Megazoning (or Laser Tagging)
Wednesday, June 29. 2016
I'll post something about not computers for a change. Its pretty close, but still, not about computers.
Any self-respecting nerd (such as me) loves video games. Doing first-person-shooter games IRL is always both fun and a lot more difficult than on a computer.
We had a company activity and went to nearby Megazone for couple rounds of always fun laser tag. Since it was my first time ever doing that, it was like a slap in the face. I'm a 2nd lieutenant in FDF reserve, so I have basic understanding of tactics in a battle. Also I've played video games since early 80s and FPS games since first Wolfenstein. On top of that I've been paintballing enough to know that there is enough realism in video games and paintballing to match real military tactics. However, anything I knew about combat, tactics and fighting at that point was usless.
In the game there were three teams and you, so pretty much everybody you see is an enemy. Megazone is mostly about movement and speedy tags of any visible opponents. The worst thing that can happen to you there is that you're unable to fire your weapon for 8 seconds. During a 25 minute round that's not too dangrous. In paintball or war you're out on the first "tag", here you aren't, it's just a game of accumulating points.
Here are my stats from first round:

I sucked! 
My handle in the game was Macro (in the Red team), so being 8th out of 14 wasn't that good. Tactically the maze was a nightmare! In the original Wolfenstein it was possible to be hit only from front, back or sides. In Megazone there were 2 floors, but it was a metal grid walkway making it possible to shoot trough. That made it 5th direction where getting hit was possible. At best I found couple locations where it was possible to get some cover and get hit only from two directions. The only even semi-functional tactic I found was to ignore any defence, cover and cautiousness. Just going recklessly forward and out-gunning everybody on a reaction seemed to work good. Also sniping people long-range was a really good tactic, sometimes I could do 4-5 people from a single position. They never saw me. I also did try attacking enemy bases and defending own base, but they were totally pointless exercises in futility, I spent too much time trying to figure out the value of those.
Here is my second round:

Quite an improvement in points and ranking. I was best in our team and 3rd in total!
Megazone was great fun, but with my background, it'll never be my favorite thing. I want to see my opponents suffering when I hit them, in laser tag that doesn't happen.
Fixing curl with Go Daddy Secure Certificate Authority G2 CA root
Tuesday, June 7. 2016
Curl is one weird piece of software. Every time I use it, I get chills. The reason for this is, that it almost works and when it doesn't there isn't a damn thing you can to to fix it. The entire design of that software is ... I'm lost for words here. I'm looking for words that describe: cumbersome, shitty, unorthodox, non-functional, and so on.
Since the lib-version is used by a number of libraries and other software as a means to provide HTTP-protocol implementation I do run into curl-issues often. Many times I didn't even know, that in the end I was using libcurl for access before one of these obscure errors pops. For this reason, my weapon-of-choice is wget, it uses OpenSSL's crypto and is fully compatible with pretty much everything else in a Linux-distro.
Anyway, this time I chose to research this to the bitter and. It took me about a month (calendar time) to resolve this. Of course I didn't spend all my time and energy into this, it just took a very long time to get this one done properly & right.
The problem
One day, I was just tinkering something and ran a command:
$ curl --verbose https://packetstormsecurity.net/
... and it pulled a curl on me. 
* About to connect() to packetstormsecurity.net port 443 (#0)
* Trying 198.84.60.198...
* Connected to packetstormsecurity.net (198.84.60.198) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
* Server certificate:
* subject: CN=packetstormsecurity.com,OU=Domain Control Validated
* start date: May 31 18:04:40 2015 GMT
* expire date: May 31 18:04:40 2016 GMT
* common name: packetstormsecurity.com
* issuer: CN=Go Daddy Secure Certificate Authority - G2,
OU=http://certs.godaddy.com/repository/,
O="GoDaddy.com, Inc.",L=Scottsdale,ST=Arizona,C=US
* NSS error -8179 (SEC_ERROR_UNKNOWN_ISSUER)
* Peer's Certificate issuer is not recognized.
* Closing connection 0
curl: (60) Peer's Certificate issuer is not recognized.
More details here: http://curl.haxx.se/docs/sslcerts.html
curl performs SSL certificate verification by default, using a "bundle"
of Certificate Authority (CA) public keys (CA certs). If the default
bundle file isn't adequate, you can specify an alternate file
using the --cacert option.
If this HTTPS server uses a certificate signed by a CA represented in
the bundle, the certificate verification probably failed due to a
problem with the certificate (it might be expired, or the name might
not match the domain name in the URL).
If you'd like to turn off curl's verification of the certificate, use
the -k (or --insecure) option.
I hate when that happens. Also I don't know who forgot to do what, but it just won't work and nobody in the entire Internet knows how to handle that.
Figuring out the details of the issue
This is the easy part:
* NSS error -8179 (SEC_ERROR_UNKNOWN_ISSUER)
* Peer's Certificate issuer is not recognized.
In human language that reads: The problem is with HTTPS. The certificate used by the remote site is issued by a Certificate Authority (CA), that we don't know of and because we don't know it we won't trust any certificates issued by it.
Further:
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
In human that reads: There were three (3) places I tried looking for the root-certificate:
- NSS is the Network Security Services -library created by Mozilla. Its database is located at: /etc/pki/nssdb
- OpenSSL is the library/toolkit used by pretty much rest of your Linux for HTTPS-encryption. It has the trusted root-certificates at: /etc/pki/tls/certs/ca-bundle.crt
- OpenSSL didn't use a directory (CApath) for certificates.
After doing all three of those, no suitable CA was found and curl had to disconnect from the server and inform user about this lack-of-trust -issue.
Possible solutions
Ignore the issue and force curl to continue
There is a suggestion:
turn off curl's verification of the certificate, use the -k (or --insecure) option
This goes right out the window, because I'd rather chew off my left arm than force a prefectly valid check to be ignored. I'd rather spend the time investigating the fix. But that's me. Most of you don't care. I do.
Add the missing certificate to ca-bundle.crt
Good idea, but ... That file is reserved for the operating system / distro by OpenSSL. Actually curl uses this file only to make its own life easier so that curl doesn't have to distribute a set of trusted CA certificates, it just piggy-backs with something OpenSSL has.
Since this approach is OpenSSL-specific there is a procedure for adding own CA root-certificates into your system. When a new CA-root needs to be installed the mechanism is not to copy the certificate into this big file. How to actually do it, we'll get into that later.
The obvious problem with this approach is, that next time your distro gets a new CA-bundle one of two things will happen: 1) your changes will be overwritten and lost, you'll have to add the CA-root again or 2) the new CA-bundle won't be installed, because somebody messed up a file which he/she shouldn't do. This is definitely not a good approach.
Implicitly specify the CA root-certificate file
Aa-ha! There is a command-line option for this purpose:
--cacert <CA certificate>
(SSL) Tells curl to use the specified certificate file to verify
the peer. The file may contain multiple CA certificates. The
certificate(s) must be in PEM format. Normally curl is built to
use a default file for this, so this option is typically used to
alter that default file.
That's the one I could use, if I'd like to do that every goddamn single time I curl for something. First I don't want to do that every time and second, that command-line option isn't available for me, as I was using a piece of software wrapped to use libcurl.
Add the missing CA root-certificate into NSS database to establish trust
This is the one I chose. This is also the one nobody gets solved.
If you can find precise information on the web how to fix this, please tell me. I've been browsing the net for partial and non-working solutions enough not to care for half-assed solutions which don't work at the end.
Getting the missing certificate
Whatever we do (except just ignore the problem), the missing root-certificate needs to be located. With a little bit of googling I found a page Repository, Here’s a collection of important certificate documentation (https://certs.godaddy.com/repository/) at GoDaddy's server. Sure, the initial impression was "whoa, that was easy!", but when I landed on the page, I realized that there were following root-certificates available for GoDaddy Certificate Chain - G2 to download:
- GoDaddy Class 2 Certification Authority Root Certificate - G2
- GoDaddy Secure Server Certificate (Intermediate Certificate) - G2
- Microsoft to GoDaddy G2 Cross Certificate
- GoDaddy G2 Code Signing Intermediate
- GoDaddy Secure Extended Validation Code Signing CA - G2
- GoDaddy Certificate Bundle for Microsoft Windows Driver Signing - G2
- GoDaddy Certificate Bundles - G2
- GoDaddy PKCS7 Certificate Intermediates Bundle (for Windows IIS) - G2
- GoDaddy Certificate Bundles - G2 With Cross to G1
- GoDaddy Certificate Bundles - G2 With Cross to G1, includes Root
Ok, which one will I need? Darn!
Luckily I know something about X.509 certificates and especially certificate extensions. There should be an AIA or Authority Information Access -section (see RFC 5280 section 5.2.7 for details) in the cert. At least most CAs provide that information to make people's life easier.
First download the cert with a one-liner:
$ echo | \
openssl s_client -connect packetstormsecurity.net:443 \
> /tmp/packetstormsecurity.net.cert
Btw. the one-liner will say dumb things like:
depth=0 OU = Domain Control Validated, CN = packetstormsecurity.com
verify error:num=20:unable to get local issuer certificate
verify return:1
depth=0 OU = Domain Control Validated, CN = packetstormsecurity.com
verify error:num=27:certificate not trusted
verify return:1
depth=0 OU = Domain Control Validated, CN = packetstormsecurity.com
verify error:num=21:unable to verify the first certificate
verify return:1
That's just vomit from the fact, that the certificate isn't trusted. The important thing is, that the one-liner will result a text-file with lot of other garbage, but also the server certificate PEM. Luckily OpenSSL will ignore all the garbage when doing command:
$ openssl x509 -noout -text -in /tmp/packetstormsecurity.net.cert
That one will output a lot of stuff. Most if which are irrelevent for this purpose. The relevant things are:
Certificate:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, ST=Arizona, L=Scottsdale, O=GoDaddy.com, Inc.,
OU=http://certs.godaddy.com/repository/,
CN=Go Daddy Secure Certificate Authority - G2
X509v3 extensions:
X509v3 Certificate Policies:
Policy: 2.16.840.1.114413.1.7.23.1
CPS: http://certificates.godaddy.com/repository/
Authority Information Access:
OCSP - URI:http://ocsp.godaddy.com/
CA Issuers -
URI:http://certificates.godaddy.com/repository/gdig2.crt
X509v3 Authority Key Identifier:
keyid:40:C2:BD:27:8E:CC:34:83:30:A2:33:D7:FB:6C:B3:F0:B4:2C:80:CE
Exactly what we needed! There is an AIA-block with a direct URL of http://certificates.godaddy.com/repository/gdig2.crt in it.
A download:
$ wget http://certificates.godaddy.com/repository/gdig2.crt \
-O "/etc/pki/tls/certs/Go Daddy Secure Certificate Authority - G2.pem"
... and verify that certificate's serial number:
$ openssl x509 -noout -text \
-in /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
... will reveal:
Certificate:
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, ST=Arizona, L=Scottsdale, O=GoDaddy.com, Inc.,
CN=Go Daddy Root Certificate Authority - G2
Subject: C=US, ST=Arizona, L=Scottsdale, O=GoDaddy.com, Inc.,
OU=http://certs.godaddy.com/repository/,
CN=Go Daddy Secure Certificate Authority - G2
X509v3 extensions:
X509v3 Subject Key Identifier:
40:C2:BD:27:8E:CC:34:83:30:A2:33:D7:FB:6C:B3:F0:B4:2C:80:CE
X509v3 Authority Key Identifier:
keyid:3A:9A:85:07:10:67:28:B6:EF:F6:BD:05:41:6E:20:C1:94:DA:0F:DE
Oh yes x 2!! The CA certificate has the correct serial number. It issued the failing certificate. This proof of correct CA-chain. We found the correct file.
Establishing trust to the new CA root-certificate in OpenSSL
This is the easy part. This one I have done hundreds of times.
First get a hash of the certificate:
$ openssl x509 -hash -noout \
-in /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
For this particular certificate, the hash is 27eb7704. The next thing is to instruct OpenSSL that this newly downloaded certificate is trusted by our server. It can be done like this:
$ ln -s /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem \
/etc/pki/tls/certs/27eb7704.0
The idea is to symlink the downloaded file with a filename from the hash and suffix the file with a .0 (dot-zero).
Now we can verify, that our setup was done correctly (remember the "garbage" file we downloaded earlier):
$ openssl verify /tmp/packetstormsecurity.net.cert
The only valid output would be:
/tmp/packetstormsecurity.net.cert: OK
Anything else, and you fumbled it.
Additional step: Add all hashes of the certificate chain
Command line openssl-command is at level now, however that's not how applications access certificates. Now this is where the CLI-command and library functionality differ. My box has /usr/lib64/libssl.so.10 to do the work for an application.
Looking at the SSL_CTX_use_certificate documentation, it's evident that there are functions to add a known certificate bundle (/etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem in my box, symlinked via /etc/pki/tls/certs/ca-bundle.crt), or a single certificate file. Not a directory of certificates, what openssl-command does. An application has to iterate the directory and add every certificate individually. For example in Perl, HTTPS-connections are typically created via IO::Socket::SSL-library. It accempts two options: SSL_ca_path and SSL_ca_file.
As the option of modifying the ca-bundle.crt file was abandoned already, using option SSL_ca_file is out. It leaves us with SSL_ca_path, which requires every certificate hash to be symlinked to the appropriate certificate PEM-file. That's why the already done symlink won't do it completely, two additional ones are required to get IO::Socket::SSL working properly:
$ ln -s ca-bundle.crt cbf06781.0
$ ln -s ca-bundle.crt f081611a.0
Where those two hashes come from is bit complex, but here goes:
The intermediate CA certificate we downloaded, Go Daddy Secure Certificate Authority - G2, was issued by:
$ openssl x509 -noout -issuer_hash
-in Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
... a certificate which has hash of cbf06781, which is already packed into ca-bundle.crt. Here things go weird, the Go Daddy Root Certificate Authority - G2 having hash cbf06781 is self-signed. However, during web-access that exact same certificate (with same serial number and all) is issued by a certificate having hash of f081611a. In ca-bundle.crt there is one with subject Go Daddy Class 2 Certification Authority. So, we need to add both to keep applications happy. Looks like somebody at Go Daddy really dropped the ball. Why should there be two separate CA certificates? Insane.
Actually, for example OpenSuSE Linux distro does that automatically to all bundle-certificates. The system is so stupid, that symlinkin all certificates is the only working method.
Establishing trust to the new CA root-certificate in NSS
Ok, this is the impossible part.
By lot of googling, poking around, failing, reading docs, tracing Curl, etc. I found out that there is a tool called certutil - Utility to manipulate NSS certificate databases. It seems to belong to package nss-tools. There is a man-page and some documentation at Network Security Services. But what's happening and how should I proceed remains bit foggy.
There is a /etc/pki/nssdb/, which we found in the beginning of this. That directory contains the NSS database in form of bunch of files. I found out that cert8.db and key3.db are completely obsoleted and any access methods having certutil -d /etc/pki/nssdb/ are completely useless, because they access only those files. Nobody/nothing uses those. Why are they there?
The files having effect are cert9.db and key4.db. The correct way of accessing those includes certutil -d sql:/etc/pki/nssdb. Notice the sql: -part difference. That's the part causing most confusion.
To get the certificate into the DB run command on a single line:
certutil -d sql:/etc/pki/nssdb -A -t "C,C,C"
-n "Go Daddy Secure Certificate Authority - G2"
-i /etc/pki/tls/certs/Go\ Daddy\ Secure\ Certificate\ Authority\ -\ G2.pem
Now your NSS DB should list:
# certutil -d sql:/etc/pki/nssdb -L
Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPI
Go Daddy Secure Certificate Authority - G2 C,C,C
The three Cs mean that the certificate in the DB is an authority for servers, e-mail and code signing. certutil docs say, that using 'C' for intermediate certificates is discouraged, and I didn't bother to check if that 'C' is needed at all. But having that doesn't break anything now the setup is done.
Testing
Now, running exactly the same command:
$ curl --verbose https://packetstormsecurity.net/
... will result in:
* About to connect() to dl.packetstormsecurity.net port 443 (#0)
* Trying 198.84.60.200...
* Connected to dl.packetstormsecurity.net (198.84.60.200) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt CApath: none
* SSL connection using TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
* Server certificate:
* subject: CN=packetstormsecurity.com,OU=Domain Control Validated
* start date: May 31 18:04:40 2015 GMT
* expire date: May 31 18:04:40 2016 GMT
* common name: packetstormsecurity.com
* issuer: CN=Go Daddy Secure Certificate Authority - G2,
OU=http://certs.godaddy.com/repository/,
O="GoDaddy.com, Inc.",L=Scottsdale,ST=Arizona,C=US
< HTTP/1.1 200 OK
Yesh! It works!
One hell of a thing to get fixed, but now the trust has been established so that it reaches also Curl and any applications using libcurl.
Final words
This is a multi-mess.
First: Go Daddy messes up their certs. Why isn't their Go Daddy Secure Certificate Authority - G2 in ca-bundle.crt? Why are there two version of Go Daddy Root Certificate Authority - G2?
Second: Having NSS in a Linux is insane! Nobody else is using that for certificate storage. libcurl's support for any own CAs is completely messed up and unusable.
CentOS 7.2 network install fail [Solved]
Sunday, June 5. 2016
I was about to upgrade an old CentOS 6 box into 7. It was all planned, backups taken, necessary information gathered and USB stick prepared with 7.2 DVD image in it. A shutdown and boot from the installation USB, bunch of settings, date/time, keyboard, network, but Däng! No dice.
My initial attempt was to install from USB, but for some reason the server didn't see the USB volume as a valid installation source. No problem, I thought, let's go for network-install then. The interface was already up and the box could reach Internet ok. Installing from a mirror shouldn't take too long. But no. All I could accomplish was a "Error setting up base repository". I went googling about this and found CentOS 7.2 Netinstall Guide – Network Installation Screenshots.
First I set up installation source as On the network: http://mirror.centos.org/centos/7.2.1511/os/x86_64/ and then This URL refers to a mirror list: Checked. No avail. It took about 8 minutes to get the error, but this approach failed miserably. What /tmp/packaging.log had was:
ERR packaging: failed to grab repo metadata for anaconda: Cannot find a valid baseurl for repo: anaconda
ERR packaging: metadata download for repo anaconda failed after 10 retries
Argh! 8 minutes to determine, that the thing didn't work.
There was plenty of time to plan for the next move. I went to see CentOS mirror list, and picked the local Finnish mirror at nic.FUNET. Setting that as source: http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/ and with This URL refers to a mirror list: set as Unchecked got me butkus, /tmp/packaging.log had:
ERR packaging: failed to grab repo metadata for anaconda: failure: repodata/6990209f63a9fd811f13e830ac3c6de4c5d70a42b1c6873e4329b523d394c3bd-primary.xml.gz from anaconda: [Errno 256] No more mirrors to try.
http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/
6990209f63a9fd811f13e830ac3c6de4c5d70a42b1c6873e4329b523d394c3bd-primary.xml.gz: [Errno 14] HTTP Error 404 - Not Found
Finally a tangible result. Obviously the HTTP/404 was correct. There is no such file in that directory. It took me about 15 seconds to determine, that the URL should be http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/
0e54cd65abd3621a0baf9a963eafb1a0ffd53603226f02aadce59635329bc937-primary.xml.gz. Something was off in the installer metadata. But where?
I checked treeinfo at http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/.treeinfo, but no avail. Then my poking around landed at /var/run/install/repo/repodata. It has among others, a file named repomd.xml. Looking at the network version from http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/repomd.xml made everything clear as crystal.
- Drive had:
- revision 1449702798
- 6990209f63a9fd811f13e830ac3c6de4c5d70a42b1c6873e4329b523d394c3bd, the file that doesn't exist in the mirror
- Network had:
- revision 1449700451
- 0e54cd65abd3621a0baf9a963eafb1a0ffd53603226f02aadce59635329bc937, the file that does exist
But how to fix this?
My initial attempt was to wget http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/repomd.xml into /var/run/install/repo/repodata and retry, but that didn't change anything, still the same frustrating error after 10 minute delay.
I rebooted the box and relized, that my change persisted on the USB-drive. Whoa! Anyway, I got things cooking this time. Finally the base repository was accepted, I got to go make installation selection and got the install forward.
What the hell was going on there? Where did the incorrect repomd.xml come from? It isn't in the installation image. Or it is, but it comes from a place I didn't find. Whatever it is, there is something seriously off in the process. Why doesn't the installer try to get the most recent version from the network. It is a network install, after all!! After frustrating couple hours later than anticipated, I finally got the box upgraded. Hopefully this information saves you that time.
The reason I run an adblocker
Thursday, June 2. 2016
Advertisement blocking is kind of hot topic in today's Internet. Pages with this type of content are becoming more popular:
Hell yeah I block every bit of JavaScript, IFrame and cookie that I don't like of.
The flipside of the issue is that monetization becomes a lot more difficult when no ads are being displayed. New York Times has a quite fresh article about that: Rise of Ad-Blocking Software Threatens Online Revenue. There is nothing new in that, Forbes wrote about the same issue an year ago: Is using ad-blocking software morally wrong? The debate continues. That article says:
"Some critics argue — as I did in a recent post — that the bigger problem is the advertising model that many media outlets are based on, and the fact that it requires them to rely on invasive tracking software, annoying popups and other low-quality advertising. In a sense, ad blockers are sending a message to these publications, telling them to come up with a better experience (and yes, I agree that we at Fortune could probably do a better job of that too)."
Back to reality. Let's make a practical measurement about those annoying ads. The example is from Wired, one of those who run extensive adblock detection and blocker blocking. Here is page load performance without any blocking:

When AdBlock Plus is enabled:
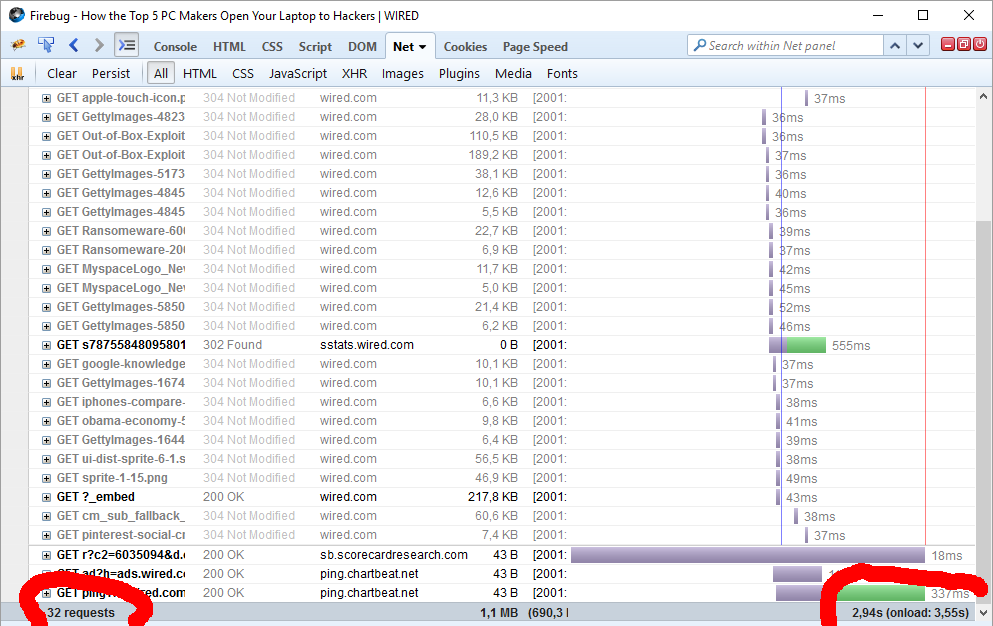
The number of requests goes down from 38 to 32 and total page load time from 5 seconds to 3 seconds. I'd say that's quite an improvement! And all I have to do is NOT to load their stupid and poorly implemented advertisements. You can argue, that it's just a meanigless timing, the end time measured doesn't have any meaning and the page is actually visible and browseable about the same time. Maybe, maybe not. It's my computer, my bandwidth and I choose not to waste it into their crap.
Another example: One of the most popular websites in Finland, Iltalehti:
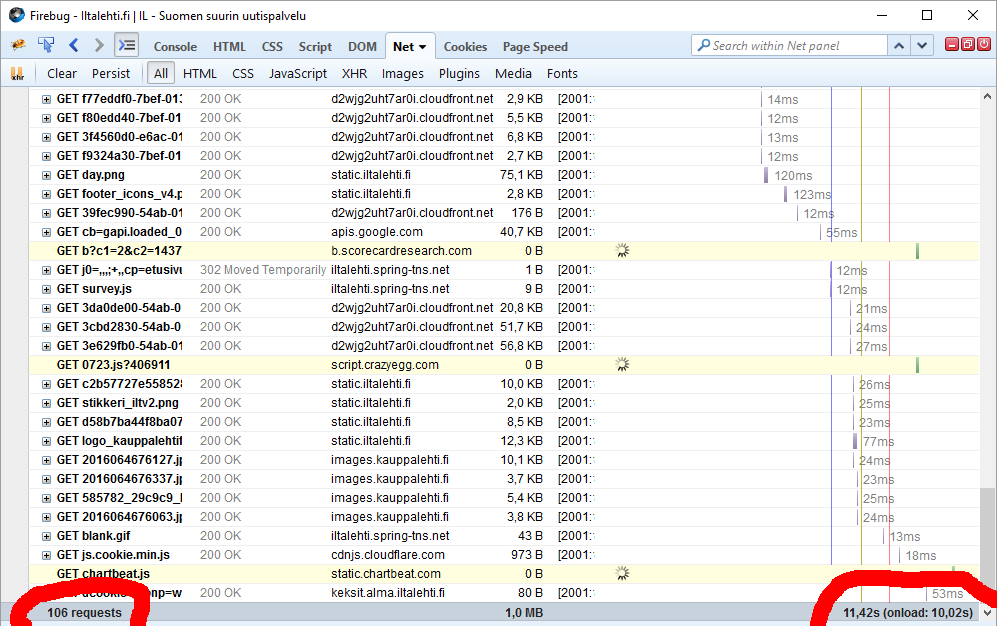
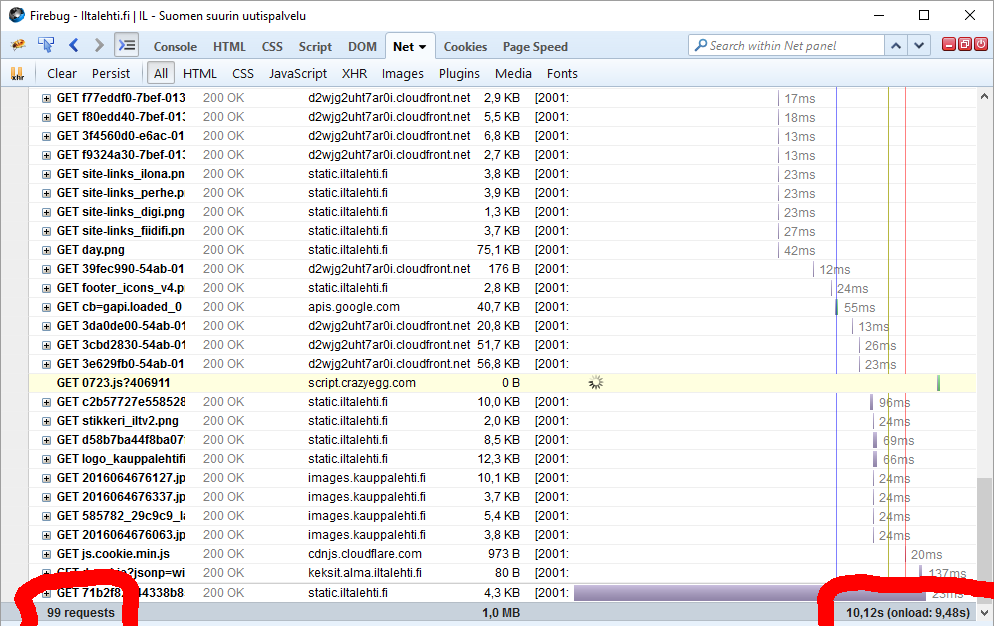
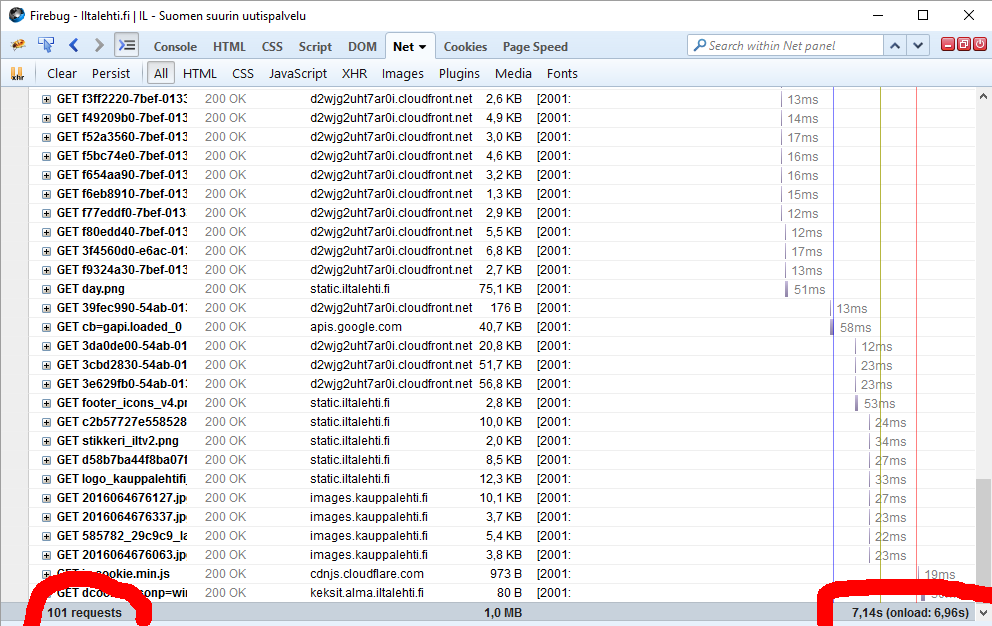
I have three measurements from that: one without blocking, one with only Adblock Plus enabled and finally the mode I normally run at, with NoScript and Adblock Plus. The number of requests made is high, above 100 but it is way too inconclusive. There are way too many dynamic requests being made to get a meaningful figure. The important thing is the page load times, they go down from 10 to 9,5 to 7 seconds. It is a very good indication of how much unnecessary crap a single page loads.
The obvious thing which nobody says aloud is that it is possible to improve page's performance, but nobody cares. There is something fundamentally wrong if a single page loads 100 additional pieces of data. If I'd create a website with that much dynamic loading, I'd probably be fired. But in the nation's most popular website, that's ok. Strange.
Let's look at another example: The same page, but this time on a low-end laptop running Windows 10 and one of the worst browsers there is, Microsoft Edge:
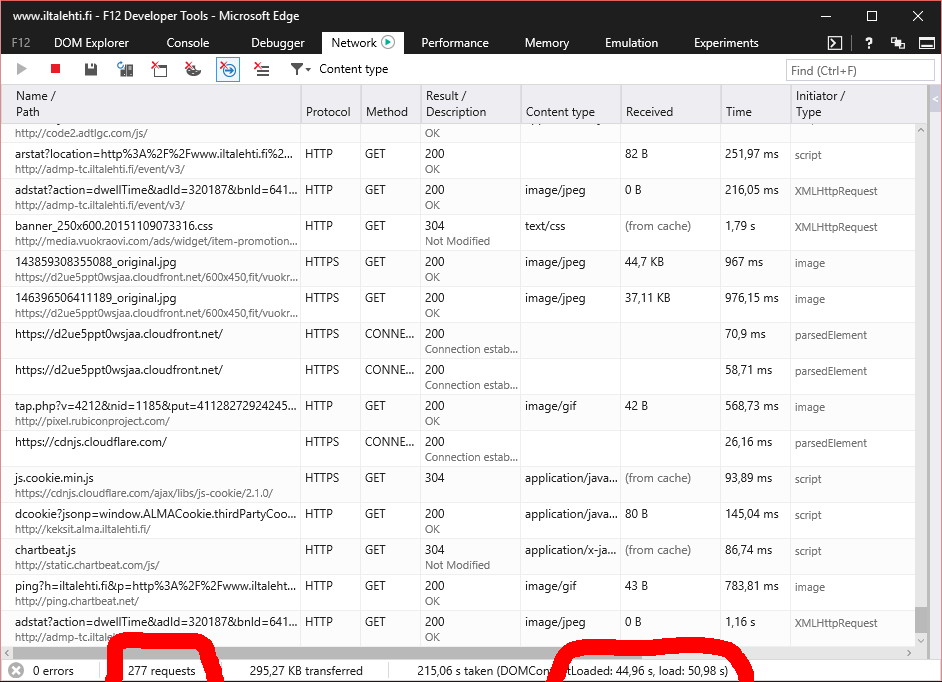
There is no adblocker available for that piece of crap. The page load time is around 45 seconds. On any reasonable browser that would be a fraction of that, not 10 seconds, but still much much faster than that. That poorly optimized turtle-of-a-browser would most definitely benefit from running a lot less bad tracking code and needless blinking ads.
As everything else, also blocking these unwated ads goes mobile, see 2016 Mobile Adblocking Report for details. It doesn't take any rocket surgery to figure out why is that. For example me playing my favorite mobile game:
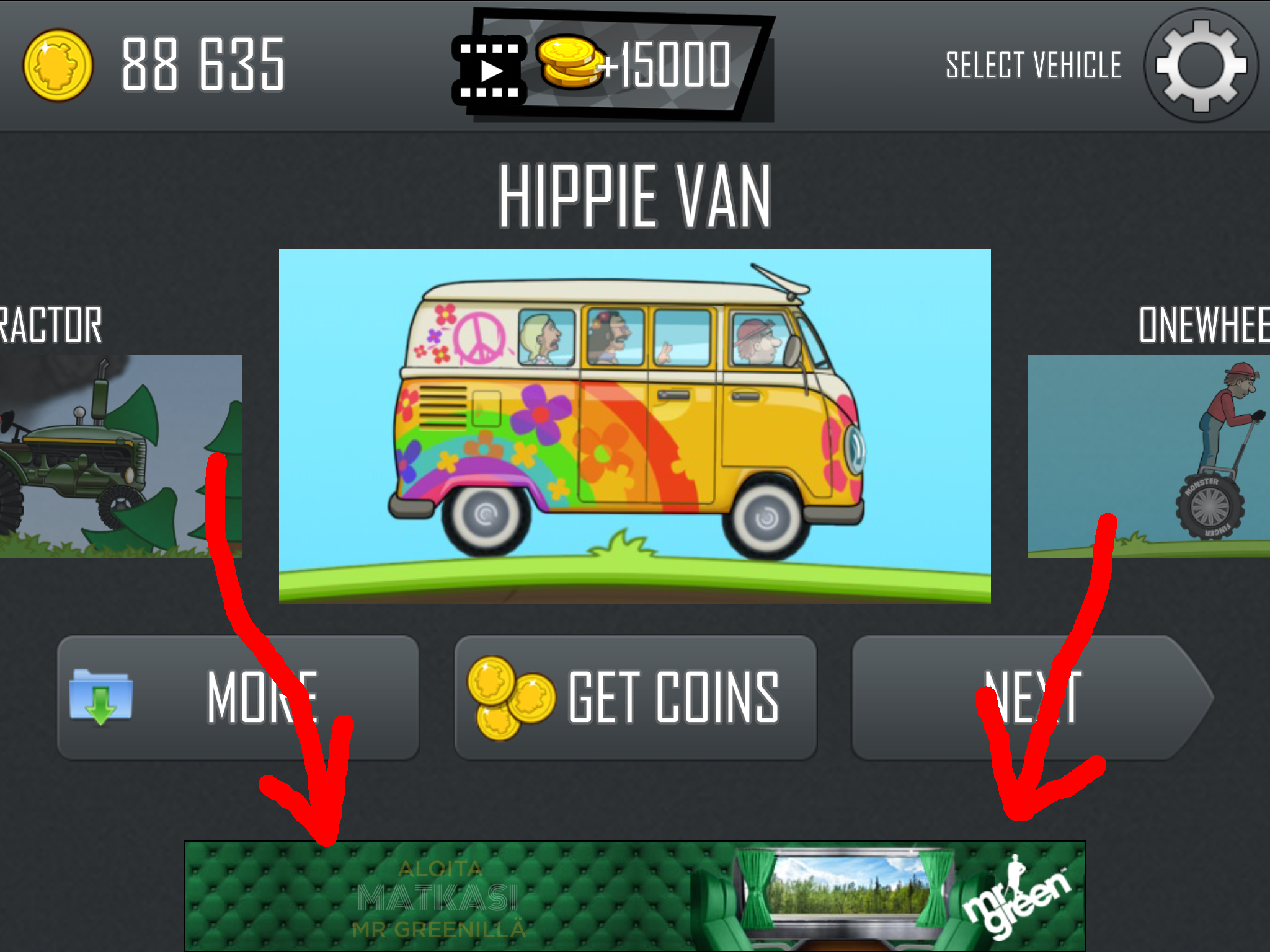
Pretty much every game has those. The worst thing about those is, that they consume a lot of resources on your mobile. This is the article about the 2012 study: Free apps eat up your phone battery just sending ads and a summary of the scientific study made in Purdue University: Free apps drain smartphone energy on 'advertising modules'. The outcome is:
The free Angry Birds app was shown to consume about 75 percent of its power running "advertisement modules" in the software code and only about 25 percent for actually playing the game. The modules perform marketing functions such as sharing user information and downloading ads.
How do you comment that? You're just running advertisements, not the game.
Btw. I subscribed Wired for $1 USD / week and keep running my adblockers. Their material is good, it's definitely worth that money. I applaud them just because they are inventing such things like that.

