WebAuthN Practically - iOS 15
Monday, September 20. 2021
As Apple has recently released iOS 15, and iPadOS 15 and macOS 12 will be released quite soon. Why that is important is for Apple's native support for WebAuthN. In my WebAuthN introduction -post there is the release date for the spec: W3C Recommendation, 8 April 2021. Given the finalization of the standard, Apple was the first major player to step forward and start supporting proper passwordless authentication in it's operating systems. For more details, see The Verge article iOS 15 and macOS 12 take a small but significant step towards a password-less future.
For traditional approach with USB-cased Yubikey authenticator, see my previous post.
Registration
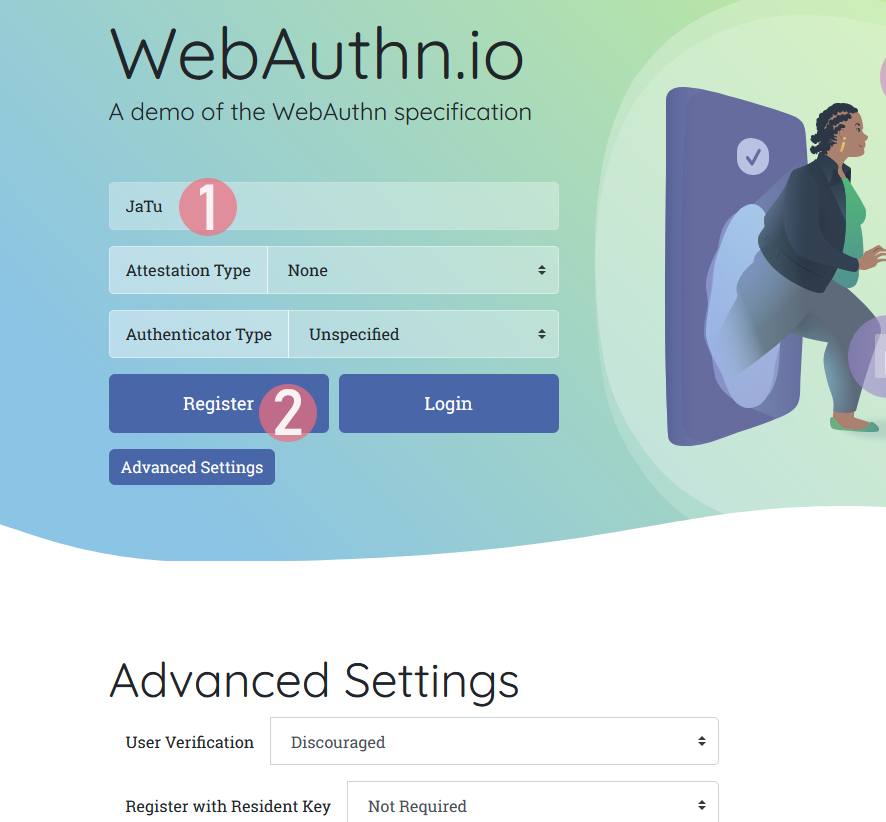
Step 1: Enter the username you'd like to register as.
Step 2: Go for Register
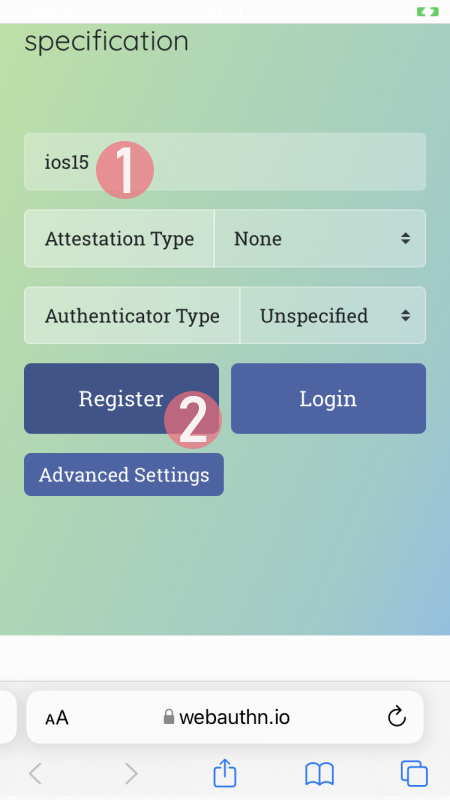
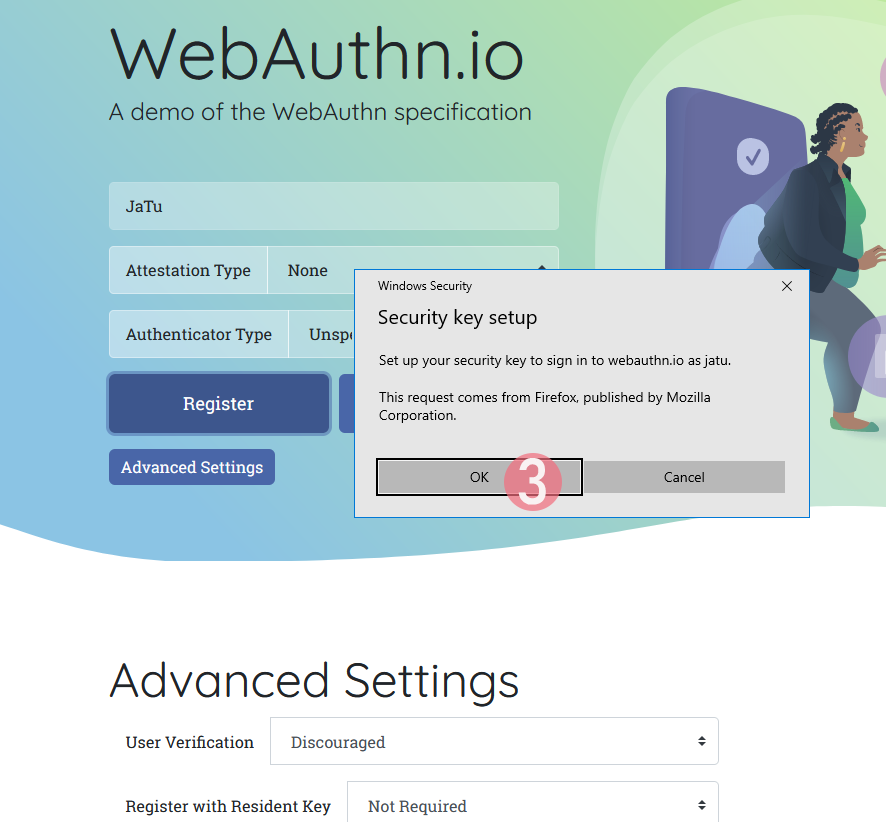
Step 3: Your browser will need a confirmation for proceeding with registration.
In Apple's ecosystem, the private key is stored into Apple's cloud (what!?). To allow access to your cloud-based secerts-storage, you must enter your device's PIN-code and before doing that, your permission to proceed is required.
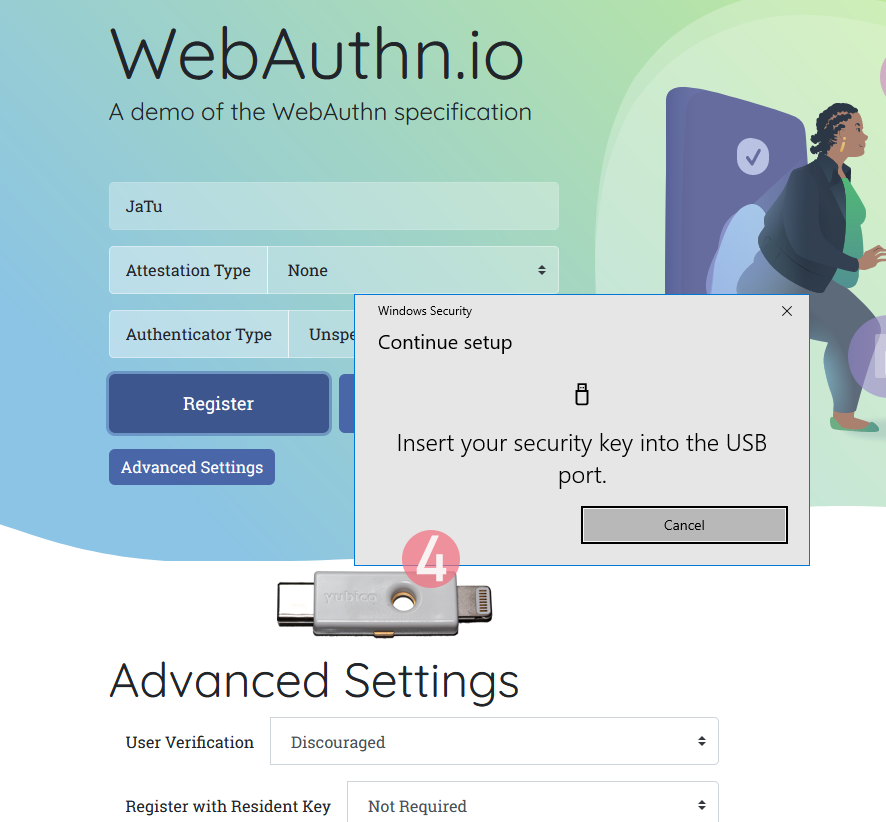
Note: The option for "Use Security Key" is for using the Yubikey in Lightning-port. Both are supported. It is entirely possible to login using the same authenticator with a USB-C in my PC or Mac and Lightning with my iPhone or iPad.
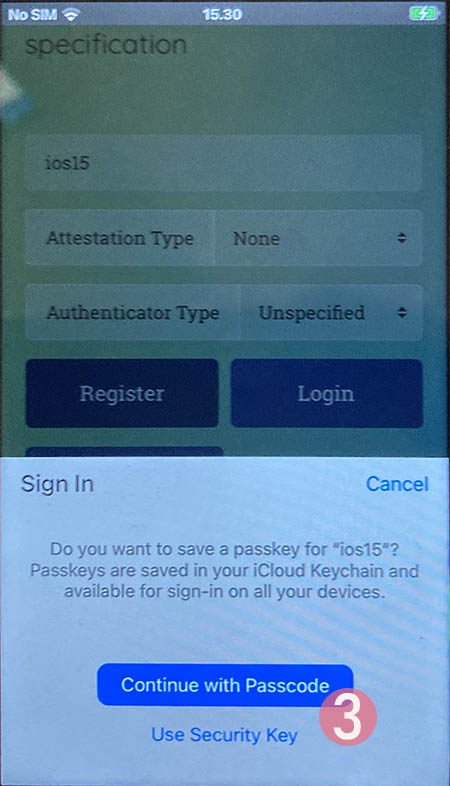
Step 4: Enter your device PIN-code

Step 5: You're done! Now you have successfully registered.
Best part: No passwords! Private key is stored into Syncing Platform Authenticator. Btw. weird name that for WebAuthN in Apple-lingo. Ok, to be honest, WebAuthN is a mouthful too.
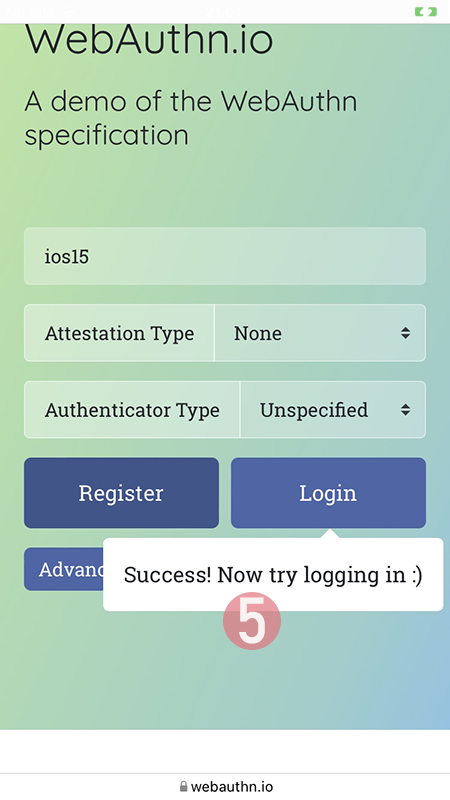
This was couple steps simpler than with Yubikey. Also there is the benefit (and danger) of cloud. Now your credential can be accessed from your other devices too.
Login
Step 1: Enter the username you'd like to log in as.
Step 2: Go for Login

Step 3: Your browser will need a confirmation for proceeding with login. A list of known keys and associated user names will be shown.
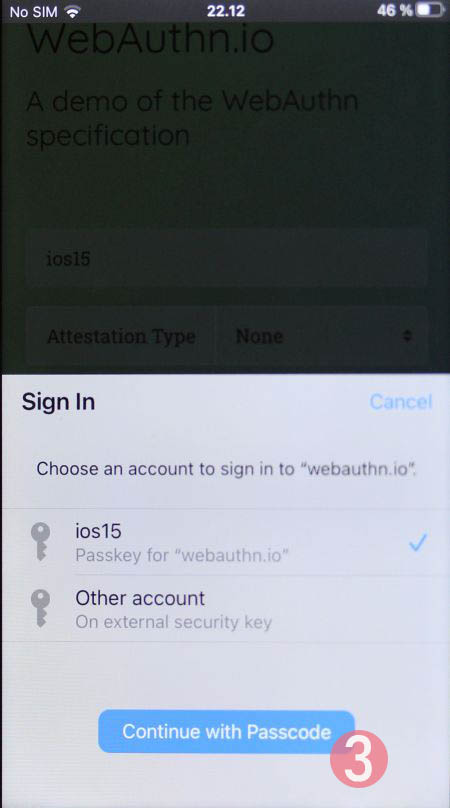
Step 4: Enter your device PIN-code

Step 5: You're done! Now you have successfully logged in.
Best part: No passwords!
That's it. Really.
Finally
I don't think there is much more to add into it.
In comparison to Yubikey, any of your Apple-devices are authenticators and can share the private key. Obviously, you'll need iOS 15 or macOS 12 for that support.
WebAuthN Practically - Yubikey
Sunday, September 19. 2021
Basics of WebAuthN have been covered in a previous post. Go see it first.
As established earlier, WebAuthN is about specific hardware, an authenticator device. Here are some that I use:

These USB-A / USB-C / Apple Lightning -connectibe Yubikey devices are manufactured by Yubico. More info about Yubikeys can be found from https://www.yubico.com/products/.
To take a WebAuthN authenticator for a test-drive is very easy. There is a demo site run by Yubico at https://demo.yubico.com/ containing WebAuthN site. However, as a personal preference I like Duo Security's demo site better. This Cisco Systems, Inc. subsidiary specializes on multi-factor authentication and are doing a great job running a WebAuthN demo site at https://webauthn.io/.
Registration
This illustrated guide is run using a Firefox in Windows 10. I've done this same thing with Chrome, Edge (the chromium one) and macOS Safari. It really doesn't differ that much from each other.
In every website, a one-time user registration needs to be done. This is how WebAuthN would handle the process.
Step 1: Enter the username you'd like to register as.
Step 2: Go for Register
Step 3: Your browser will need a confirmation for proceeding with registration.
The main reason for doing this is to make you, as the user, aware that this is not a login. Also the authenticator devices typically have limited space for authentication keys available. For example: Yubikeys have space for 25 keys in them. The bad thing about limited space is because of high level of security yielding low level of usability. You cannot list nor manage the keys stored. What you can do is erase all of them clean.
Step 4: Insert your authenticator into your computing device (PC / Mac / mobile).
If authenticator is already there, this step will not be displayed.
Step 5: Enter your authenticator PIN-code.
If you have not enabled the second factor, this step won't be displayed.
To state the obvious caveat here, anybody gaining access to your authenticator will be able to log in as you. You really should enable the PIN-code for increased security.

Step 6: Touch the authenticator.
The physical act of tringgering the registration is a vital part of WebAuthN. A computer, possibly run by a malicious cracker, won't be able to use your credentials without human interaction.

Step 7: You're done! Now you have successfully registered.
Best part: No passwords!
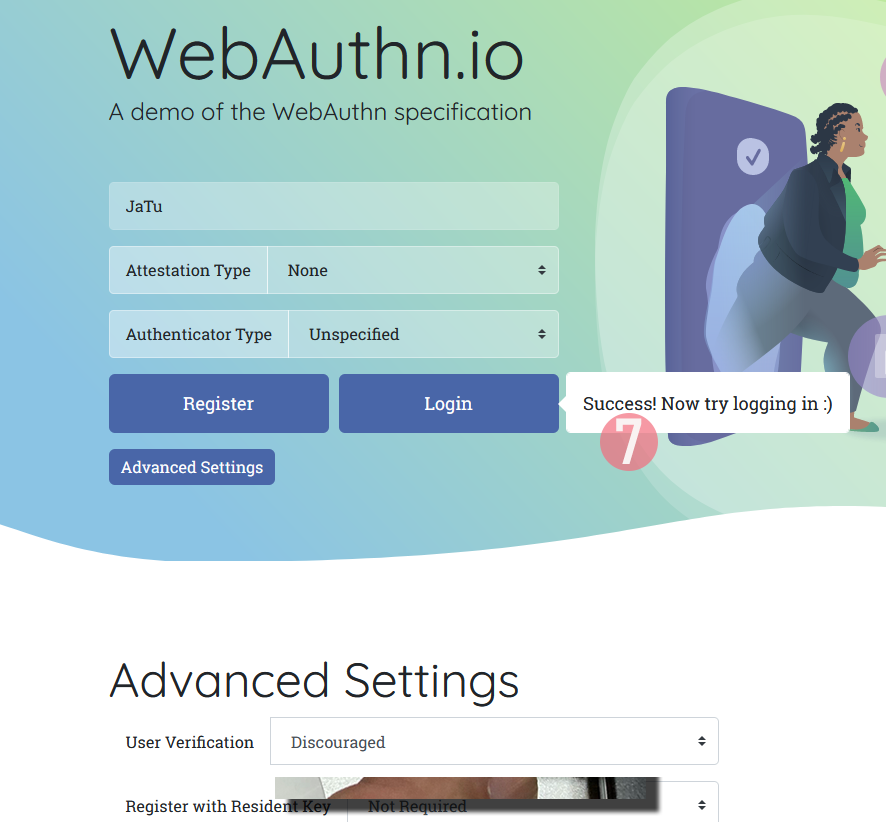
In this Duo Security test site, the sandbox will be raked on daily basis. Natually on a real non-demo site your information will be persisted much longer. Also note how your contact information like, E-mail address, mobile number or such wasn't asked. A real site would obviously query more of your personal details. Secondly, WebAuthN best practice is to have multiple authenticators associated with your user account. If you happen to misplace the device used initially for registration, having a backup(s) is advisable.
Next, let's see how this newly created user account works in a practical login -scenario.
Login
Step 1: Enter the username you'd like to log in as.
Step 2: Go for Login

Step 3: Insert your authenticator into your computing device (PC / Mac / mobile).
If authenticator is already there, this step will not be displayed.

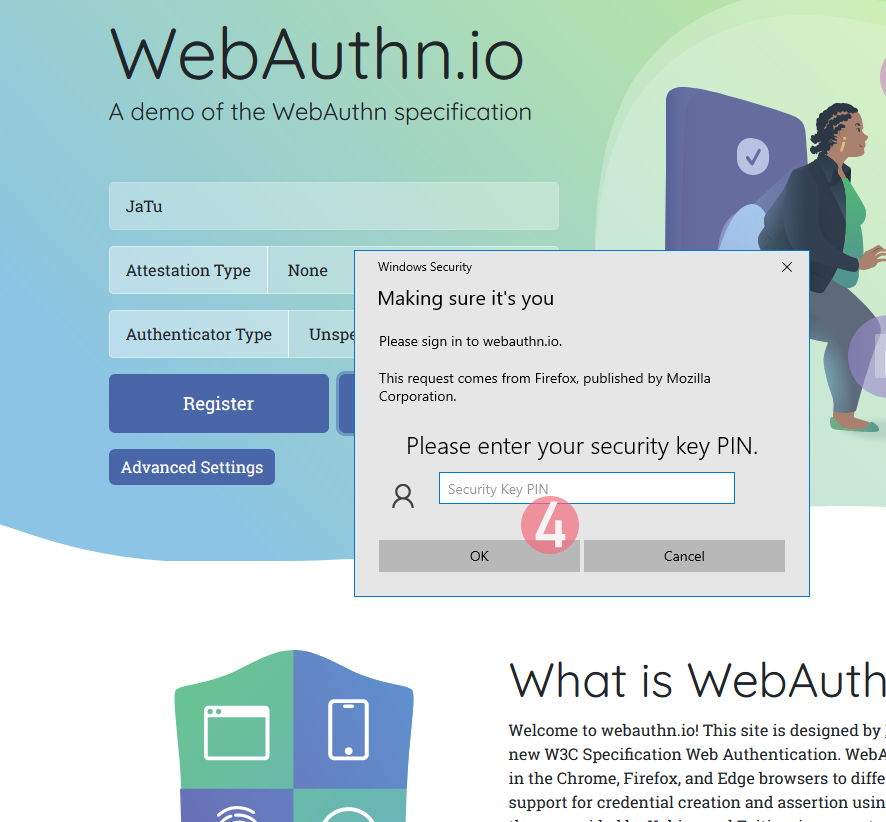
Step 4: Enter your authenticator PIN-code.
If you have not enabled the second factor, this step won't be displayed.
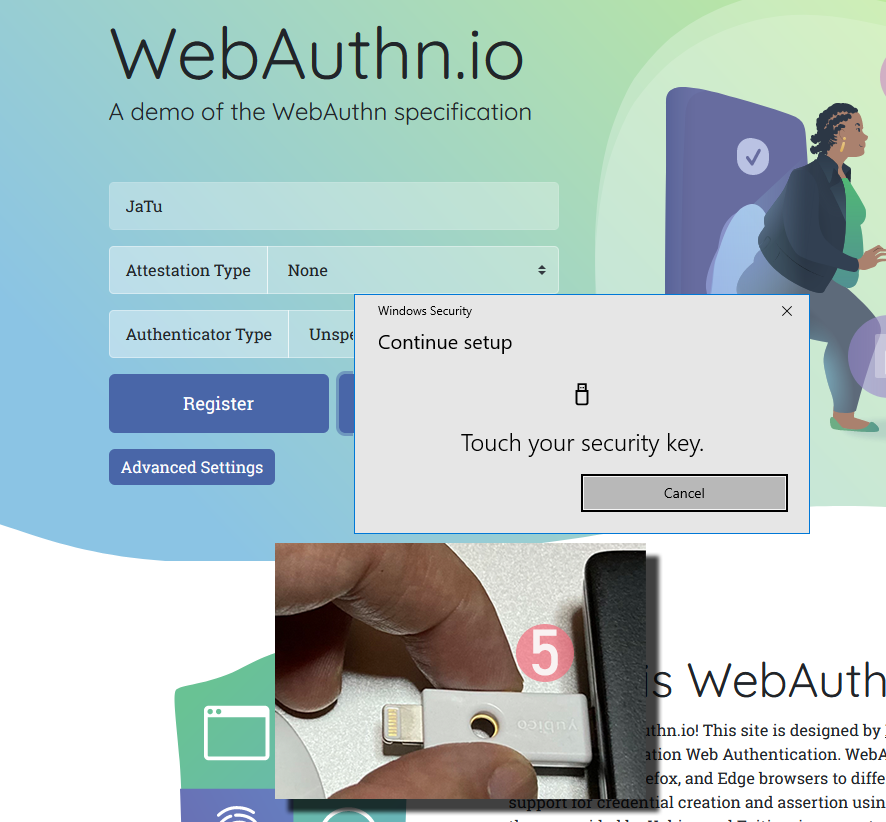
Step 5: Touch the authenticator.
Again, human is needed here to confirm the act of authentication.
Step 6: You're done! Now you have successfully logged in.
Best part: No passwords!
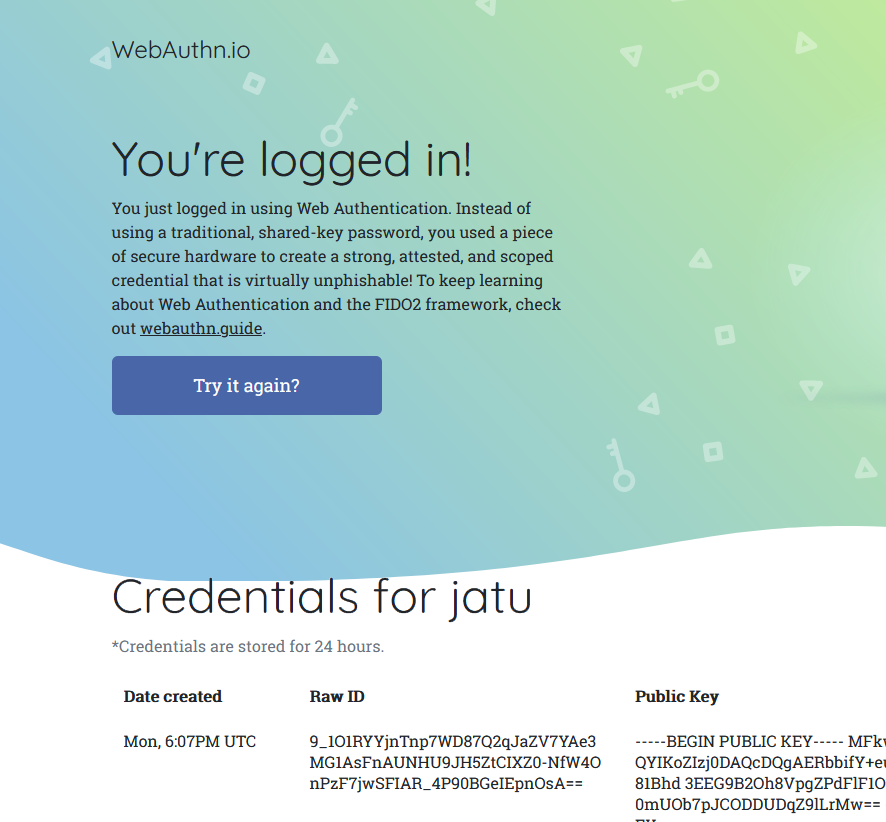
Note how the public key can be made, well... public. It really doesn't make a difference if somebody else gets a handle of my public key.
Closer look into The Public Key
As established in the previous post, you can not access the private key. Even you, the owner of the authenticator device, can not access that information. Nobody can lift the private key, possibly without you knowing about it. Just don't lose the Yubikey.
Public-part of the key is known and can be viewed. The key generated by my Yubikey in PEM-format is as follows:
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAERbbifY+euxnszcMis99CsnH81Bhd
3EEG9B2Oh8VpgZPdFlF1OQ8FEbfuSxbbAK+l0mUOb7pJCODDUDqZ9lLrMw==
-----END PUBLIC KEY-----
Popping the ASN.1 cork with a openssl ec -pubin -noout -text -in webauthn-pem.key will result:
read EC key
Public-Key: (256 bit)
pub:
04:45:b6:e2:7d:8f:9e:bb:19:ec:cd:c3:22:b3:df:
42:b2:71:fc:d4:18:5d:dc:41:06:f4:1d:8e:87:c5:
69:81:93:dd:16:51:75:39:0f:05:11:b7:ee:4b:16:
db:00:af:a5:d2:65:0e:6f:ba:49:08:e0:c3:50:3a:
99:f6:52:eb:33
ASN1 OID: prime256v1
NIST CURVE: P-256
From that we learn, the key-pair generated is an ECDSA 256-bit. Known aliases for that are secp256r1, NIST P-256 and prime256v1. That weird naming means elliptic curves, aka. named curves.
For those into math, the actual arithmetic equation of secp256r1 -named curve can be viewed in an open-source book by Svetlin Nakov, PhD at https://cryptobook.nakov.com/. All the source code in this freely available book are at https://github.com/nakov/practical-cryptography-for-developers-book. The mathemathical theory how WebAuthN signs the messages is described in detail at https://cryptobook.nakov.com/digital-signatures/ecdsa-sign-verify-messages.
Back to those "pub"-bytes. Reading RFC5480 indicates out of those 65 bytes, the first one, valued 04, indicates this data being for an uncompressed key. With that information, we know rest of the bytes are the actual key values. What remains is a simple act of splitting the remaining 64 bytes into X and Y, resulting two 32-byte integers in hex:
X: 45b6e27d8f9ebb19eccdc322b3df42b271fcd4185ddc4106f41d8e87c5698193
Y: dd165175390f0511b7ee4b16db00afa5d2650e6fba4908e0c3503a99f652eb33
A simple conversion with bc will result in decimal:
X: 31532715897827710605755558209082448985317854901772299252353894644783958819219
Y: 100000572374103825791155746008338130915128983826116118509861921470022744730419
Yes, that's 77 and 78 decimal numbers in them. Feel free to go after the prime number with that public information! 
Finally
The mantra is: No passwords.
With WebAuthN, you'll get hugely improved security with multiple authentication factors built into it. What we need is this to spread and go into popular use!
WebAuthN - Passwordless registration and authentication of users
Monday, September 13. 2021
WebAuthN, most of you have never heard of it but can easily understand it has something to do with authenticating "N" in The Web. Well, it is a standard proposed by World Wide Web Consortium or ![]() . In spec available at https://www.w3.org/TR/webauthn/, they describe WebAuthN as follows:
. In spec available at https://www.w3.org/TR/webauthn/, they describe WebAuthN as follows:
Web Authentication:
An API for accessing Public Key Credentials
Level 2W3C Recommendation, 8 April 2021
What motivates engineers into inventing an entirely new form of authenticating end users to web services is obvious. Passwords are generally a bad idea as humans are not very good using memorized secrets in multiple contexts. Your password is supposed to be a secret, but when it leaks from a website and is made public for The World to see your secret isn't a secret anymore. Using a different password for every possible website isn't practical without proper tooling (which many of you won't utilize for number of reasons). As all this isn't new and I've already covered it numerous posts, example Passwords - Part 3 of 2 - Follow up, this time I'm not going there.
Instead, let's take a brief primer on how authentication works. To lay some background for WebAuthN, I'm introducing three generations of authentication. Honestly it is weird how I cannot find anybody's previous work on how to define 1st gen or 2nd gen auth mechanisms. As usual, if you want to have something done properly, you'll have to do it by yourself. I'm defining the generations of authentication techniques here.
First Generation: Password - a memorized secret
This is your basic password-scenario, something most of us know and understand easily. In the picture below is something I drew to illustrate the flow of events during user authentication. On the left is you, the user. You want to login to a website you've registered before. As anybody having access to The Internet, anywhere in the globe, they can show up and claim to be you, the mechanism to identify you being YOU is with the secret you chose during registration process, aka. your password.
Process goes as follows: You open a web browser, go to a known address of the website, when authentication is requested, using a keyboard (touch screen or a real keyboard) enter your password credential to complete the claim of you being you. Finally as your password matches what the website has in its records, you are granted access and go happily forward.
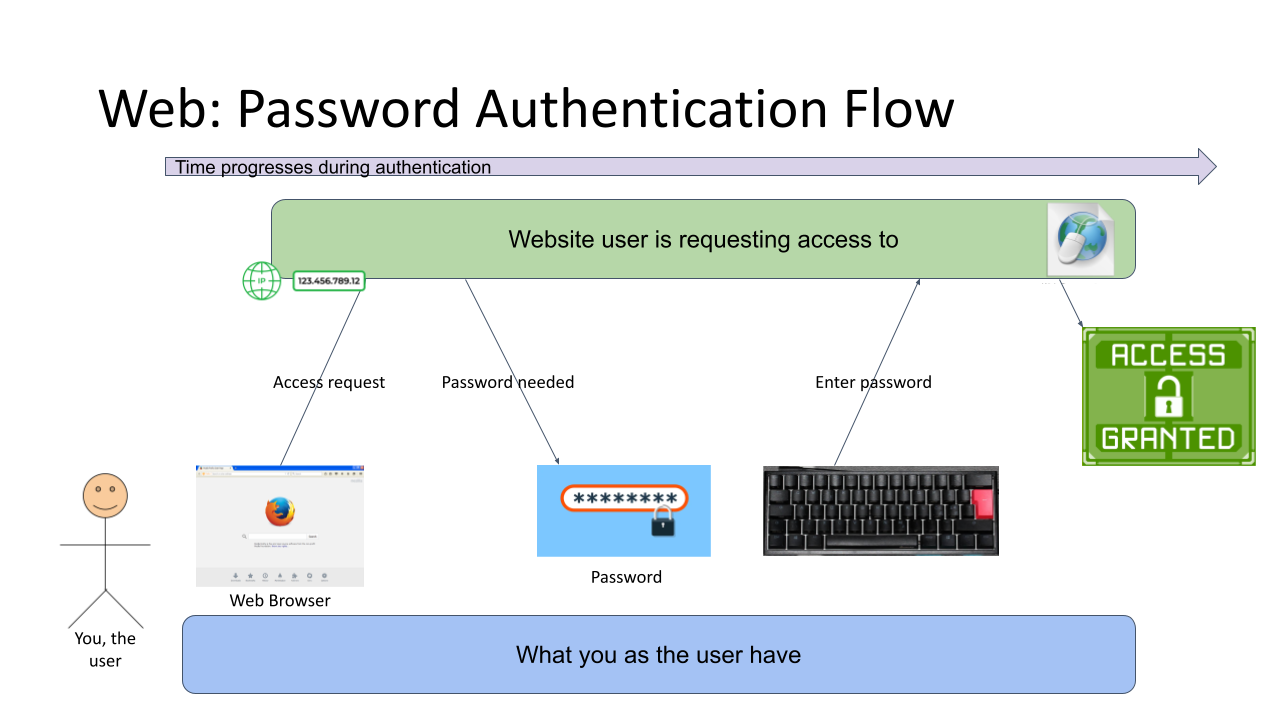
The obvious weakness in this very common authentication mechanism has already been explained. What if somebody gets your password? They saw you typing it, or found the yellow post-it sticker next to your monitor, or ... many possibilities of obtaining your secret, including a guess. To mitigate this, there are MFA of 2-FA to introduce a Multi-Factor Authentication (or Two-Factor), but for the sake of introducing this generation, we skip that. It's an add-on and doesn't really alter this most commonly used process.
It's the simplicity that made this original one the most popular method of authentication. Nothing special really needed and this approach kinda works. It won't resist much of an attack, but it works.
Second Generation: Public Key Infrastructure (PKI)
One of the most prominent attempts to stop using passwords is PKI. As this mechanism isn't widely used in The Web, note the difference for the 1st gen diagram, this is not web, this is Secure Shell, or SSH.
In reality, you can use SSH with passwords also, but it is typical for not to. Actually, I always (no exceptions!) disable password authentication in my servers by introducing PasswordAuthentication no into sshd_config. Simply by not using passwords, my security improves a lot.
Second reality check: In HTTP/1.1 you can use certificate (aka. PKI) authentication. However, on currently used HTTP/2 that is not possible. Quote: "[RFC7540] prohibits renegotiation after any application data has been sent. This completely blocks reactive certificate authentication in HTTP/2". So, that's effectively gone in the form used previously. And no, to those shouting "my national ID-card has an ISO-7816 -chip in it and I can use the certificate in it to authenticate!". That tech isn't based on any of the web standards. All nations invented their own stack of custom software attaching a running process in your computer to your browser's Security Device API. As this isn't even commonly used, this changes nothing and I'll stand behind my claim: In web there really isn't PKI-auth in use.
SSH authentication process goes as follows: On your computer (or mobile device), you open your SSH-client to enter a known server. Authentication is integral part of a connection and cannot really be bypassed. On authentication, you will get the server's identity as a response and your client will verify the address+signature -pair to a previously stored value to make sure the server is in fact The Server you have accessed before. Next your private key will be needed. You have generated this during "registration" process (in SSH there really isn't registration, but declaring the keys to be used can be considered one). Best practice is to have your private keys encrypted, so to access the key I need to enter a password (pass phrase) for decryption. Note the difference for the previous gen. here: the password I type, nor my private key does not leave my computer, only a data packet signed with my private key will. Given PKI-math, the server can verify my signature using the public key on that end. As signature matches, server has verified the claim of me being me and allows access.
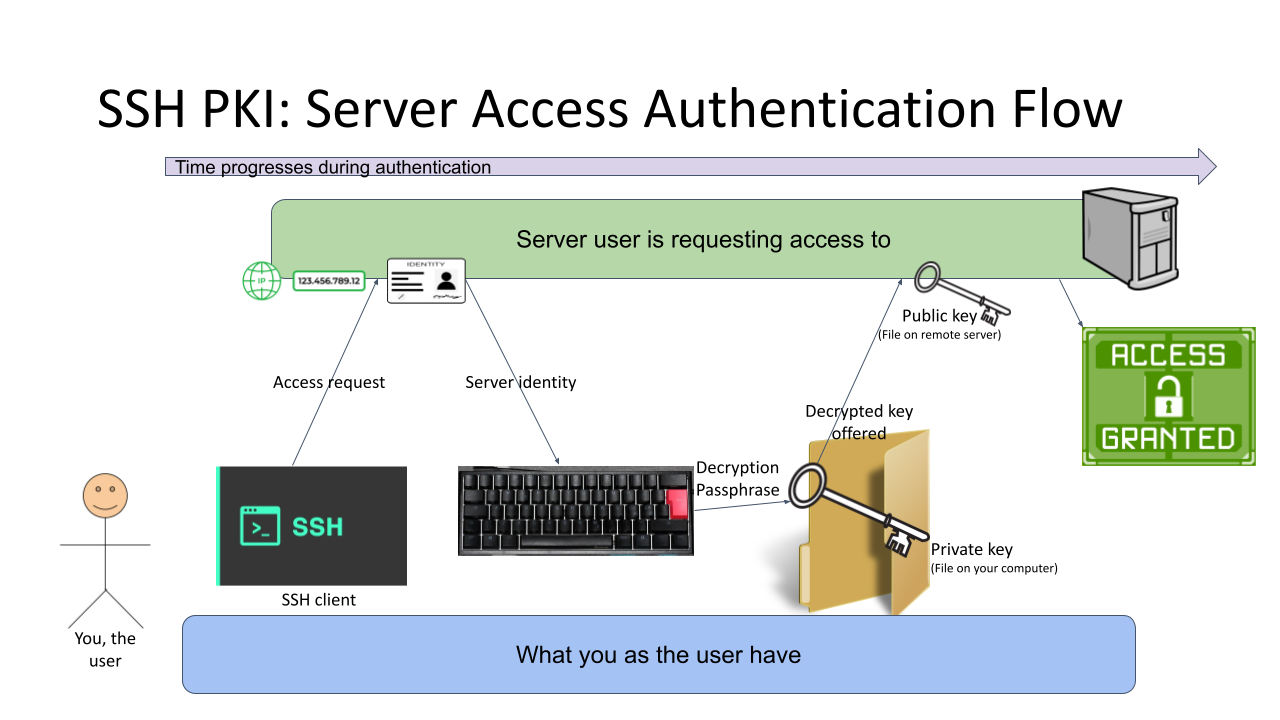
In general, this is very nice and safe approach. The introduction of server identity increases your security as a random party cannot claim to act as "The Server". Also the authentication mechanism used is a seriously thought/engineered and complex enough to withstand any brute-forcing or guesswork. Even if your private key would be encrypted with a super-easy passphrase, or not encrypted at all, it won't be easy for somebody else to mimic you. They really really really need to have your private key.
There is no real obvious weakness in this (besides this is not Web). What could be described as a "weakness" is the private key storage. What if it leaks? Your keys to "The Kingdom" are gone. Remember: the private keys should be encrypted to mitigate them being lost. However, your keys being lost/stolen is a lot less likely incident to happen in comparison of somebody guessing or harvesting your password from the server database. Even if you set your mind into generating a "poor" public/private key pair, in fact it is actually very secure. Much more secure than your default "123456" easily guessable password.
On the other hand, if your public key on the server side leaks, that's not a big deal. Servers do get hacked. Data does get stolen, but public is public. You can climb to a mountain and shout your public key for all to know (actually that's literally what GPG does). The math PKI uses in either RSA or ECDSA is considered really really very safe.
Third Generation: WebAuthN
Back to web with PKI. Building on top of first and second generations, there is an improvement: in WebAuthN the private key storage isn't a file in your computer. It's a FIDO2-compliant detachable hardware device. Note: in FIDO Alliance specs, the authenticator "device" can be a software running in your computer (or mobile phone, or whatever you're using as your personal computer). However, most typically deployed WebAuthN-solutions do use actual physical devices you can plug in and out of your computer. The authenticator devices don't have any batteries, are powered from the computer and are typically small enough to be stored in your pocket.
The authentication process goes as follows: You open a web browser, go to a known address of the website. On the website you choose to login and when authentication is requested by the server, it will send you its identification and a challenge as a response to your browser. The callenge will contain data signed by your public key. Obviously your public key was stored to the server during user registration process. As your browser will require help from the authenticator device, a connection will be made there. If your authenticator is protected by a PIN, a request to unlock is indicated by your browser. Using your keyboard, you punch in the PIN-code and your browser will pass on the challenge to the authenticator device. It will check the server's identification and see if it would have a private key in its storage to match that. If it does, it will signal your browser about the found private key. You choose to go forward with authentication on your browser and authenticator device will return the challenge with a signature added into it. Then your browser will deliver signed data over the Net, server on the other side will verify the signature and on successful match you're in! This entire process is a variation of 2nd gen PKI-authentication.
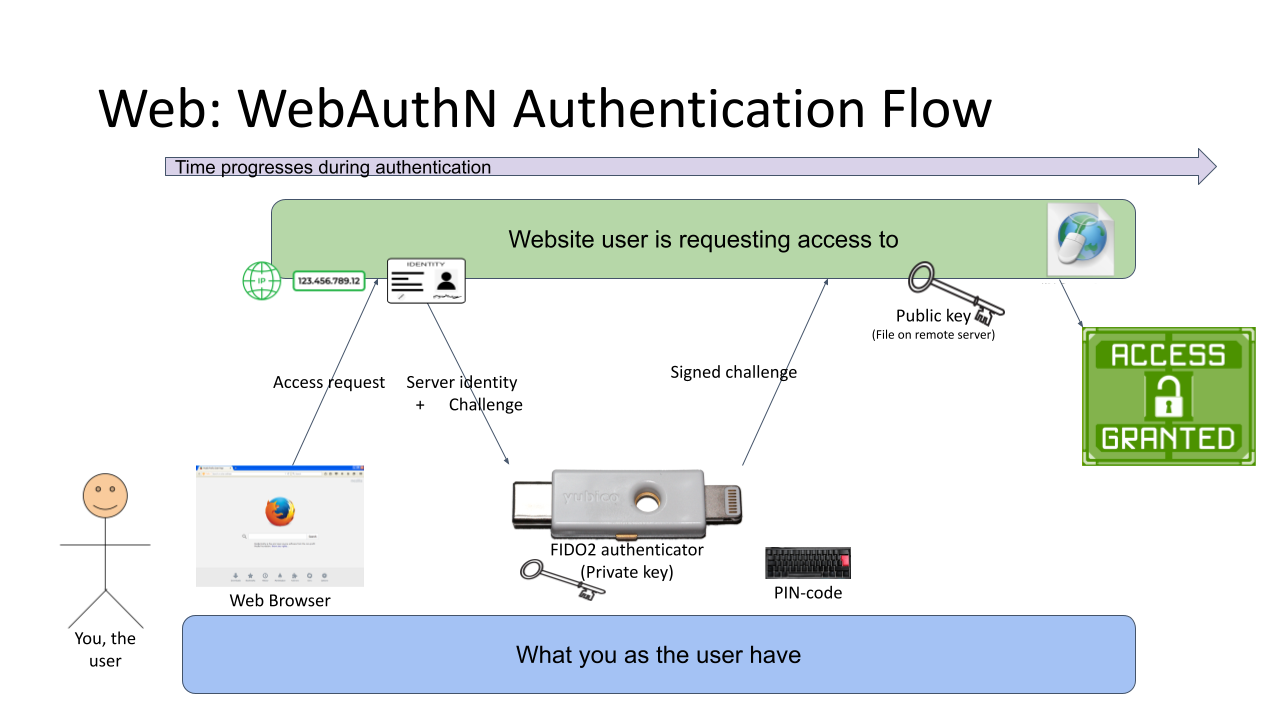
Drawback is obvious: you need to have the device at your hand to be able to log in. Most of regular users like you don't have a compatible FIDO2 authenticator at hand. If you do, on a failing scenario, what if you left the device at home? Or your dog ate it? Or you made an unfortuante mistake and dropped it into a toilet by accident. Well, good thing you thought of this and have configured a spare authenticator, right? Ok, you being a carefree fellow, you forgot where you placed it. At this point you are eventually locked out of the remote system, which is bad.
What's good is the fact that your private key cannot be stolen. Nobody, including you, don't know it nor can access it. All you can do with a device is to get a signed challenge (besides the obvious act of adding a new key during registration). Your security is standing on two factors, the private key stored into an unbreakable device and the fact that a PIN-code is needed on an attempt to access any of the data. That is pretty safe. Worst-case scenario is when your authenticator doesn't have PIN-code protection and somebody gets their hands on it. Then they can present themselves as you.
As WebAuthN is a new and good thing, the only reason it isn't widely used at this point is the need for a specific type of hardware device. These devices are commonly available and they aren't too expensive either. Single device can be used to authenticate into multiple sites, even. The avalability problem is simply because aren't too many manufacturers in existence yet.
Not to worry! This can be navigated around. Let's put on our future-goggles and look a bit ahead. What if "the device" needed here would be your mobile phone? Those things are commonly available and won't require anything else than operating system support and suitable software.
Practical WebAuthN
Enough theory! How does this work in real life?
Well, that's a topic for an another blog post. I'll investigate the USB-A/USB-C/Apple Lightning -solution in closer detail. Also the upcoming mobile device option will be discussed.
Decoding EU Digital COVID Certificate
Friday, August 6. 2021
If you live in EU, you most definitely have heard of COVID Passport.
Practically speaking, it is a PDF-file A4-sized when printed and can be folded into A6-pocket size. In Finland a sample would look like this:

What's eye-catching is the QR-code in the top right corner. As I'm into all kinds of nerdy stuff, I took a peek what's in it.
After reading some specs and brochures (like https://www.kanta.fi/en/covid-19-certificate) I started to tear this apart and deduced following:
- An A4 or the QR-code in it can be easily copied / duplicated
- Payload can be easily forged
- There is a claim: "The certificate has a code for verifying the authenticity"
My only question was: How is this sane! Why do they think this mechanism they designed makes sense?
QR-code
Data in QR-code is wrapped multiple times:
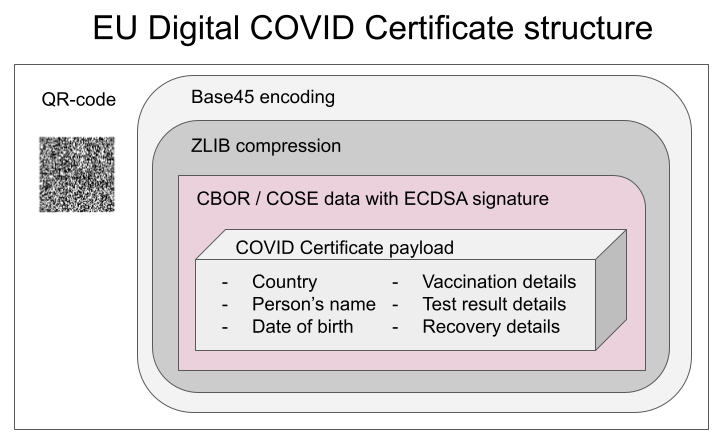
This CBOR Object Signing and Encryption (COSE) described in RFC 8152 was a new one for me.
Payload does contain very little of your personal information, but enough to be compared with your ID-card or passport. Also there is your vaccination, test and possible recovery from COVID statuses. Data structure can contain 1, 2 or 3 of those depending if you have been vaccinated or tested, or if you have recovered from the illness.
Python code
It's always about the details. So, I forked an existing git-repo and did some of my own tinkering. Results are at: https://github.com/HQJaTu/vacdec/tree/certificate-fetch
Original code by Mr. Hanno Böck could read QR-code and do some un-wrapping for it to reveal the payload. As I'm always interested in X.509, digital signatures and cryptography, I improved his code by incorporating the digital signature verification into it.
As CBOR/COSE was new for me, it took a while to get the thing working. In reality the most difficult part was to get my hands into the national public certificates to do some ECDSA signature verifying. It's really bizarre how that material is not made easily available.
Links:
- Swagger of DGC-gateway: https://eu-digital-green-certificates.github.io/dgc-gateway/
- This is just for display-purposes, this demo isn't connected to any of the national back-ends
- Sample data for testing verification: https://github.com/eu-digital-green-certificates/dgc-testdata
- All participating nations included
- QR-codes and raw-text ready-to-be-base45-decoded
- Payload JSON_schema: https://github.com/ehn-dcc-development/ehn-dcc-schema/
- Just to be clear, the payload is not JSON
- However, CBOR is effectively binary JSON
- List of all production signature certificates: https://dgcg.covidbevis.se/tp/
- Austrian back-end trust-list in JSON/CBOR: https://greencheck.gv.at/api/masterdata
- Swedish back-end trust-list in CBOR: https://dgcg.covidbevis.se/tp/trust-list
- The idea is for all national back-ends to contain everybody's signing certificate
Wallet
Mr. Philipp Trenz from Germany wrote a website to insert your QR-code into your Apple Wallet. Source is at https://github.com/philipptrenz/covidpass and the actual thing is at https://covidpass.eu/
Beautiful! Works perfectly.
Especially in Finland the government is having a vacation. After that they'll think about starting to make plans what to do next. Now thanks to Mr. Trenz every iOS user can have the COVID Certificate in their phones without government invovement.
Finally
Answers:
- Yes, duplication is possible, but not feasible in volume. You can get your hands into somebody else's certificate and can present a proof of vaccination, but verification will display the original name, not yours.
- Yes, there is even source code for creating the QR-code, so it's very easy to forge.
- Yes, the payload has a very strong elliptic curve signature in it. Any forged payloads won't verify.
Ultimately I was surprised how well designed the entire stack is. It's always nice to see my tax-money put into good use. I have nothing negative to say about the architecture or technologies used.
Bonus:
At very end of my project, I bumped into Mr. Mathias Panzenböck's code https://github.com/panzi/verify-ehc/. He has an excellent implementation of signature handling, much better than mine. Go check that out too.
Passwords - Part 3 of 2 - Follow up
Thursday, June 17. 2021
This is part three of my two-part post. My thoughts on passwords in general are here and about leaked passworeds here.
I'm writing this to follow-up on multiple issues covered in previous parts. Some of this information was available at the time of writing but I just had not found it in time, some info was published afterwards but was closely related.
Troy Hunt's thoughts on RockYou2021
His tweet https://twitter.com/troyhunt/status/1402358364445679621 says:
Unlike the original 2009 RockYou data breach and consequent word list, these are not “pwned passwords”; it’s not a list of real world passwords compromised in data breaches, it’s just a list of words and the vast majority have never been passwords
Mr. Hunt is the leading expert on leaked passwords, so I'm inclined to take his word about it. Especially when he points the RockYou2021 "leak" to contain CrackStation's Password Cracking Dictionary. Emphasis: dictionary. The word-list will contain lists of words (1,493,677,782 words, 15GB) in all known languages available. That list has been public for couple of years.
IBM Security survey
Press release Pandemic-Induced Digital Reliance Creates Lingering Security Side Effects. Full report PDF.
In number of visualizations contained in the report, there is this one about password re-use:
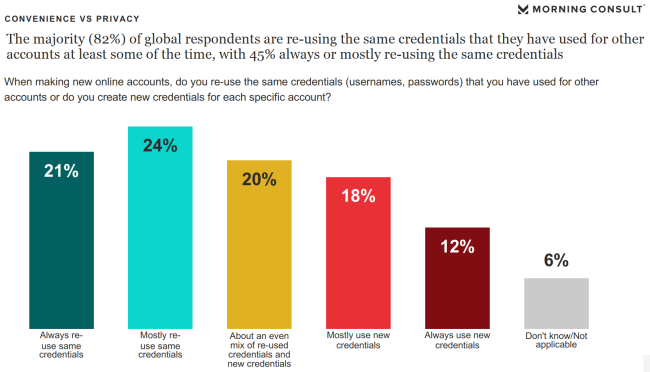
65% of participants are using same passwords always, mostly or often. That's seriously bad! 
However, this is nothing new. It is in-line with other surveys, research and available data.
STOP re-using your passwords. NOW!
If you aren't, educate others about the dangers. Help them set up password managers.
Microsoft
ZDnet article Microsoft's CISO: Why we're trying to banish passwords forever descibes how Microsoft will handle passwords.
1: Employees at Microsoft don't have to change their passwords every 71 days.
Microsoft claims that password expiration requirements do more harm than good because they make users select predictable passwords, composed of sequential words and numbers, which are closely related to each other. Additionally, Microsoft claims that password expiration requirements limit containment because cybercriminals almost always use credentials as soon as they compromise them.
Nothing new there, except huge corporation actually doing it. This policy is described in NIST 800-63B section 5.1.1.2 Memorized Secret Verifiers, which states following:
Verifiers SHOULD NOT require memorized secrets to be changed arbitrarily (e.g., periodically).
However, verifiers SHALL force a change if there is evidence of compromise of the authenticator.
Also, multiple sources back that up. Example: Security Boulevard article The High Cost of Password Expiration Policies
2: "Nobody likes passwords"
A direct quote from Microsoft CISO Bret Arsenault:
Because nobody likes passwords.
You hate them, users hate them, IT departments hate them.
The only people who like passwords are criminals – they love them
I could not agree more.
3: End goal "we want to eliminate passwords"
Even I wrote, this can not be done in near future. But let's begin the transition! I'm all for it.
The idea is to use alternate means of authentication. What Microsoft is using is primarily biometrics. That's the same thing you'd be doing with your phone, but do the same with your computer.
Doing passwords correctly
When talking about computers, security, information security, passwords and so on, it is very easy to paint a gloom future and emphasize all the bad things. Let's end this with a positive note.
Auth0 blog post NIST Password Guidelines and Best Practices for 2020 has the guidelines simplified:
-
Length > Complexity: Seconding what I already wrote, make your passwords long, not necessarily complex. If you can, do both! If you have to choose, longer is better.
-
Eliminate Periodic Resets: This has already been covered, see above. Unfortunately end-users can not do anything about this, besides contact their admins and educate them.
-
Enable “Show Password While Typing”: Lot of sites have the eye-icon to display your password, it reduces typos and makes you confident to use long passwords. Again, nothing for end-user to do. The person designing and writing the software needs to handle this, but you as an end-user can voice your opinion and demand to have this feature.
-
Allow Password “Paste-In”: This is a definite must for me, my passwords are very long, I don't want to type them! Yet another, end users can not help this one, sorry.
-
Use Breached Password Protection: Passwords don't need to be complex, but they must be unique. Unique as not in the RockYou2021 8.4 billion words list. This is something you can do yourself. Use an unique password.
-
Don’t Use “Password Hints”: Huh! These are useless. If forced to use password hint, I never enter anything sane. My typical "hint" is something in fashion "the same as always".
-
Limit Password Attempts: Disable brute-force attempts. Unfortunately end-users can not do anything about this. If the system you're using has unlimited non-delayed login attempts, feel free to contact admins and educate them.
-
Use Multi-Factor Authentication: If option to use MFA is available, jump to it! Don't wait.
-
Secure Your Databases: During design and implementation every system needs to be properly hardened and locked-down. End users have very little options on determining if this is done properly or not. Sorry.
-
Hash Users’ Passwords: This is nearly the same as #9. The difference is, this is about your password, it needs to be stored in a way nobody, including the administators, have access to it.
Finally
All the evidence indicates we're finally transitioning away from passwords.
Be careful out there!
Passwords - Part 2 of 2 - Leaked passwords
Monday, June 14. 2021
This is the sencond part in my passwords-series. It is about leaked passwords. See the previous one about passwords in general.
Your precious passwords get lost, stolen and misplaced all the time. Troy Hunt runs a website Have I been Pwned (pwn is computer slang meaning to conquer to gain ownership, see PWN for details). His service typically tracks down your email addresses and phone numbers, they leak even more often than your passwords, but he also has a dedicated section for passwords Pwned Passwords. At the time of writing, his database has over 600 billion (that's 600 thousand million) known passwords. So, by any statistical guess, he has your password. If you're unlucky, he has all of them in his system. The good thing about Mr. Hunt is, he's one of the good guys. He wants to educate and inform people about their information being leaked to wrong hands.
8.4 billion leaked passwords in a single .txt-file
Even I have bunch of leaked and published sets of passwords. Couple days ago alias kys234 published a compilation of 8.4 billion passwords and made that database publicly available. More details are at RockYou2021: largest password compilation of all time leaked online with 8.4 billion entries and rockyou2021.txt - A Short Summary. Mr. Parrtridge even has the download links to this enormous file. Go download it, but prepare 100 GiB of free space first. Uncompressed the file is huge.
How long are the leaked passwords?
From those two articles, we learn that there are plenty of passwords to analyse. As I wrote in my previous post, my passwords are long. Super-long, as in 60-80 characters. So, I don't think any of my passwords are in the file. Still, I was interested in what would be the typical password lenght.
Running a single-liner (broken to multiple lines for readability):
perl -ne 'chomp; ++$cnt; $pwlen=length($_);
if ($lens{$pwlen}) {++$lens{$pwlen};} else {$lens{$pwlen}=1;}
END {printf("Count: %d", $cnt); keys(%lens);
while(my($k, $v) = each(%lens)) {printf("Len %d: %d\n", $k, $v);}}'
rockyou2021.txt
Will result in following:
Count: 8459060239
Len 6: 484236159
Len 7: 402518961
Len 8: 1107084124
Len 9: 1315444128
Len 10: 1314988168
Len 11: 1071452326
Len 12: 835365123
Len 13: 613654280
Len 14: 436652069
Len 15: 317146874
Len 16: 215720888
Len 17: 131328063
Len 18: 97950285
Len 19: 65235844
Len 20: 50282947
Visualization of the above table:

It would be safe to say, typical password is 9 or 10 characters short. Something a human being can remember and type easily into a login prompt.
Based on leaked material, how long a password should be?
The next obvious question is: Well then, if not 10 characters, how long the password should be?
Instant answer is: 21 characters. The file doesn't contain any of those.
Doing little bit of statistical analysis: If you're at 13 characters or more, your password is in the top-25%. At 15 or more, youre in top-7%. So, the obvious thing is to aim for 15 characters, no less than 13.
Given the lack of super-long passwords, I went a bit further with Rstudio. I went for the assumption, the password lenghts would form a gaussian bell curve. I managed to model the data points into a semi-accurate model which unfortunately for me is more inaccurate at the 18, 19, 20 characters than with the shorter ones.
If you want to improve my model, there is the human-readable HTML-version of R notebook. Also the R MD-formatted source is available.
Here is a plot of my model:
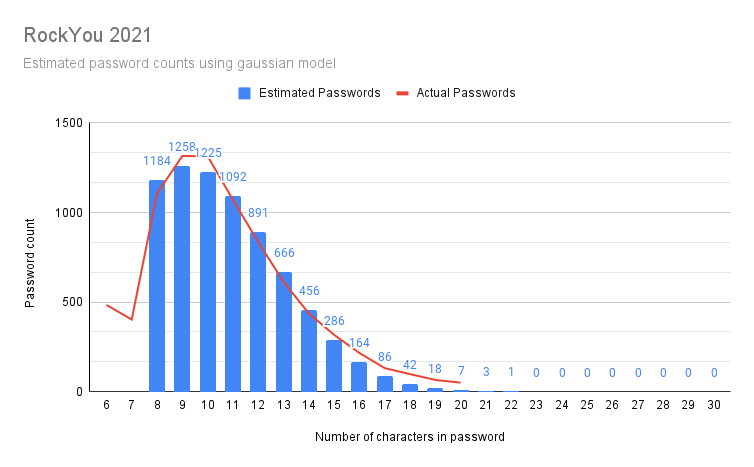
Red line is the actual measured data points. Blue bars are what my model outputs.
Result is obvious: longer is better! If you're at 30 characters or more, your passwords can be considered unique. Typical systems crypt or hash the passwords in storage, making it is not feasible to brute-force a 30 char password. Also the reason why leaked RockYou2021 list doesn't contain any password of 21 or more characters: THEY ARE SO RARE!
Looks like me going for 60+ chars in my passwords is a bit over-kill. But hey! I'm simply future-proofing my passwords. If/when they leak, they should be out of brute-force attack, unless a super-weak crypto is used.
Wrap up
The key takeaways are:
- Password, a memorized secret is archaic and should be obsoleted, but this cannot be achieved anytime soon.
- Use password vault software that will suit your needs and you feel comfortable using.
- Never ever try to remember your passwords!
- Make sure to long passwords! Any password longer than 20 characters can be considered a long one.
Passwords - Part 1 of 2
Sunday, June 13. 2021
In computing, typing a password from keyboard is the most common way of authenticating an user.
NIST Special Publication 800-63B - Digital Identity Guidelines, Authentication and Lifecycle Management in its section 5.1.1 Memorized Secrets defines password as:
A Memorized Secret authenticator — commonly referred to as a password or, if numeric, a PIN — is a secret value intended to be chosen and memorized by the user.
Note how NIST uses the word "authenticator" as general means of authentication. A "memorized authenticator" is something you remember or know.
Wikipedia in its article about authentication has more of them factors:
- Knowledge factors: Something the user knows
- password, partial password, pass phrase, personal identification number (PIN), challenge response, security question
- Ownership factors: Something the user has
- wrist band, ID card, security token, implanted device, cell phone with built-in hardware token, software token, or cell phone holding a software token
- Inference factors: Something the user is or does
- fingerprint, retinal pattern, DNA sequence, signature, face, voice, unique bio-electric signals
Using multiple factors to log into something is the trend. That darling has multiple acronyms 2-FA (for two factor) or MFA (multi-factor). Also notable single-factor authentication method is to open the screen-lock of a cell-phone. Many manufacturers rely on inference factor to allow user access into a hand-held device. Fingerprint or facial recognition are very common.
Since dawn on mankind, humans have used passwords, a knowledge factor. Something only select persons would know. With computers, it began in MIT, where Mr. Fernando Corbató introduced it the first time. And oh boy! Have we suffered from that design choice ever since. To point out the obvious flaw in my statement: Nobody has shown us anything better. Over 70 years later, we're still using passwords to get into our systems and software as there is an obvious lack of good alternative.
SSH - Practical example
Going for a bit deeper into practical authentication: SSH - Secure Shell, the protocol used to access many modern computer systems when HTTP/HTTPS doesn't cut it.
Borrowing figure 2-2 from chapter 2.4. Authentication by Cryptographic Key of the book SSH: The Secure Shell - The Definite Guide:
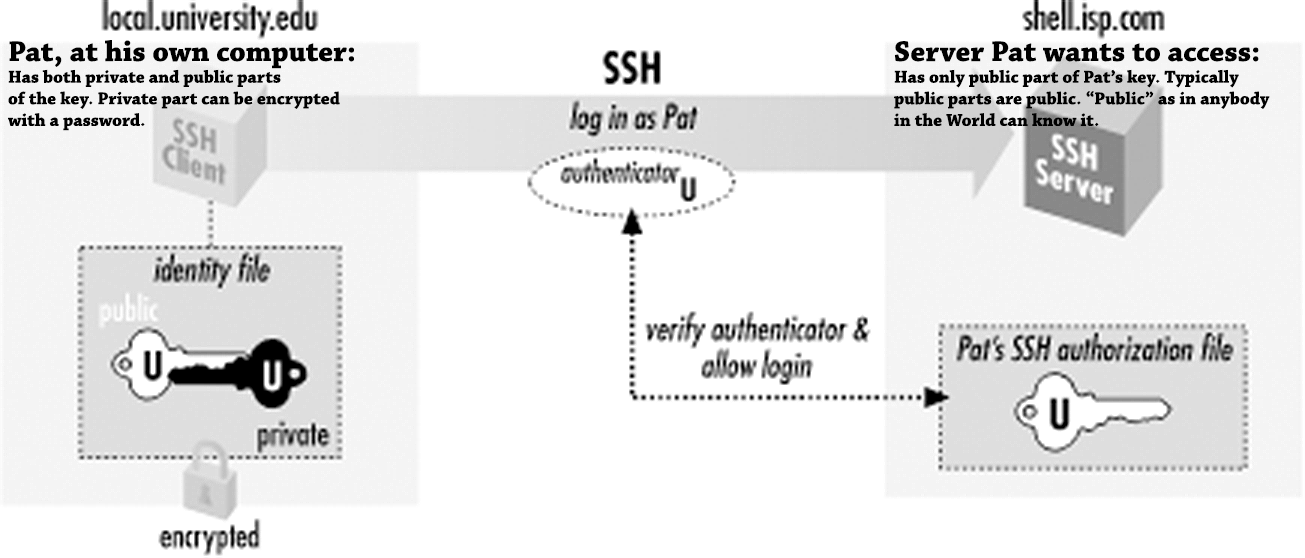
This figure depicts an user, Pat. To access a server shell.isp.com Pat will need a key. In SSH the key is a file containing result of complex mathematical operation taking randomness as input and saving the calculated values into two separate files. The file called "public key" must be stored and available on the server Pat is about to access. The second file "private key" must be kept private and in no circumstances nobody else must have access to results of the math. Having access to the set of files is an ownership factor. If Pat would lose access to the file, it wouldn't be possible to access the server anymore.
In this case Pat is a security conscious user. The private key has been encrypted with a password. Authentication process will require the result of the math, but even if the file would leak to somebody else, there is a knowledge factor. Anybody wanting to access the contents must know the password to decrypt it.
That's two-factor authentication in practice.
Traditional view of using passwords
Any regular Joe or Jane User will try to remember his/her passwords. To actually manage that, there can be a limited set of known passwords. One, two or three. More than four is not manageable.
When thinking about the password you chose, first check You Should Probably Change Your Password! | Michael McIntyre Netflix Special, or at least read the summary from Cracking Passwords with Michael McIntyre. Thinking of a good password isn't easy!
As Mr. McIntyre put it, many systems require the password to be complex ones. Xkcd #936 has a cartoon about it:
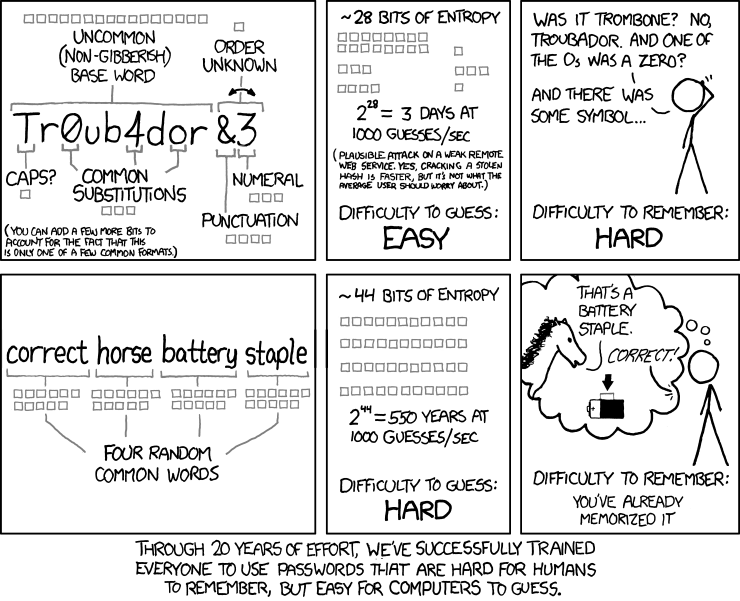
You may remember something long enough, but you won't remember many of them. Especially when there are tons of complex instructions on selecting the password. The NIST 63B in section 5.1.1.2 Memorized Secret Verifiers states following:
When processing requests to establish and change memorized secrets, verifiers SHALL compare the prospective secrets against a list that contains values known to be commonly-used, expected, or compromised.
For example, the list MAY include, but is not limited to:
- Passwords obtained from previous breach corpuses.
- Dictionary words.
- Repetitive or sequential characters (e.g. ‘aaaaaa’, ‘1234abcd’).
- Context-specific words, such as the name of the service, the username, and derivatives thereof.
Those four are only the basic requirements. Many systems have a set of rules of their own you must comply. Very tricky subject, this one.
My view on passwords
The attempt of trying to remember passwords or PIN-codes is futile. The entire concept of user simply storing a random(ish) word into brain and being able to type it via keyboard will eventually fail. The fact this will fail is the one fact bugging me. Why use something that's designed not to work reliably every time!
How I see password authentication is exactly like Pat's SSH-key. He doesn't know the stored values in his SSH private and public keys. He just knows where the files are and how to access them. In fact, he doesn't even care what values are stored. Why would he! It's just random numbers generated by a cryptographic algorithm. Who in their right mind would try to memorize random numbers!
My view is: a person needs to know (knowledge factor) exactly two (2) passwords:
- Login / Unlock the device containing the password vault software
- Decrypt password for vault software storing all the other passwords into all the other systems, websites, social media, work and personal, credit cards, insurance agreement numbers, and so on
Nothing more. Two passwords is manageable. Both of them don't need to be that long or complex, you will be entering them many times a day. The idea is not to use those passwords in any other service. If either of those two passwords will leak, there is only yourself to blame.
My own passwords
Obviously I live by the above rule. I have access (or had access at one point of time) to over 800 different systems and services. Yes, that's eight hundred. Even I consider that a lot. Most regular people have dozen or so passwords.
As already stated: I don't even care to know what my password to system XYZ is. All of my passwords are randomly generated and long or very long. In my password vault, I have 80+ character passwords. To repeat: I do not care what password I use for a service. All I care is to gain access into it when needed.
There are two pieces of software I've vetted and have my seal-of-approval of password storage: Enpass (https://www.enpass.io/) and BitWarden (https://bitwarden.com/). I've had numerous (heated) conversations with fans of such software products as Keepass, Lastpass, and so on. They are crap! I don't need them and won't be using them. My first password vault was SplashID (https://splashid.com/), but they somehow fell out of my radar. They were secure and all, but lack of flexibility and slow update cycle made me discontinue using them.
In case of my vault file leaking, to make it very difficult to crack open my precious data from SQLite Encryption Extension (SEE) AES-256 encrypted file there is a two-factor authentication in it. Anybody wanting access needs to know the encryption password and have the key-file containing a random nonce used to encrypt the vault.
Future of passwords
Using passwords is not going anywhere soon. A lot of services have mandatory or semi-mandatory requirement for multiple factors. Also additional security measures on top of authentication factors will be put into place. As an example user's IP-address will be saved and multiple simultaneous logins from different addresses won't be allowed. Second example: user's access geographic location will be tracked and any login attempts outside user's typical location will require additional authentication factors.
Passwords leak all the time and even passwords stored encrypted have been decrypted by malicious actors. That combined into the fact humans tend to use same passwords in multiple systems, when somebody has one of your passwords, the likelihood of gaining access to one of your accounts jumps a lot. In the net there are tons of articles like Why Is It So Important to Use Different Passwords for Everything? As doing that is a lot of hassle, many of you won't do it.
Cell phones or USB/Bluetooth dongles for authentication will gain popularity in the future, but to actually deploy them into use will require a professional. Organizations will do that, not home users.
Next part in my passwords-series is about leaked passwords.
Google Drive spam
Friday, April 2. 2021
A completely new type of spam has been flooding my mailbox. Ok, not flooding, but during past week I've got 7 different ones. The general idea for this spam delivery method is for the spam to originate from Google. How in detail the operation works, is to either exploit some innocent person's Google Account or create a ton of brand new Google Accounts to be used briefly and then thrown away. What the scammers do with the account is on Google Drive they'll create a presentation. There is no content in the presentation, it will be completely empty and then they'll share the document with me. Ingenious!
Shared presentation looks like this (hint: its completely blank):
The trick is in the comment of the share. If you add a new user to work on the same shared file, you can add own input. These guys put some spam into it.
When the mail arrives, it would contain something like this:
This approach will very likely pass a lot of different types of spam-filtering. People work with shared Google Drive documents all the time as their daily business and those share indications are not spam, its just day-to-day business for most.
Highlights from the mail headers:
Return-Path: <3FDxcYBAPAAcjvttlu0z-uvylws5kvjz.nvvnsl.jvt@docos.bounces.google.com>
Received-SPF: Pass (mailfrom) identity=mailfrom;
client-ip=209.85.166.198; helo=mail-il1-f198.google.com;
envelope-from=3fdxcybapaacjvttlu0z-uvylws5kvjz.nvvnsl.jvt@docos.bounces.google.com;
receiver=<UNKNOWN>
DKIM-Filter: OpenDKIM Filter v2.11.0 my-linux-box.example.com DF19A80A6D5
Authentication-Results: my-linux-box.example.com;
dkim=pass (2048-bit key) header.d=docs.google.com header.i=@docs.google.com header.b="JIWiIIIU"
Received: from mail-il1-f198.google.com (mail-il1-f198.google.com [209.85.166.198])
(using TLSv1.3 with cipher TLS_AES_128_GCM_SHA256 (128/128 bits)
key-exchange X25519 server-signature RSA-PSS (4096 bits) server-digest SHA256)
(No client certificate requested)
by my-linux-box.example.com (Postfix) with ESMTPS id DF19A80A6D5
for <me@example.com>; Thu, 25 Mar 2021 09:30:30 +0200 (EET)
Received: by mail-il1-f198.google.com with SMTP id o7so3481129ilt.5
for <me@example.com>; Thu, 25 Mar 2021 00:30:30 -0700 (PDT)
Reply-to: No Reply <p+noreply@docs.google.com>/code>
Briefly for those not fluent with RFC 821:
Nothing in the mail headers would indicate scam, fraud or even a whiff of spam. It's a fully legit, digitally signed (DKIM) email arriving via encrypted transport (TLS) from a Google-designated SMTP-server (SPF),
Given trusted source of mail, the only feasible attempt to detect this type of spam is via content analysis. Note: as an example of detecting and blocking unsolicited email, I've past written my thoughts how easy it is to block spam.
Well, until now it was. Darn!
Tracking your location via Mobile network
Sunday, October 25. 2020
Privacy, especially your/mine/everybody's, has been an always actual topic ever since The Internet begun its commercial expansion in the beginning of 90s. Being an important topic, it has been thought everybody should have the right for privacy. In EU, the latest regulation is called on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, or General Data Protection Regulation. In California, USA they'd call it California Consumer Privacy Act.
Privacy protection gone wrong
Both above mentioned regulations have good intention. Forcing websites to bombard all of their users with stupid questions are a complete waste of bandwidth! Everybody is tired of seeing popups like this while surfing:
Somehow the good intention turned on itself. Literally nobody wants to make those choices before entering a site. There should be a setting in my browser and all those sites should read the setting and act on it without bothering me.
Mobile phone tracking
Meanwhile, your cell service provider is using your data and you won't be offered a set of checkboxes to tick.
As an example, Telia’s anonymized location data helps Finnish Government fight the coronavirus (April 2020). This corporation has a product called Crowd Insights. Anybody with a reasonable amount of money (actual price of the service is not known) can purchase location data of actual persons moving around a city. There is a brief investigation by Finnish Chancellor of Justice stating that the service is legal and won't divulge any protected data. The decision (unfortunately, only in Finnish) Paikannustietojen hyödyntäminen COVID-19 –epidemian hillinnässä states, the service's data is daily or hourly and while a reasonable accurate location of a mobile device can be obtained, if that location data doesn't identify a person, obviously, it's not protected by any laws.
On the topic of COVID-19, Future of Privacy Forum has published an article A Closer Look at Location Data: Privacy and Pandemics, where they raise points from ethics and privacy perspective of such tracking. A good read, that!
Application of mobile movement tracking
Here is one. A newspaper article titled "Puhelinten sijaintitiedot paljastavat, kuinka ihmismassojen liikkuminen yöllisessä Helsingissä muuttui" (https://www.hs.fi/kaupunki/art-2000006698336.html):
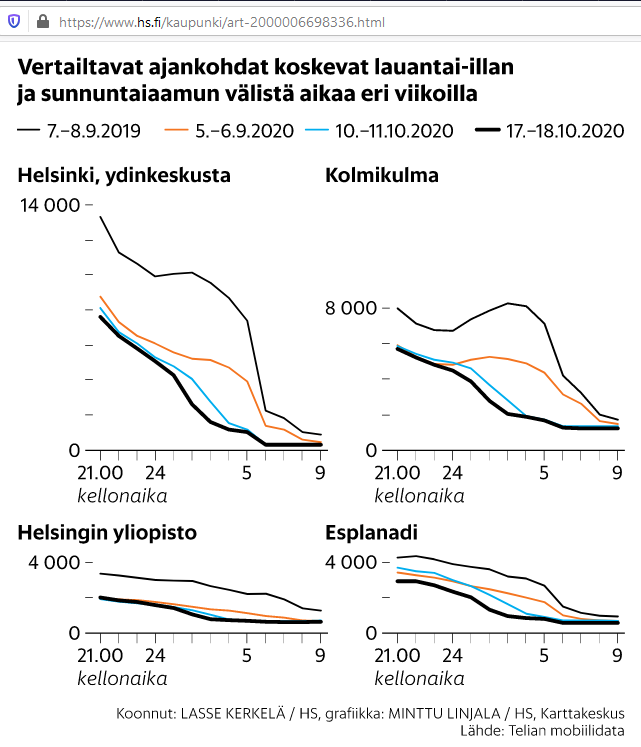
For non-Finnish -speaking readers: this article is about movement of people in center of Helsinki. For a reference point, there is Crowd Insights data from September 2019, time before COVID-19. Movement data from pandemic is from September 5th, October 10th and 17th. To state the obvious: in 2019 between Saturday 9pm and Sunday 9am people moved a lot. What's also visible is how this global pandemic changed this behaviour. In September 2020 there were no strict regulations for night clubs and bars, which is clearly visible in the data.
Anyway, this is the kind of data of you walking around in your hometown streets, your mobile in pocket, can be easily gathered. Doing the same walk without a cell network -connect mobile device wouldn't show in that data set.
What! Are they tracking my movements via my cell phone?
Short: Yes.
Long: Yes. Your cell network provider knows every second to which cell tower all devices in their network are connected to. They also know the exact location of that identified cell tower. This coarse location information can be used by somebody or not.
Everybody knows the Hollywood movie cliché where a phone call is being tracked and somebody throws the frase "Keep them talking longer, we havent' got the trace yet!". In reality they'll know your location if your phone is turned on. It doesn't have to have an ongoing call or message being received. This is how all cell networks are designed and that's how they have always operated. They know your coarse location at all times. How exact a "coarse" location is, depends. Who has access to the location information is protected by multiple laws. The point is: they have the information. At all times.
Example illustration from 3GPP spec TR 23.912 Technical report on Super-Charger:
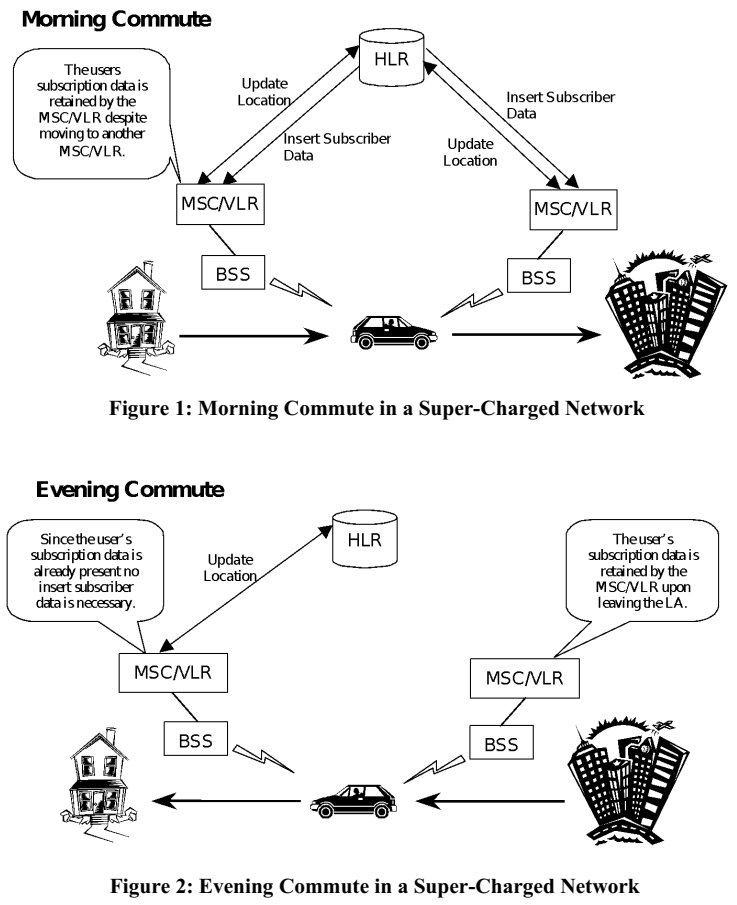
I'm skipping most the TLA (Three-Letter Acronyms) from the pic, but the main concept is having the car (with a phone in it) moving around the network. A HLR (or Home Location Register) will always keep track, on which BSS (note: I think it's called Radio Network Subsysten, RNS in UMTS and LTE) the mobile device talks to. This BSS (or RNS) will send updates on any jumping between the serving cells.
To simplify this further: Just replace the car with a phone in your pocket and this fully applies to people bar-hopping in center of Helsinki.
Database of cell towers
As the cell tower locations are the key component when pinpointing somebody's location, we need to know which cell towers exist and exact locations of those. Unfortunately telcos think that's a trade secret and won't release such information to general public. At the same time, from our phones we can see the identifier of the cell tower a phone is connected to and some hints to neighbouring cells. I wrote about iPhone field test mode couple years back. What a phone also has is a GPS pinpointing the exact location where a particual cell tower and couple of its friends are located at. When added with the information of, a phone typically connecting to the tower with best signal, it is possible to apply some logic. Further gathering couple of data points more, it is possible to calculate a coarse location of a cell tower your phone connects to.
Being an iPhone user, I'm sorry to say an iPhone is not technically suitable for such information gathering. Fortunately, an Android being much more open (to malware) is. Necessary interfaces exist in Android-system to query for cell tower information with an app like Tower Collector. This kind of software it is possible to create records of cell tower information and send them to OpenCelliD to be further processed and distributed to other interested parties.
OpenCelliD website contains an interactive map:
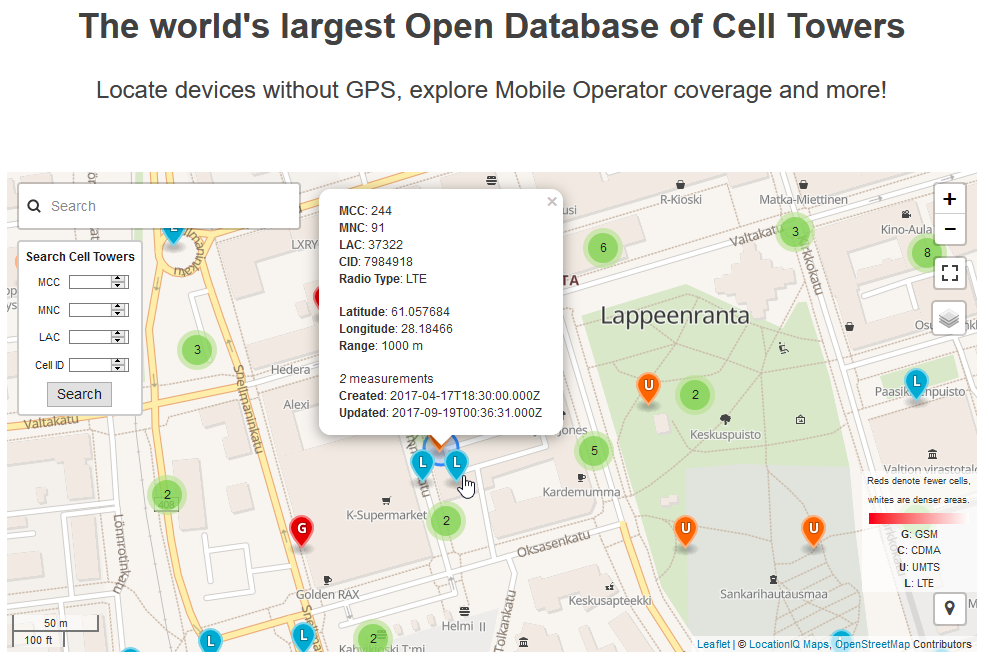
The above example is from my home town of Lappeenranta, Finland. What it depicts is approximation of a LTE cell tower location having following attributes:
- MCC: 244
- MNC: 91
- LAC: 37322
- CID: 7984918
MCC and MNC indicate the telco. CellID Finder has following information for Finland at https://cellidfinder.com/mcc-mnc#F:
| MCC | MNC | Network | Operator or brand name | Status |
| 244 | 3 | DNA Oy | DNA | Operational |
| 244 | 5 | Elisa Oyj | Elisa | Operational |
| 244 | 9 | Finnet Group | Finnet | Operational |
| 244 | 10 | TDC Oy | TDC | Operational |
| 244 | 12 | DNA Oy | DNA | Operational |
| 244 | 14 | Alands Mobiltelefon AB | AMT | Operational |
| 244 | 15 | Samk student network | Samk | Operational |
| 244 | 21 | Saunalahti | Saunalahti | Operational |
| 244 | 29 | Scnl Truphone | Operational | |
| 244 | 91 | TeliaSonera Finland Oyj | Sonera | Operational |
What a LAC (Location Area Code) and CID indicate cannot be decoded without a database like OpenCelliD. Wikipedia article GSM Cell ID gives some hints about LAC and CID. The page also lists other databases you may want to take a look.
COVID-19 tracking
Apple and Google being the manufactures of major operating systems for mobile devices combined forces and created Exposure Notifications. This technology does NOT utilize cell towers nor GPS it it. It works only on Bluetooth LE.
As mentioned in appropriate Wikipedia article, the protocol is called Decentralized Privacy-Preserving Proximity Tracing (or DP-3T for short).
Finally
The key takeaway from all this is:
Location of your mobile device is always known.
Your location, movements between locations and timestamp you did the moving (or not moving) are actively being used to track everybody of us. That's because the technology in mobile networks requires the information.
If this information is shared to somebody else, that's a completely different story.
Advance-fee scam - 2.0 upgrade /w Bitcoin
Thursday, October 22. 2020
From Wikipedia https://en.wikipedia.org/wiki/Advance-fee_scam:
An advance-fee scam is a form of fraud and one of the most common types of confidence tricks. The scam typically involves promising the victim a significant share of a large sum of money, in return for a small up-front payment, which the fraudster requires in order to obtain the large sum.
Any Internet user knows this loved scam is very common, used actively all the time and has number of aliases, including Nigerian scam and 419 scam.
I was on my computer minding my own business when a bot approached me in Discord (that chat-thing gamers use):

Basically what they're saying, I'd get ~7000 € worth in Bitcoins by going to their scam-site, registering as new user and applying the given promo code.
Ok. For those whose bullshit detector wouldn't start dinging already think this for a second:
Why would a complete stranger offer you 7k€ in Discord!!
no
they
wouldn't.
Being interested on their scam, I went for it. Clicked the link to their website, registered a new account, followed instructions and applied the promo code. Hey presto! I was rich!
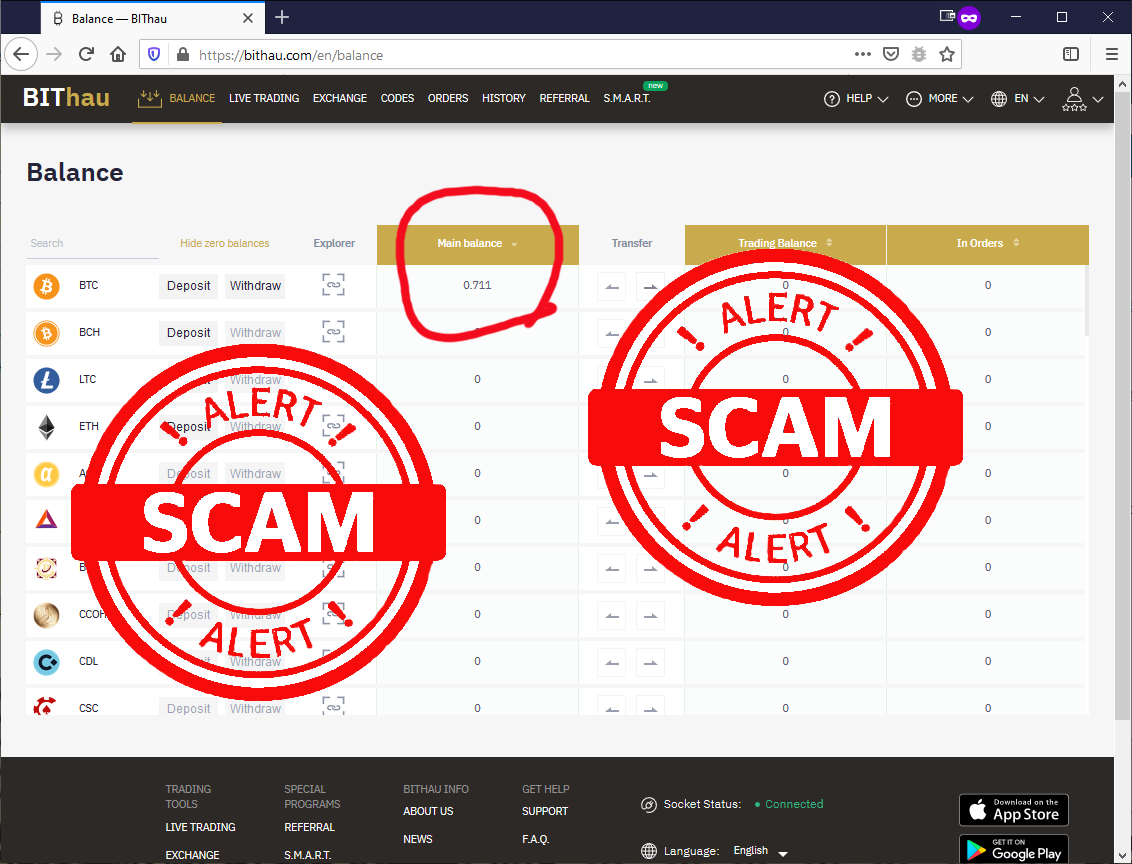
I was a proud owner of 0.711 BTC. Serious money that!
Further following the instructions:
Obviously I wanted to access my newly found riches. Those precious Bitcoins were calling my name and I wanted to transfer them out to a wallet I controlled and could use them for buying new and shiny things.
Not minding the 0.005 BTC transaction fee, this is what happens when you try accessing your Bitcoin giveaway -price:
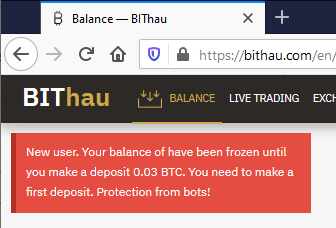
Now they're claiming my new account has been frozen, because they think I'm a bot. Thawing my funds would be easy, simply transfer ~300€ worth of my money to them! As I wanted to keep my own hard-earned money, I did not send them the requested 0.03 BTC. I'm 100% sure, they'll keep inventing "surprising" costs and other things requiring subsequent transfer of funds. I would never ever be able to access the fake-price they awarded me.
Nice scam! 
OpenSSH 8.3 client fails with: load pubkey invalid format - Part 2
Sunday, September 13. 2020
load pubkey: invalid formatThe original blog post is here.
Now Mr. Stott approached me with a comment. He suggested to check the new OpenSSH file format.
I was like "What?! New what? What new format!".
The obvious next move was to go googling the topic. And yes, indeed there exists two common formats for stored OpenSSH keys. Two pieces of articles I found most helpful were The OpenSSH Private Key Format and Openssh Private Key to RSA Private Key. Reading ssh-keygen man-page states:
-m key_format
Specify a key format for key generation, the -i (import), -e (export) conversion options, and the -p change passphrase operation.
The latter may be used to convert between OpenSSH private key and PEM private key formats.
The supported key formats are: “RFC4716” (RFC 4716/SSH2 public or private key), “PKCS8” (PKCS8 public or private key) or “PEM” (PEM public key).
The commonly used two formats can be identified by first line of the private key. Old format has the header of
-----BEGIN EC PRIVATE KEY-----. Obviously, those who are using RSA or Ed25519 keys, the word "EC" would be different. I've been using ECDSA for a while and am considering moving forward with Ed25519 when all of my clients and servers have proper support for it.
I've always "loved" (to hate) SSH's (non-)intuitive user experience. As suggested by all source, to convert my existing key to new PEM-format all I need is to whip up a key generator and use it to change the passphrase. Yeah.
As my OpenSSH-client is OpenSSH_8.3p1 31 Mar 2020, its ssh-keygen will default to output keys in the new format. Depending on your version, the defaults might vary. Anyway, if you're on a really old version, you won't be having the mentioned problem in the first place.
Warning: Changing private key passphrase will execute an in-place replace of the file. If you'll be needing the files in old format, best backup them first. Also, you can convert the format back if you want. It won't produce an exact copy of the original file, but it will be in old format.
For those not using passphrases in their private files: you can always enter the same passphrase (nothing) to re-format the files. The operation doesn't require the keys to have any.
Example conversion:
$ ssh-keygen -p -f my-precious-SSH-key
Enter old passphrase:
Enter new passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved with the new passphrase.
Now the first line of the private key stands at:
-----BEGIN OPENSSH PRIVATE KEY-----
Notice how the key type has been changed into "OPENSSH". The key is still an ECDSA-key, but has been stored in a different.
Testing with the new key indicates a success. Now more warnings, but connectivity is still there. After the conversion, my curves are still elliptic in the right places for the server to grant access! Nice.
Arpwatch - Upgraded and explained
Friday, July 24. 2020
For many years I've run my own systems at home. Its given most of you do much less system running than I. There are servers and network switches and wireless routers, battery-backed power supplies and so on. Most of that I've written about in this blog earlier.
There is many security aspects any regular Jane lay-person won't spend a second thinking of. One of them is: What hardware runs on my home network? In my thinking that question is in top 3 -list.
The answer to that one is very trivial and can be found easily from your own network. Ask the network! It knows.
ARP - Address Resolution Protocol
This is in basics of IPv4 networking. A really good explanation can be found from a CCNA (Cisco Certified Network Associate) study site https://study-ccna.com/arp/: a network protocol used to find out the hardware (MAC) address of a device from an IP address. Well, to elaborate on that. Every single piece of hardware has an unique identifier in it. You may have heard of IMEI in your 3G/4G/5G phone, but as your phone also supports Wi-Fi, it needs to have an identifier for Wi-Fi too. A MAC-address.
Since Internet doesn't work with MAC-addresses, a translation to an IP-address is needed. Hence, ARP.
Why would you want to watch ARPs?
Simple: security.
If you know every single MAC-address in your own network, you'll know which devices are connected into it. If you think of it, there exists a limited set of devices you WANT to have in your network. Most of them are most probably your own, but what if one isn't? Wouldn't it be cool to get an alert quickly every time your network sees a device it has never seen before. In my thinking, yes! That would be really cool.
OUIs
Like in shopping-TV, there is more! A 48-bit MAC-address uniquely identifies the hardware connected to an Ethernet network, but it also identifies the manufacturer. Since IEEE is the standards body for both wired and wireless Ethernet (aka. Wi-Fi), they maintain a database of Organizationally unique identifiers.
An organizationally unique identifier (OUI) is a 24-bit number that uniquely identifies a vendor, manufacturer, or other organization.
OUIs are purchased from the Institute of Electrical and Electronics Engineers (IEEE) Registration Authority by the assignee (IEEE term for the vendor, manufacturer, or other organization).
The list is freely available at http://standards-oui.ieee.org/oui/oui.csv in CSV-format. Running couple sample queries for hardware seen in my own network:
$ fgrep "MA-L,544249," oui.csv
MA-L,544249,Sony Corporation,Gotenyama Tec 5-1-2 Tokyo Shinagawa-ku JP 141-0001
$ fgrep "MA-L,3C15C2," oui.csv
MA-L,3C15C2,"Apple, Inc.",1 Infinite Loop Cupertino CA US 95014
As we all know, CSV is handy but ugly. My favorite tool Wireshark does pre-process the ugly CSV into something it can chew without gagging. In Wireshark source code there is a tool, make-manuf.py producing output file of manuf containing the information in a more user-friendly way.
Same queries there against Wireshark-processed database:
$ egrep "(54:42:49|3C:15:C2)" manuf
3C:15:C2 Apple Apple, Inc.
54:42:49 Sony Sony Corporation
However, arpwatch doesn't read that file, a minor tweak is required. I'm running following:
perl -ne 'next if (!/^([0-9A-F:]+)\s+(\S+)\s+(.+)$/); print "$1\t$3\n"' manuf
... and it will produce a new database usable for arpwatch.
Trivial piece of information: Apple, Inc. has 789 OUI-blocks in the manuf-file. Given 24-bit addressing they have 789 times 16M addresses available for their devices. That's over 13 billion device MAC-addresses reserved. Nokia has only 248 blocks.
Practical ARP with a Blu-ray -player
Let's take a snapshot of traffic.
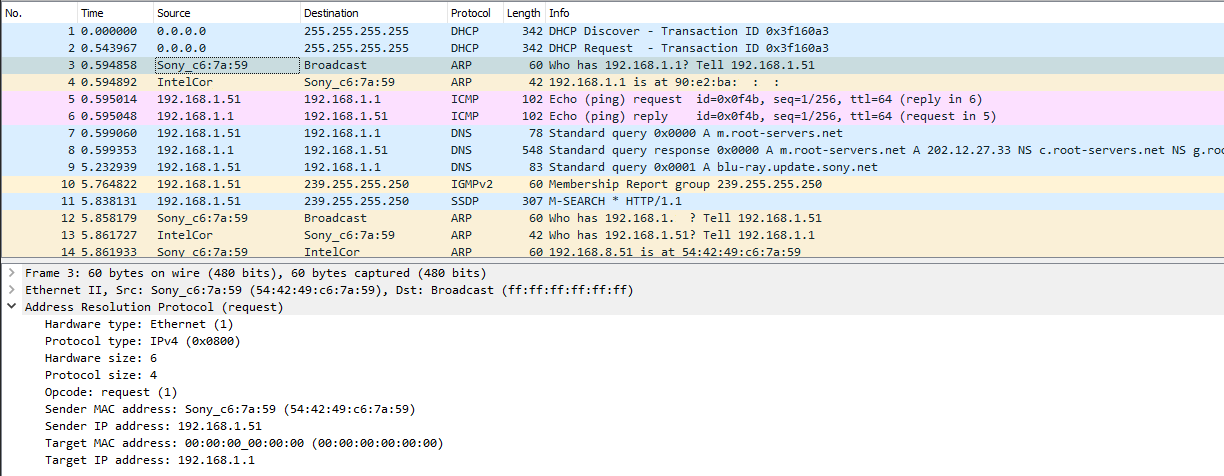
This s a typical boot sequence of a Sony Blu-ray player BDP-S370. What happens is:
- (Frames 1 & 2) Device will obtain an IPv4-address with DHCP, Discover / Offer / Request is missing the middle piece. Hm. weird.
- (Frame 3) Instantly after knowing the own IPv4-address, the device will ARP-request the router (192.168.1.1) MAC-address as the device wants to talk into Internet.
- (Frames 5 & 6) Device will ping (ICMP echo request) the router to verify its existence and availability.
- (Frames 7-9) Device won't use DHCP-assigned DNS, but will do some querying of its own (discouraged!) and check if a new firmware is available at
blu-ray.update.sony.net. - (Frame 12) Device starts populating its own ARP-cache and will query for a device it saw in the network. Response is not displayed.
- (Frames 13 & 14) Router at 192.168.1.1 needs to populate its ARP-cache and will query for the Blu-ray player's IPv4-address. Device will respond to request.
- Other parts of the capture will contain ARP-requests going back and forth.
Practical ARP with a Linux 5.3
Internet & computers do evolve. What we saw there in a 10 year old device is simply the old way of doing things. This is how ARP works in a modern operating system:
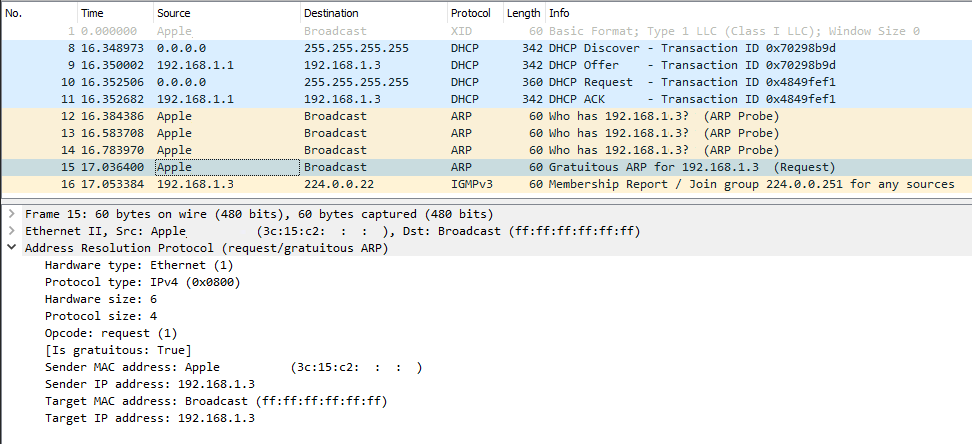
In this a typical boot sequence. I omitted all the weird and unrelated stuff and that makes the first frame as #8. What happens in the sequence is:
- (Frames 8-11) Device will obtain an IPv4-address with DHCP, Discover / Offer /Request / Ack -sequence is captured in full.
- (Frames 12-14) Instantly after knowing the own IPv4-address, the device will ARP-request the IPv4 address assigned into it. This is a collision-check to confirm nobody else in the same LAN is using the same address.
- (Frame 15) Go for a Gratuitous ARP to make everybody else's life easier in the network.
- Merriam-Webster will define "gratuitous" as:
not called for by the circumstances :
not necessary, appropriate, or justified :
unwarranted - No matter what, Gratuitous ARP is a good thing!
- Merriam-Webster will define "gratuitous" as:
- (Frame 16) Join IGMPv3 group to enable multicast. This has nothing to do with ARP, though.
The obvious difference is the existence of Gratuitous ARP "request" the device did instantly after joining the network.
- A gratuitous ARP request is an Address Resolution Protocol request packet where the source and destination IP are both set to the IP of the machine issuing the packet and the destination MAC is the broadcast address ff:ff:ff:ff:ff:ff. A new device literally is asking questions regarding the network it just joined from itself! However, the question asking is done in a very public manner, everybody in the network will be able to participate.
- Ordinarily, no reply packet will occur. There is no need to respond to an own question into the network.
- In other words: A gratuitous ARP reply is a reply to which no request has been made.
- Doing this seems no-so-smart, but gratuitous ARPs are useful for four reasons:
- They can help detect IP conflicts. Note how Linux does aggressive collision checking by its own too.
- They assist in the updating of other machines' ARP tables. Given Gratuitous ARP, in the network capture, there are nobody doing traditional ARPing for the new device. They already have the information. The crazy public-talking did the trick.
- They inform switches of the MAC address of the machine on a given switch port. My LAN-topology is trivial enough for my switches to know which port is hosting which MAC-addresses, but when eyeballing the network capture, sometimes switches need to ARP for a host to update their MAC-cache.
- Every time an IP interface or link goes up, the driver for that interface will typically send a gratuitous ARP to preload the ARP tables of all other local hosts. This sums up reasons 1-3.
How can you watch ARPs in a network?
Simple: run arpwatch in your Linux-router.
Nice people at Lawrence Berkeley National Laboratory (LBNL) in Berkeley, California have written a piece of software and are publishing it (among others) at https://ee.lbl.gov/. This ancient, but maintained, daemon has been packaged into many Linux-distros since dawn of time (or Linux, pick the one which suits you).
As already established, all devices will ARP on boot. They will ARP also later during normal operations, but that's beside the point. All a device needs to do is to ARP once and it's existence is revealed. When the daemon sees a previously unknown device in your network, it will emit a notification in form of an email. Example:
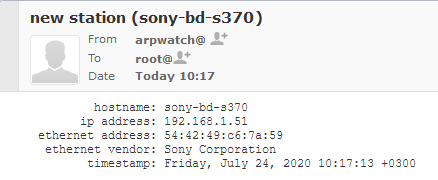
Here, my router running arpwatch saw a Sony Blu-ray player BDP-S370. The ethernet address contains the 24-bit OUI-part of 54:42:49 and remaining 24-bits of a 48-bit MAC will identify the device. Any new devices are recorded into a time-stamped database and no other notifications will be made for that device.
Having the information logged into a system log and receiving the notification enables me to ignore or investigate the device. For any devices I know can be ignored, but anything suspicious I'll always track.
IPv6 and ARP
Waitaminute! IPv6 doesn't do ARP, it does Neighbor Discovery Protocol (NDP).
True. Any practical implementation does use dual-stack IPv4 and IPv6 making ARP still a viable option for tracking MAC-addresses. In case you use a pure-IPv6 -network, then go for addrwatch https://github.com/fln/addrwatch. It will support both ARP and NDP in same tool. There are some shortcomings in the reporting side, but maybe I should take some time to tinker with this and create a patch and a pull-request to the author.
Avoiding ARP completely?
Entirely possible. All a stealth device needs to do is to piggy-back an existing device's MAC-address in the same wire (or wireless) and impersonate that device to remain hidden-in-plain-sight. ARP-watching is not foolproof.
Fedora updated arpwatch 3.1 RPM
All these years passed and nobody at Fedora / Red Hat did anything to arpwatch.
Three big problems:
- No proper support for
/etc/sysconfig/in systemd-service. - Completely outdated list of Organizationally Unique Identifier (OUIs) used as Ethernet manufacturers list displaying as unknown for anything not 10 years old.
- Packaged version was 2.1 from year 2006. Latest is 3.1 from April 2020.
Here you go. Now there is an updated version available, Bug 1857980 - Update arpwatch into latest upstream contains all the new changes, fixes and latest upstream version.
Given systemd, for running arpwatch my accumulated command-line seems to be:
/usr/sbin/arpwatch -F -w 'root (Arpwatch)' -Z -i eth0
That will target only my own LAN, both wired and wireless.
Finally
Happy ARPing!
OpenSSH 8.3 client fails with: load pubkey invalid format
Saturday, July 11. 2020
Update 13th Sep 2020:
There is a follow-up article with a key format conversion infromation.
Ever since updating into OpenSSH 8.3, I started getting this on a connection:
$ ssh my-great-linux-server
load pubkey "/home/me/.ssh/id_ecdsa-my-great-linux-server": invalid format
Whaaaat!
Double what on the fact, that connection works. There is no change in connection besided the warning.
8.3 release notes won't mention anything about that (OpenSSH 8.3 released (and ssh-rsa deprecation notice)). My key-pairs have been elliptic for years and this hasn't bothered me. What's going on!?
Adding verbosity to output with a -vvv reveals absolutely nothing:
debug1: Connecting to my-great-linux-server [192.168.244.1] port 22.
debug1: Connection established.
load pubkey "/home/me/.ssh/id_ecdsa-ecdsa-my-great-linux-server": invalid format
debug1: identity file /home/me/.ssh/id_ecdsa-ecdsa-my-great-linux-server type -1
debug1: identity file /home/me/.ssh/id_ecdsa-ecdsa-my-great-linux-server-cert type -1
debug1: Local version string SSH-2.0-OpenSSH_8.3
Poking around, I found this article from Arch Linux forums: [SOLVED] openssh load pubkey "mykeyfilepath": invalid format
Apparently OpenSSH-client now requires both the private AND public keys to be available for connecting. Mathematically the public key isn't a factor. Why would it be needed? I cannot understand the decision to throw a warning about assumed missing key. I do have the key, but as I won't need it in my client, I don't have it available.
Simply touching an empty file with correct name won't clear the warning. The actual public key of the pair needs to be available to make the ridiculous message go away.
After little bit of debugging points to the problem in ssh.c:
check_load(sshkey_load_public(cp, &public, NULL),
filename, "pubkey");
Link: https://github.com/openssh/openssh-portable/blob/V_8_3_P1/ssh.c#L2207
Tracking the change:
$ git checkout V_8_3_P1
$ git log -L 2207,2207:ssh.c
.. points to a commit 5467fbcb09528ecdcb914f4f2452216c24796790 (Github link), which was made exactly two years ago in July 11th 2018 to introduce this checking of loaded public key and emitting a hugely misleading error message on failure.
To repeat:
Connecting to a server requires only private key. The public key is used only at the server end and is not mathematically required to establish encrypted connection from a client.
So, this change is nothing new. Still the actual reason for introducing the check_load()-call with most likely non-existing public key is a mystery. None of the changes made in the mentioned commit or before it explains this addition, nor there are no significant changes made in the actual public key loading. A check is added, nothing more.
Fast forward two years to present day. Now that the 8.3 is actually used by a LOT of people, less than a month ago the problem was fixed. Commit c514f3c0522855b4d548286eaa113e209051a6d2 (Github link) fixes the problem by simulating a Posix ENOENT when the public key was not found from expected locations. More details about that error are in errno (7) man page.
Problem solved. All we all need to do is wait for this change to propagate to the new clients. Nobody knows how long that will take as I just updated this.
Going Elliptic on TLS-certificates
Monday, April 27. 2020
The TLS-certificate for this blog was up for expiration. As I'm always eager to investigate TLS and test things, I'm doing an experiment of my own and went for more modern stuff. Also I've been wanting to obsolete TLS versions 1 and 1.1, so I went for an Elliptic-Curve private key. If you can read this, you probably operate reasonable modern hardware, operating system and browser. If you for some reason stop to see my writings, then you're out of luck. I don't support your obsoleted stuff anymore!
Here are the old and new certs side-by-side:
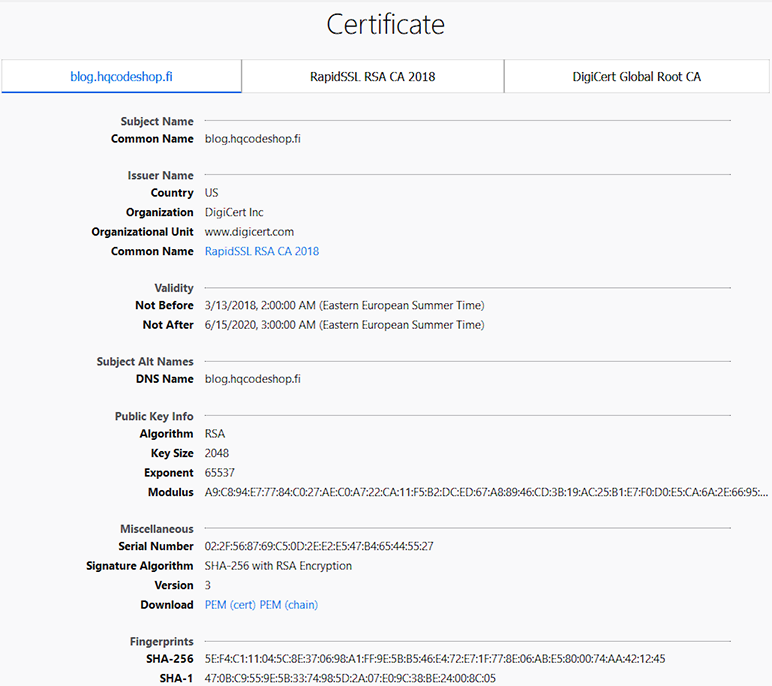
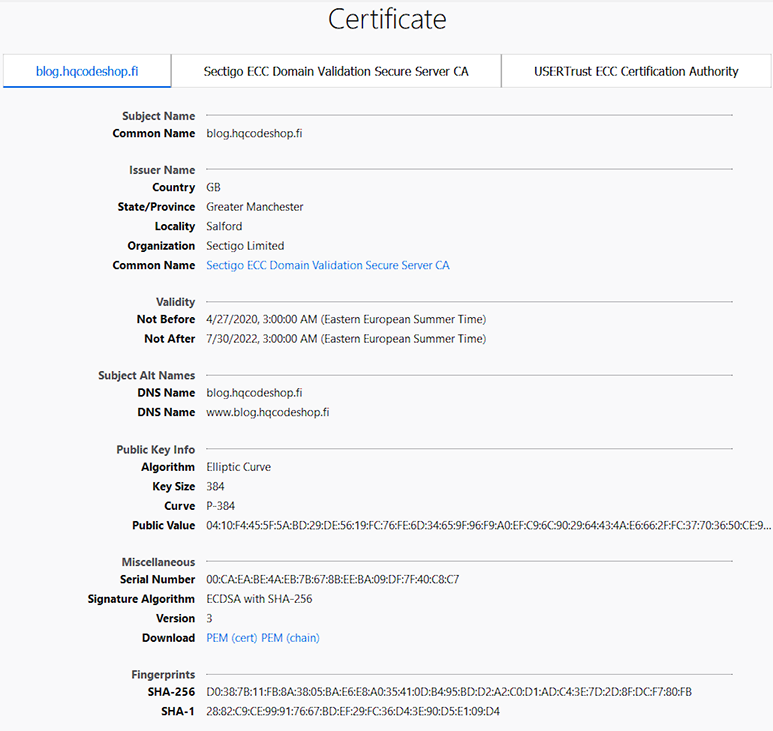
Obvious differences are:
- Expiry: 2+ years of lifetime left. Note: They sold the cert as a 5 year one, but I know about Apple's recent decision to shorten the lifetime of a TLS-cert. Read all about it from About upcoming limits on trusted certificates.
- Issuer: Sectigo ECC Domain Validation Secure Server CA, RapidSSL/DigiCert won't issue ECDSA on cheap certs
- Certificate chain: ECDSA and SHA-2 256-bits on certificate, intermediate-CA and root-CA
- Key-pair type: Now there is a 384-bit secp384r1 curve instead of plain-old-RSA
If you want, you can do almost the same with Let's Encrypt. Getting an ECDSA-cert out of Let's E used to be a tedious manual task, but I'm using acme.sh for my LEing. Its readme says:
Let's Encrypt can now issue ECDSA certificates.
And we support them too!
Just set the keylength parameter with a prefix ec-.
Example command to get a 384-bit ECDSA certificate from Let's Encrypt with acme.sh:
$ ./acme.sh --issue --dns dns_rackspace --keylength ec-384 -d example.com
That's no different than getting a RSA-certificate. The obvious difference in Let's Encrypt cert and my paid cert is in the certificate chain. In Let's E, chain's CA-types won't change from RSA, but your own cert will have elliptic-curve math in it.
Note:
Some people say ECDSA is more secure (example: ECC is faster and more secure than RSA. Here's where you (still) can't use it). ECDSA is modern and faster than RSA, that's for sure. But about security there is controversy. If you read Wikipedia article Elliptic-curve cryptography - Quantum computing attacks, there is note: "... suggesting that ECC is an easier target for quantum computers than RSA". There exists a theory, that a quantum computer might be able to crack your curve-math easier than your prime math. We don't know if that's true yet.
Practical Internet Bad Neighborhoods with Postfix SMTPd
Sunday, April 26. 2020
Bad what?
Neighbourhood. In The Internet. There is a chance you live in one. It is not likely, but entirely possible. Most ISPs offering services to you are NOT bad ones.
This idea of a "bad neighbourhood" comes from University of Twente. Back in 2013 Mr. Moura did his PhD thesis titled "Internet Bad Neighborhoods". Summary:
Of the 42,000 Internet Service Providers (ISPs) surveyed, just 20 were found to be responsible for nearly half of all the internet addresses that send spam. That just is one of the striking results of an extensive study that focused on “Bad Neighborhoods” on the internet (which sometimes correspond to certain geographical areas) that are the source of a great deal of spam, phishing or other undesirable activity.
In plain text for those allergic to scientific abstracts: Based on 2013 study, 0.05% of all Internet Service Providers are responsible for 50% of the trouble. (Some of you'll say 99% of all studies are crap, but this one falls into the 1%.)
How can you detect a "bad neighbourhood"?
Oh, that's easy! Somebody from such a neighbourhood will send you spam. They'll send you links to malware. They port-scan you. They try to guess your passwords in SMTPd, SSHd or whatever their scanning revealed about you.
The theory is: That person "lives" (not necessarily IRL live, but Internet live) near other such criminals and wanna-be-criminals. Such people will find safe harbour within ISPs or hosting providers with lax security and/or low morale. Offenders find other like-minded cohorts and commit their cyber crime from that "neighbourhood".
Ok, I know an IP-address of a spam sender, what next?
Today, most people are using their email from Google or Microsoft or whatever cloud service. Those companies hire smart people to design, develop and run software to attempt to separate bad emails from good emails. Since I run an email server of my own, I have the option (luxury!) of choosing what to accept. One acceptance criteria is the connecting client's IP-address.
Off-topic: Other accepting criteria I have is standards compliance. Any valid email from Google or Microsoft or other cloud service provider will meet bunch of standards, RFCs and de-facto practices. I can easily demand a connecting client to adhere those. A ton of spammers don't care and are surprised that I'll just kick them out for not meeting my criteria. Obviously it won't stop them, but it will keep my mailbox clean.
On a connection to my SMTPd I'll get the connecting client's IP-address. With that I do two things:
- Check if its already blacklisted by spam blockers
- I'm mostly using Zen by Spamhaus. Read https://www.spamhaus.org/zen/ for more.
- Check if its already blacklisted by me based on an earlier spam that passed standards criteria and blacklisting by spam blockers
For a passing spam a manual process is started. From connecting client's IP-address first I'll determine the AS-number (see: Autonomous system (Internet) @ Wikipedia). Second, from the AS-number I'll do a reverse listing of CIDRs covered by that ASN.
Example illustration:
Credit: Above picture is borrowed from https://www.noction.com/knowledge-base/border-gateway-protocol-as-migration.
In the above picture, I'm Customer C on green color. The CIDR assigned to me by my ISP B is 192.168.2.1/24. The spammer attempting to send me mail is at Customer D on red color. As an example, let's assume the sending mail server will have IP-address of 192.168.1.10. Doing an ASN-query with that IPv4 will result in AS 64499. Then I'll do a second ASN-query to query for all the networks assigned for AS 64499. That list will contain one entry: 192.168.1.1/24. Now I can block that entire CIDR as a "bad" one. Effectively I have found one "Internet Bad Neighborhood" to be added into my blocking list. In reality I don't know if all IP-addresses in that network are bad, but I can assume so and won't get punished by doing so.
The only real "punishment" for me is the cardinal sin of assuming. I do assume, that everybody in that neighbourhood are as evil as the one trying to spam me. Unfortunately for the "good ones" in that network, blocking the entire network so is very very effective. The level of trouble originating from that neighbourhood comes down really fast.
Practical approach with Postfix
Doing all the queries and going to different databases manually is obviously tedious, time-consuming and can be easily automated.
A tool I've used, developed an ran for many years is now polished enough and made publicly available: Spammer block or https://github.com/HQJaTu/spammer-block
In the README.md, I describe my Postfix configuration. I do add a file /etc/postfix/client_checks.cidr which I maintain with the list CIDRs of known spammers. The restriction goes into Postfix main.cf like this:
smtpd_client_restrictions =
permit_mynetworks
permit_sasl_authenticated
check_client_access cidr:/etc/postfix/client_checks.cidr
An example output of running ./spammer-block.py -i 185.162.126.236 going into client_checks.cidr would be:
# Confirmed spam from IP: 185.162.126.236
# AS56378 has following nets:
31.133.100.0/24 554 Go away spammer! # O.M.C.
31.133.103.0/24 554 Go away spammer! # O.M.C.
103.89.140.0/24 554 Go away spammer! # Nsof Networks Ltd (NSOFNETWORKSLTD-AP)
162.251.146.0/24 554 Go away spammer! # Cloud Web Manage (CLOUDWEBMANAGE)
185.162.125.0/24 554 Go away spammer! # O.M.C.
185.162.126.0/24 554 Go away spammer! # O.M.C.
That's it. No need to map a CIDR-file. Just remember to reload the postfix after changing the CIDR-list to make sure the new list is in effect of Postfix listener.
Problem with ipwhois-library
This is the reason I didn't publish the Spammer block -project year ago. My Python-tool is using ipwhois-library for the heavy lifting (or querying). It is a well-written handy library doing just the thing I need in this project. However, (yes even this one has a however in it) ipwhois is using RADb (https://www.radb.net/) for source of information. My experience is, that when specifically talking about list of CIDRs contained in an AS-number, RADb is not perfect source of information. To fix this, I wrote an improvement of ipwhois adding ipinfo.io as an alternate ASN data source. A developer can make a choice and use the one source suiting the project.
There is a catch. ipinfo.io doesn't allow free users more than 5 ASN-queries / day / IP-address. By creating an account and paying for their API-usage that limitation can be lifted. Also, their information about CIDRs in AS-number is accurate. This is a prime example why I love having options available.
Unfortunately for me and most users requiring ASN-queries, the author of ipwhois didn't approve my improvement. You may need to install my version from https://github.com/HQJaTu/ipwhois instead. Obviously, this situation is not ideal. Having a single version would be much better for everybody.
Finally
That's it. If you receive spam from unknown source, run the script and add results to your own block-list. Do that couple weeks and your amount of spam will reduce. Drastically!
Beware! Sometimes even Google or Microsoft will send you spam. Don't block reliable providers.
I'm open for any of your comments or suggestions. Please, don't hesitate to send them.

