Upgrading into Windows 8.1
Friday, October 25. 2013
Authenticating HTTP-proxy with Squid
Thursday, October 24. 2013
Mac OS X 10.9 Mavericks .ISO image
Wednesday, October 23. 2013
Fixing Google's new IPv6 mail policy with Postfix
Friday, October 18. 2013
Parallels Plesk Panel 11 RPC API, part 2
Thursday, October 17. 2013
Thanks Google for your new IPv6 mail policy
Wednesday, October 16. 2013
The short version is: Fucking idiots!
Long version:
Google Mail introduced a new policy somewhere in August 2013 for receiving e-mail via IPv6. Earlier the policy was same for IPv4 and IPv6, but they decided to make Internet a better place by employing a much tighter policy for e-mail senders. Details can be found from their support pages.
For e-mail Authentication & Identification they state:
- Use a consistent IP address to send bulk mail.
- Keep valid reverse DNS records for the IP address(es) from which you send mail, pointing to your domain.
- Use the same address in the 'From:' header on every bulk mail you send.
- We also recommend publishing an SPF record
- We also recommend signing with DKIM. We do not authenticate DKIM using less than a 1024-bit key.
- The sending IP must have a PTR record (i.e., a reverse DNS of the sending IP) and it should match the IP obtained via the forward DNS resolution of the hostname specified in the PTR record. Otherwise, mail will be marked as spam or possibly rejected.
- The sending domain should pass either SPF check or DKIM check. Otherwise, mail might be marked as spam.
First: My server does not send bulk mail. It sends mail now an then. If the idiots label my box as a "bulk sender" (whatever that means), there is nothing I can do to help it.
Second: I already have done all of the above. I even checked my PTR-record twice. Yes, it is in the above list two times using different words.
Still, after jumping all the hoops, crossing all the Ts and dotting all the Is: they don't accept email from my box anymore. They dominate the universe, they set new policies, start to enforce them without notice and fail to provide any kind of support. At minimum a web page to fill in couple of fields to a form to test how they perceive your server and give a result what to fix. But no. They don't do that, they just stop to accept any email.
To provide matching words for their search engine, I post a log entry (wrapped to multiple lines) from my Postfix:
postfix/smtp[6803]: A82C94E6CE:
to=<my@sending.address.fi>,
orig_to=<the@recipient's.address.net>,
relay=aspmx.l.google.com[2a00:1450:4008:c01::1b]:25,
delay=0.76,
delays=0.04/0/0.35/0.37,
dsn=5.7.1,
status=bounced (host aspmx.l.google.com[2a00:1450:4008:c01::1b] said:
550-5.7.1 [2001:-my-IPv6-address- 16]
Our system has detected 550-5.7.1 that this message does not meet IPv6 sending guidelines regarding
PTR 550-5.7.1 records and authentication.
Please review 550-5.7.1 https://support.google.com/mail/?p=ipv6_authentication_error for more 550 5.7.1 information.
qc2si10501687bkb.307 - gsmtp (in reply to end of DATA command))
I'm not alone with my problem. Easily a number of people complaining about the same issue can be found: Gmail, why are you doing this to me? and Google, your IPv6-related email restrictions suck. Most people simply stop using IPv6 to deliver mail to Google. My choice is to fight to the bitter end.
While complaining the un-justified attitude I get from Google, I got a piece of advice: "Why don't you check what Google's DNS thinks of your setup?". I was like "WHAAT? What Google DNS?"
In fact there is a public DNS offered by Google. It is described in article Using Google Public DNS. I did use that to confirm that my DNS and reverse-DNS were set up correctly. I typed this into a BASH-shell:
# dig -x 2001:-my-IPv6-address- @2001:4860:4860::8888
It yielded correct results. There was nothing I could do to fix this issue more.  As it turned out, I did not change anything but after a couple of days, they just seemed to like my DNS more and allowed my email to pass. Perhaps one of these days I'll write something similar to my open recursive DNS tester.
As it turned out, I did not change anything but after a couple of days, they just seemed to like my DNS more and allowed my email to pass. Perhaps one of these days I'll write something similar to my open recursive DNS tester.
Idiots!
Bug in Linux 3.11: Netfilter MASQUERADE-target does not work anymore
Wednesday, October 9. 2013
Why cloud platforms exist - Benchmarking Windows Azure
Tuesday, October 8. 2013
I got permission to publish a grayed out version of a project I was contracted to do this summer. Since the customer paid big bucks for it, you're not going to see all the details. I'm sorry to act as a greedy idiot, but you have to hire me to do something similar to see your results.
The subject of my project is something that personally is intriguing to me: how much better does a cloud-native application perform when compared to a traditional LAMP-setup. I chose the cloud platform to be Windows Azure, since I know that one best.
The Setup
There was a pretty regular web-application for performing couple of specific tasks. Exactly the same sample data was populated to Azure SQL for IaaS-test and Azure Table Storage for PaaS -test. People who complain about using Azure SQL can imagine a faster setup being used on a virtual machine and expect the thing to perform faster.
To simulate a real web application, memory cache was used. Memcache for IaaS and Azure Cache for PaaS. On both occasions using memory cache pushes the performance of the application further as there is no need to do so much expensive I/O.
Results
In the Excel-charts there are number of simulated users at the horizontal axis. There are two vertical axis used for different items.
Following items can be read from the Excel-charts:
- Absolute number of pages served for giving measurement point (right axis)
- Absolute number of pages returned, which returned erroneous output (right axis)
- Percentage of HTTP-errors: a status code which we interpret as an error was returned (left axis)
- Percentage of total errors: HTTP errors + requests which did not return a status code (left axis)
- Number successful pages returned per second (left axis)
Results: IaaS
I took a ready-made CentOS Linux-image bundled with Nginx/PHP-FPM -pair and lured it to work under Azure and connect to ready populated data from Azure SQL. Here are the test runs from two and three medium instances.
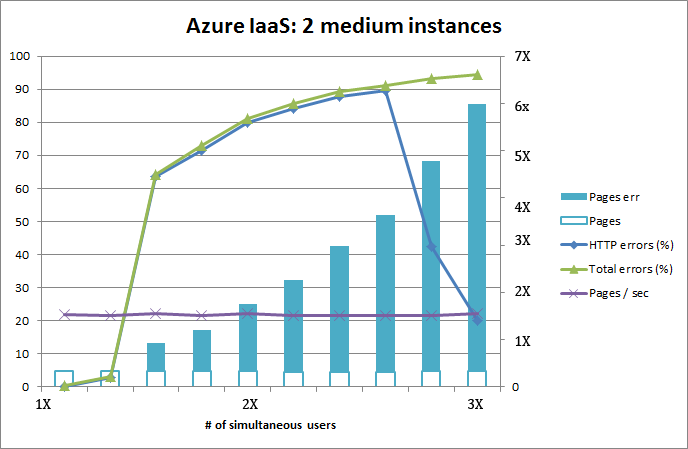
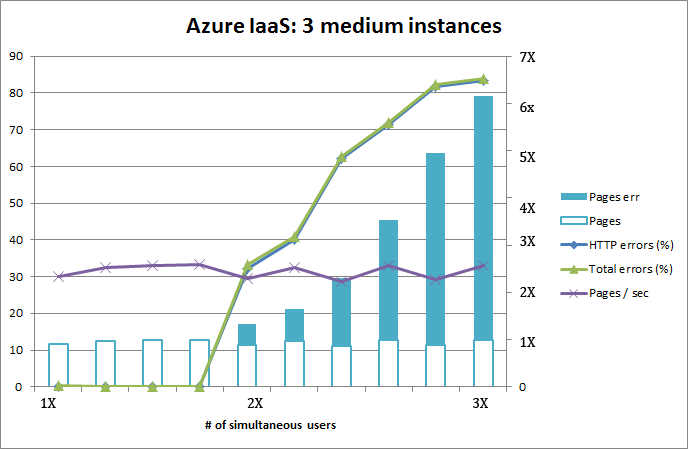
Adding a machine to the service absolutely helps. With two instances, the application chokes completely at the end of test load. Added machine also makes the application perform much faster, there is a clear improvement on page load speed.
Results: PaaS
Exactly the same functionality was implemented with .Net / C#.
Here are the results:
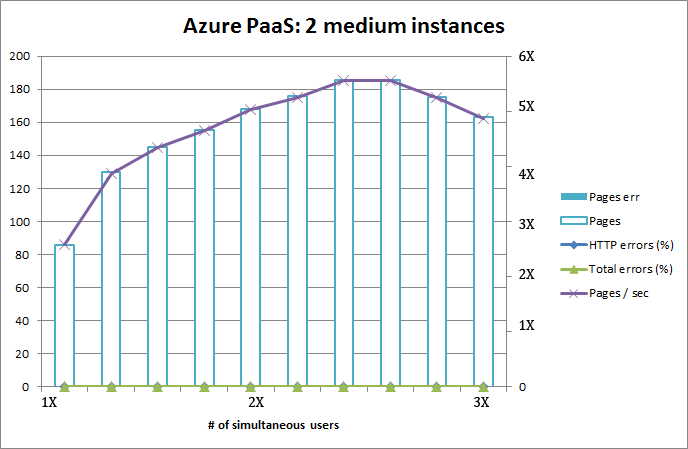
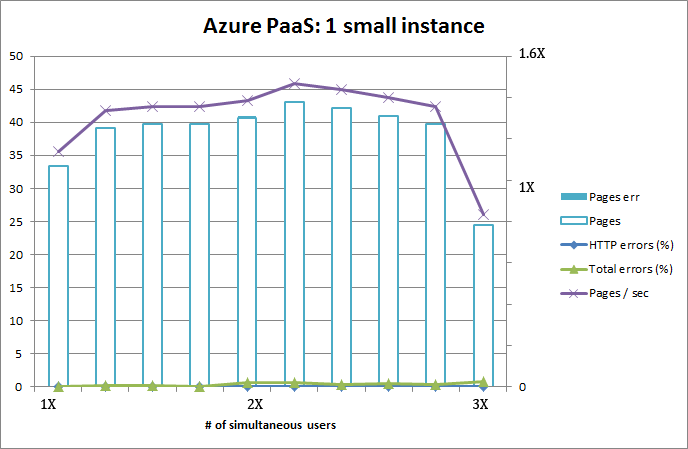
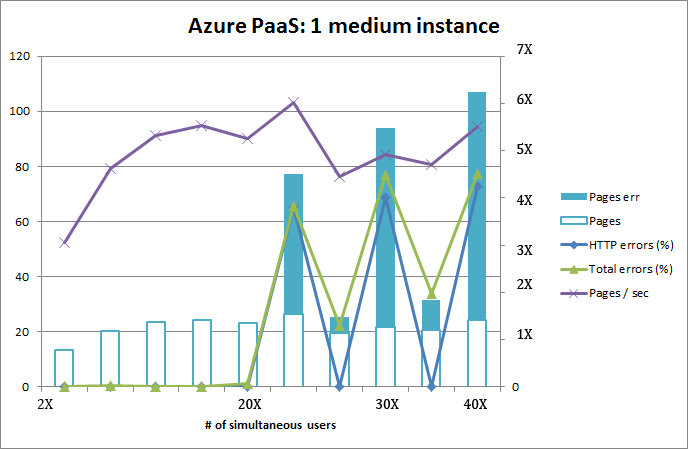
Astonishing! Page load speed is so much higher on similar user loads, also no errors can be produced. I pushed the envelope with 40 times the users, but couldn't be sure if it was about test setup (which I definitely saturated) or Azure's capacity fluctuating under heavy load. The test with small role was also very satisfactory, it beats the crap out of running two medium instances on IaaS!
Conclusion
I have to state the obvious: PaaS-application performs much better. I just couldn't belive that it was impossible to get exact measurement from the point where the application chokes on PaaS.
Why Azure PaaS billing cannot be stopped? - revisit
Monday, October 7. 2013
In my earlier entry about Azure PaaS billing, I was complaining about how to stop the billing.
This time I managed to do it. The solution was simple: delete the deployments, but leave the cloud service intact. Then Azure stops reserving any (stopped) compute units for the cloud service. Like this:
![]()
Here is the proof:
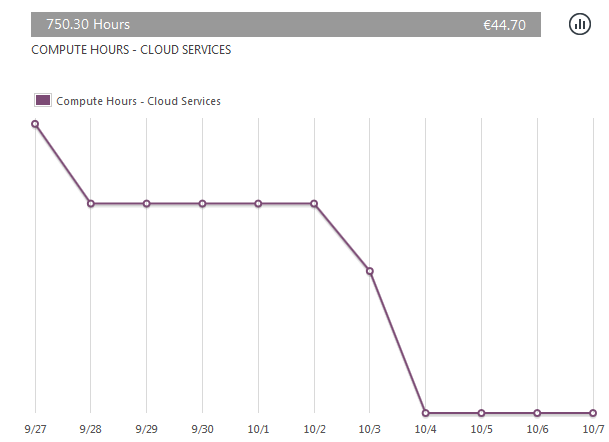
Zero billing. Nice! 
Acronis True Image 2014 royal hang
Wednesday, October 2. 2013
Why Azure PaaS billing cannot be stopped?
Tuesday, October 1. 2013
In Windows Azure stopping an IaaS virtual machine stops the billing, there is no need to delete the stopped instance. When you stop a PaaS cloud service, following happens:
Based on billing:
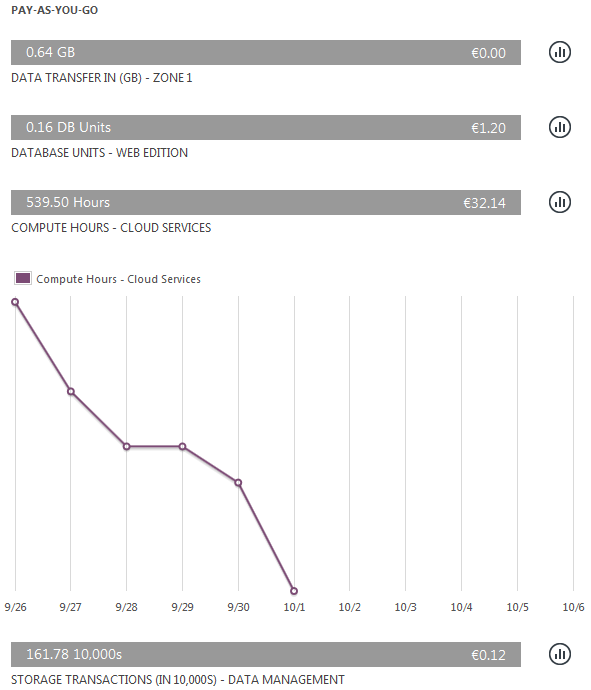
This is really true. On 26th and 27th I had a cloud service running on Azure, but I stopped it. On 28th and 29th there is billing for a service that has been stopped, and for which I got the warning about. I don't know why on 30th there is one core missing from the billing. Discount, perhaps?
My bottom line is:
Why? What possible idea could be, that your PaaS cloud service needs to be deleted in order to stop billing? Come on Microsoft! Equal rules for both cloud services!


{kind=link}