@da.server.com>
postfix/qmgr[20068]: 5218222135: from=<user@da.server.com>, size=1184, nrcpt=1 (queue active)
postfix/smtp[20694]: certificate verification failed for aspmx.l.google.com[74.125.136.27]:25: untrusted issuer /C=US/O=Equifax/OU=Equifax Secure Certificate Authority
postfix/smtp[20694]: 5218222135: to=<luser@da.domain.net>, relay=ASPMX.L.GOOGLE.COM[74.125.136.27]:25, delay=1.1, delays=0.01/0.1/0.71/0.23, dsn=2.0.0, status=sent (250 2.0.0 OK 1385642077 e48si8942242eeh.278 - gsmtp)
postfix/qmgr[20068]: 5218222135: removed
Cool!
How not to process bug reports - The Red Hat way
Wednesday, November 27. 2013
Over 5 years ago I filed a bug report about GCC crashing during ImageMagick compilation on RHEL 5. Nobody at Red Hat cared about that until couple days ago. Funny thing. At the time I had the issue, I simply kept the old ImageMagick and completed the project with that one. It would have been nice to have a more recent version, but since the new one would not compile, I just forgot about it.
Now the Red Hat guy Jeff is just being stupid. Why would anybody care anymore? Why did he have to do the obligatory works-for-me / need-more-information -routine. Now, at this point its just insulting, since they ignored the issue when it was actually present. Who would use RHEL 5 anymore. Not me.
OS X Time Machine waking up from sleep to do a backup
Tuesday, November 26. 2013
 I was pretty amazed to notice that my Mac actually wakes up for the sole
purpose of running a scheduled backup and goes back to sleep. Oh, but
why?
I was pretty amazed to notice that my Mac actually wakes up for the sole
purpose of running a scheduled backup and goes back to sleep. Oh, but
why?
Going to web with the issue helped, I found Apple support community discussion with topic "time machine wake up unwanted". I don't think my pre 10.9 did that. Anyway I can confirm that 10.9 does this rather stupid thing.
Luckily the discussion thread also offers the fix: "Time Machine won't wake up a Mac, unless another Mac is backing-up to a shared drive on it via your network, and the Wake for network access box is checked in System Preferences > Energy Saver". Definitely something for me to try.
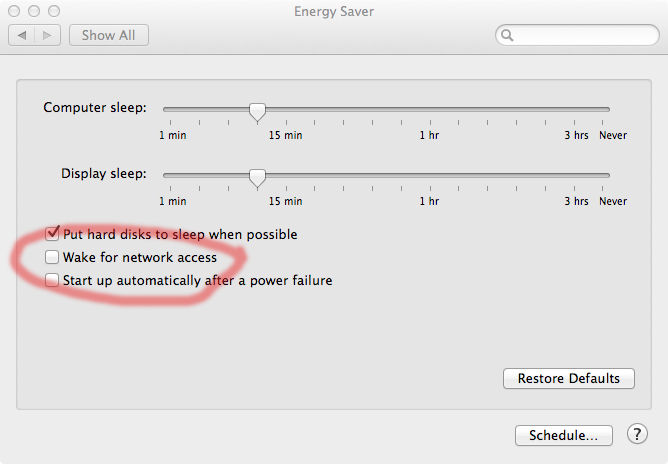
It helped! I can confirm, that there are no backups for the time my Mac was asleep. Pretty soon I woke it up, it started a TM-backup and completed it.
Thanks Pondini in Florida, USA!
Vim's comment line leaking is annoying! Part 2
Monday, November 25. 2013
Apache configuration: Exclude Perl-execution for a single directory
Wednesday, November 20. 2013
Exploit: Running commands on B593 shell
Tuesday, November 19. 2013
Telenor firmware for B593u-12
Saturday, November 16. 2013
Vodafone firmware for B593u-12
Saturday, November 16. 2013
Huawei B593 different models
Sunday, November 10. 2013
Just to clarify: My exact mode of Huawei 4G router is CPE B593u-12.
So my previous writings about 3's firmware and Saunalahti's firmware are specific to that exact model. According to 4G LTE mall website following models exist:
- B593u-12: FDD 800/900/1800/2100/2600MHz
- B593s-22: TDD 2600 FDD 800/900/1800/2100/2600MHz (Speed to 150Mbps)
- B593s-82: TDD 2300/2600MHz
- B593s-58: TDD 1900/2300/2600MHz
- B593s-58b: TDD 1900/2300MHz
- B593u-91: TDD 2300/2600MHz
- B593u: LTE FDD 850/900/1800/1900/2600 MHz
- B593s: Band 42 (3400-3600MHz)
- B593u-513
- B593s-42
- B593u-501
- B593u-41
- B593s-601
In Finland the most common models are the two first ones: u-12 and s-22.
There are number of discussions for getting a new firmware (they even copy/paste stuff from my blog without crediting me as the author), but please carefully find out the exact model before upgrading. If you manage to inject an incorrect firmware, it will most likely brick your thing. I didn't try that and don't plan to.
What's funny is that Huawei does not publicly have a B593 in their product portfolio, apparently their only sales/support channel is via their client Telcos and they don't publish anything except the GPL-code required by GPL v2 license.

