Microsoft buying Nokia's mobile phone business
Tuesday, September 3. 2013
This has been in the rumors for a long time. The Finnish pride Nokia chose to exit their Devices & Services branch now that Lumia phones are finally getting popularity. It is kind of a sad day for Finnish ICT-industry as the biggest company divests roughly half of itself with a very cheap price. Lot of people, including me, were waiting for Microsoft to buy out entire corporation. Any business transactions of this size take months to prepare, if not years. So, most of the rumors from early 2013 appeared to be true. Our beloved (NOT!) "mole-man" or "Microsoft agent" Mr. E-flop managed to push the corporation's value down so that his seat for CEO of Microsoft could be granted with this move.
This is also a good day for Finnish ICT-industry, as lot of what-iffing can stop, and people can concentrate doing actually good things.
Bullshit floating around:
- Part of Finnish national identity was lost: Sure thing, Nokia was our own pride and joy, but things keep changing get used to it! After all Nokia did fuck up their own business with having too much pride for not to see what others were doing. Not to mention their horrible reorganizations that managed to completely kill their ability to innovate. I was proud what they did in the 90s and how they ruled the mobile world then, but not how they managed to get too cocky in the 00s.
- Nokia was about to go bankrupt: No, according to their Q2 2013 interim report, they had assets for 4,4 billion €, does not sound like bankrupcy to me
- Nokia was about to abandon Windows Phone and go to Android: I don't think so, Lumia was starting to sell like hotcakes
- Press is stating that "Microsoft bought Nokia": Idiots! No they did not! They purchased Devices & Services division. Lot of Nokia is still left. Neither did Google acquire Motorola, they just got Motorola Mobility division. There is a difference there.
- Nokia should have chosen platform X instead of Windows Phone:
- Apple iOS: really not available
- Blackberry: perhaps, ready platform, low on features, but Nokia guys could have done something with it, not as ready-to-go as they'd hope
- Palm / webOS: naah, too old crap, HP was ready to eject it, though. Price would have been cheap, but same story as Blackberry.
- Nokia's own MeeGo: Technically superior to anything, the trouble was that they put a lot of money into it, and due to their own organization's mis-management they could not produce anything real in time and decided to sink it. New platform is lacking developer community, though. Ex-Nokia people bought it and formed a new company Jolla.
- Android: Buggy, insecure, totally dominated by Asian companies like Samsung, LG and HTC. Really difficult to create something innovative with cheaper price. Totally out of the question.
- Windows Phone: History has proven that Nokia really managed to get it working. Trouble is that Microsoft has very slow development cycle. They're not accustomed working in mobile field at all. Perhaps Microsoft will now detach Windows Phone from Windows completely and allow them to move rapidly.
- Microsoft made a mistake when they did the acquisition: I don't think so. Their PC-business is fading and they really want to expand. Mr. Ballmer has set the vision to be a devices & services business and that's what they bought.
- Finland will lose lot of ICT-jobs: Why would Microsoft move the mobile phone development to Redmond? They have a proven track record of that not working.
 Also what many people are afraid of, is Microsoft scaling down the mobile business. Why would they do that? They just spent 5,4 billion € for it, why would they kill it after that? So, I don't think this will have a major impact on ICT-workforce.
Also what many people are afraid of, is Microsoft scaling down the mobile business. Why would they do that? They just spent 5,4 billion € for it, why would they kill it after that? So, I don't think this will have a major impact on ICT-workforce. - Nokia will have a grim future: Well, no. They divested the division not doing any profits. They kept their patent portfolio which is generating 1 billion € revenue each year. They have plenty of money, probably they'll just purhcase Jolla and start doing nice mobile phones again.
Huawei B593 4G-router dropping to 2G EDGE
Monday, September 2. 2013
My 4G-router drops to 2G EDGE after running couple of weeks. It's a really weird thing, since it does not do it always. Also the total on-line time is really weird. I hardly think that the on-line time can be 9 years or so.
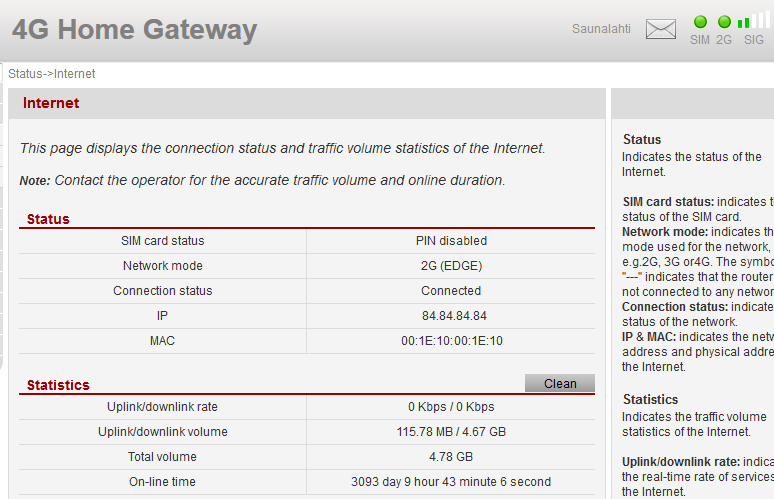
I could not find any other remedy to fix this, but to reboot. After that it does a scan for connections and finds 4G/3G/2G and chooses the fastest one like it should do.
This is just a nuisance. I'd expect the box to be a little bit more robust.
The on-line time calculator -thing is a really weird one. It seems to jump 200 days during 8 hours when it feels like doing it. Apparently the entire calculator is busted.
Changing network location on Windows 8 and 2012
Saturday, August 31. 2013
Is it just me, or has somebody at Microsoft really dropped the ball on network location setting? When a Windows computer detects a new network, which it has not be attached into earlier, it pops you the question and asks about how to profile the security in that particular case. If everything goes ok, there is no need to change anything. However, when you install your computer, you don't get to answer that. Also, there is commonly known that people make mistakes. What if you simply fumbled the question and clicked wrong.
In Windows 7 the setting is simple:
![]()
You go there, click the value and select a better one. In Windows 8, Windows 8.1, Windows Server 2012 and Windows Server 2012 R2 that is not the case. The setting cannot be changed. Period. Wtf?
![]()
There is a way to change the setting. I found this article with Google: How do I set my wireless network to be private instead of public? The "Easiest" and "Most direct" are crap, IMHO. The part with Local Security Policy seems to work:
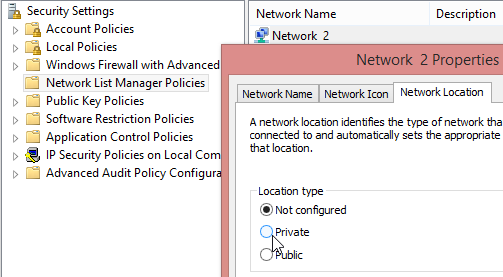
That seems to be working from Windows 7 onwards. Whose bright idea it was to make the change that difficult?
Acronis 2014 released
Friday, August 30. 2013
Using the DMZ-setting of Huawei B593
Thursday, August 29. 2013
My previous post about my Huawei B593 4G-router has become quite popular, so I thought to tell more about my setup.
What I'd really need is a network bridge, so that my Linux-box would be the one getting a dynamically changing public IP via DHCP. Understandably it simply cannot be done with a mobile router. In UMTS-network, the mobile terminal will negotiate a data connection and get the IP-address associated with the connection. There literally is no chance for my router to do that via B593. Using an USB-based mobile terminal such a feat could be achieved, for example my Huawei E160 gets an IP-address directly to the Linux. No 4G LTE, though. So, I'll be sticking with my B593 for a while. See an example of a transfer speed measurement @ Ookla Speedtest.net. Not, bad huh?
I also did investigate if the box would be based on Linux. Huawei has some GPL-components in the firmware, but they don't release BusyBox nor Dropbear source. It is possible, that they are using something of their own make or simply don't have a prompt or are not using Linux at all. The reason I'd like to see them is that both BusyBox and Dropbear SSHd are very typically used in Linux-based hardware.
Doing a port-scan from LAN-side to B593 reveals, that it has something there:
Not shown: 995 closed ports
PORT STATE SERVICE
22/tcp filtered ssh
23/tcp filtered telnet
80/tcp open http
443/tcp open https
631/tcp filtered ipp
MAC Address: F8:3D:FF:F8:3D:FF (Huawei Technologies Co.)
... but since all the nice stuff (SSH and telnet) are filtered, I don't know if there are actually any services listening to those ports.
To repeat: to my understanding, a bridging firmware cannot be done. However, something very similar can be achieved, it has a DMZ-setting. See:
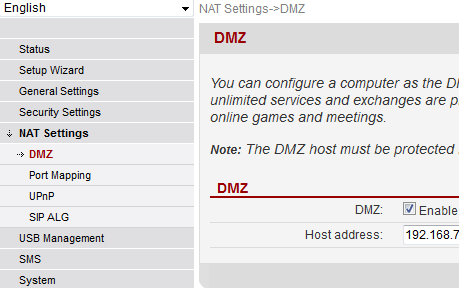
It says "You can configure a computer as the DMZ host that is exposed to the Internet so that unlimited services and exchanges are provided between the host and Internet, for example, online games and meetings." in the page. That is pretty much same as bridge.
I had to test if it really would work. I took a hping-utility for crafting raw IP-packets and ran:
hping -c 1 -n <-da-IP-address-here> -e "AAAA" -0 --ipproto 41
That sent a single (-c 1) raw IP-packet (-0) and stamped the outgoing packet a IPv6-encapsulation protocol (--ipproto 41). If the Huawei would have a simple UDP & TDP forwarding, such a packet would never pass trough.
On my Linux it said:
16:15:50.115851 IP sending.host.com > receiving.host.net: [|ip6]
16:15:50.115920 IP receiving.host.net > sending.host.com: ICMP host receiving.host.net unreachable - admin prohibited, length 32
Goddamn! It works! The packet properly passes trough.
My conclusion is that the DMZ-function is actually usable. Apparently there is no need for SSH-prompt -based configuration tweaking. It would always be nice, though. All Linux-nerds like me simply love to go to the prompt and type cat /proc/version and cat /proc/cpuinfo and boast about their hacking abilities to anybody who cares (not) to listen.
IPv6 through WLAN access point revisited
Wednesday, August 28. 2013
This is a follow-up for my previous article about running IPv6 and WLAN access point. There I said "This was actually very easy to do into DD-WRT" and now I'd like to take that back.
It seemed to be easy, but ... Here are my settings in detail. Btw. I'm running DD-WRT v24-sp2 big
Release: 07/24/13 (SVN revision: 22118)
1. disable the autoconfiguration from the WLAN access-point and manually define a static IPv6-address
This is the part which I struggled the most. Sure it is easy to remove the manually assigned IPv6-address from an interface, just run:
ip -6 addr delete 2001::-da-IP-here-/64 dev br0
on a shell. It will drop the autoconfigured address and it will stay away. For a while. It surely won't survive a reboot.
To make this stick, go to web GUI Administration --> Commands and add a startup command:
echo 1 > /proc/sys/net/ipv6/conf/all/forwarding
echo 0 > /proc/sys/net/ipv6/conf/all/autoconf
echo 0 > /proc/sys/net/ipv6/conf/all/accept_ra
echo 0 > /proc/sys/net/ipv6/conf/all/accept_ra_pinfo
/usr/sbin/ip -6 addr add 2001:-da-IP-here-/64 dev br0
That makes the settings stick. Autoconfiguration will be gone and a static address will be assigned instead. I attempted at least 20 different combinations while looking the sysctl-settings list, but that was the 1st one I found to be actually functional for deactivating the autoconfig.
2. use a static default route from the WLAN access-point and confirm that it has proper IPv6-connectivity
4. make sure, that any incoming traffic from the mobile clients is
properly routed to the real IPv6-router, and confirm that traffic flows
both ways
Yet again, go to web GUI Administration --> Commands and add a startup command:
/usr/sbin/ip -6 route add default via 2001:-da-router-IP-here-::1 metric 1
That creates a static route which will work and fulfill the 2). To achieve 4) make sure to have the metric 1 at the end.
3. run router advertisement daemon (RADVD) to advertise the WLAN access-point as a proper router for any wireless clients
In the DD-WRT IPv6 article it said that RADVD configuration should be like this:
interface br0 {
AdvSendAdvert on;
prefix 0:0:0:1::/64 {
AdvOnLink on;
AdvAutonomous off;
};
};
Don't do that! DON'T! It will royally fuck up your LAN. Nothing in IPv6-land will work if you literally copy/paste that like they suggest. The problem is with the prefix of 0:0:0:1::/64, it will assume that your network has that /64-prefix and assign route and IP-address for any IPv6-host with that prefix. I can bet you $1.000.000 dollars, that it will not be your IPv6-prefix. ... and win.
Just put the exactly same prefix your real IPv6-router has. The WLAN access point's RADVD should be configured pretty much exactly alike. For the configuration directives see radvd.conf manual-page. It literally says:
- AdvSendAdvert: do send advertisements, default is off
- AdvOnLink: use the prefix for link determination (meaning: yes you can get to The Net via this), it is on by default, you really don't need this line at all
- AdvAutonomous: do distribute new the IP-addresses from this RADVD to your wireless (and wired) clients, yet again it is on by default and you really don't need this
With these settings I succeeded a reboot and still had my wireless and wired clients working using either of the two IPv6-routers. On Windows the setup will display two default routes, like this:
PS C:\Windows\system32> netsh interface ipv6 show route
Publish Type Met Prefix Idx Gatewa
------- -------- --- ------------------------ --- ------
No Manual 256 ::/0 18 fe80::
No Manual 256 ::/0 18 fe80::
On Linux:
# ip -6 route show | fgrep default
default via fe80:: dev eth0 metric 1024 expires 0sec mtu 1280 hoplimit 64
default via fe80:: dev eth0 metric 1024 expires 0sec mtu 1280 hoplimit 64
That's ok. IPv6 will support that ok. Just be aware, that your traffic may route either way.
Windows IPv6 connection starting to "rot" over time [Solved!]
Tuesday, August 27. 2013
I've been using IPv6 on my own LAN for years. Most of the things I use on daily basis have IPv6 and it seems to work. For example a Sony television or iPhone 4S does not use IPv6, but iPad does.
On my router there is a Router Advertisement Damon to do stateless auto-configuration. On Windows 7 and 8 they have really weird things running out-of-the-box, but I'm in a habit of running (as admin):
netsh interface ipv6 set privacy state=disabled store=active
netsh interface ipv6 set privacy state=disabled store=persistent
netsh interface ipv6 set global randomizeidentifiers=disabled store=active
netsh interface ipv6 set global randomizeidentifiers=disabled store=persistent
netsh interface teredo set state disabled
That way I'm using fixed IPv6-addresses and disable the unnecessary Teredo-tunnel.
I don't exactly know why or how, but on one of my computers (running Windows 7), the IPv6-sockects started to not work properly. The symptoms include lot of reconnections and for example in SSH-client, the connection would simply drop. I did everything I knew, but nothing helped. A failing SSH-connection would look like this on the wire:
![]()
After 31 seconds of connection, there is a sporadic retransmission. That is not dangrous and it happens sometimes. My Windows 7 would respond with a duplicate ACK into it, waits 3 seconds and goes ballistic. It simply starts re-transmitting the already transmitted data with 1, 3 and 5 second intervals before determining that the connection has died. WTF?! The connection is not bad! It works on all other computers. The issue can be easily repeated and it works the same way every time. Windows thinks it needs to start a burst of re-transmissions and disconnects when they seem to fail.
During one of the Google-session for the fix, I found netsh interface ipv6 reset command. I tried it:
PS C:\Windows\system32> .\netsh.exe interface ipv6 reset
Reseting Global, OK!
Reseting Interface, OK!
Reseting Subinterface, OK!
Restart the computer to complete this action.
Did the Windows restart, ran the above commands to disable privacy, randomization and teredo-tunnel. Everything started to work! Whooo-hoo! Now my SSH-connections don't drop anymore. How cool is that!
The fix is very microsoft-ish. Some counter ticked into illegal value and in their mind the correct fix is to reset everything to the post-installation state. On *nix-world network-stack -code would be of much better quality and the entire issue would never happen!
What programming languages to learn?
Monday, August 26. 2013
This is a classic question which I get to answer a lot. N00bs know the answer, but somebody outside the IT-business might ask something like that. This is also quite a popular question among young people trying to figure out if programming would be for them.
Anyway, here 5 Programming Languages Everyone Should Know from two people who actually have created some of the most popular languages currently used.
Nobody should call themselves a professional if they knew only one language.
- Bjarne Stroustrup
Larry Wall
See his interview: http://youtu.be/LR8fQiskYII
His list:
- JavaScript
- Java
- Haskell
- C
- Perl
Perl is not a surprise in his list. He created it in the 80s.
Bjarne Stroustrup
See his interview: http://youtu.be/NvWTnIoQZj4
His list:
- C++
- Java
- Python
- JavaScript
- C
- C#
Again, seeing C++ in his list is not a big surprise, he was one of the authors of the language in the 80s. The funny thing is that he mentions 6 languages.
Linus Torvalds
This two year old interview keeps popping up. In this video http://youtu.be/Aa55RKWZxxI mr. Linux mentions one programming language not to use.
The again, this person is well known from his more than colorful opinions about various issues. But anyway his work on Linux kernel and Git version management are well known, he is a fan of C.
me
Being a blog-author I have to express an opinion of my own. To solely copy/paste opinions of three very skilled persons is too much of a cheap thing. So, here goes:
- C
- Pretty much all languages created after 1970 owe something to C, it is imperative to know this.
- JavaScript
- When doing any kind of web-stuff, this is the only language being used in 100% of the cases. All browsers run this and it is the de-facto client-side language today.
- C#
- Very versatile compiled language by Microsoft, has lot of influence from C, C++, Java, PHP, Perl, etc. the list goes on. It is mainly used with .Net to create server-side stuff.
- PHP
- IMHO the most important web-server language there is. This is wildly popular and shares similarity with C, JavaScript, Perl, Visual Basic, etc.
In addition to learning programming languages, I encourage everybody to learn also following widely popular frameworks:
- Microsoft .Net
- Zend Framework
My reasoning between this is that if you understand how they work, you're pretty well covered and also going to Python/Django or Ruby on Rails is much easier task. I know that these are web-frameworks and people program a lot other stuff than web, but sticking to the topic of what languages to learn, these are the first ones to try. There are so many other frameworks, especially in PHP-land, but they don't have such an essential position as the framework made by people who created the PHP-language. In Microsoftland there are no other significiant frameworks to learn. Anyway, both are properly documented and lot of information can be found of them.
Exploring Dijit.Editor of Dojo toolkit
Sunday, August 25. 2013
My favorite JavaScript-library Dojo has a very nice HTML-editor. During a project I even enhanced it a bit. Anyway the Dojo/Dijit-documentation is not the best in the world, so I'll demonstrate the three operating modes that are available. All of them have the same functionality, but how they appear visually to the person doing the HTML-editing differs.
Classic fixed size
This is the vanilla operating mode. From the beginning of time, a HTML <TEXTAREA> has been like this (without any formatting, of course). A fixed block-container of multi-line text editor which will scroll on overflow.
Example:
![]()
HTML for declarative instantiation:
<div id="terms-Editor" data-dojo-type="dijit.Editor"
height="150px"
data-dojo-props="extraPlugins:['insertanchor','viewsource']">
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit.</p>
</div>
There is really nothing special, I'm just using two extra plugins insertanchor and viewsource to produce two new icons to the editor toolbar to add functionality for the end user. I found out that the plugins really need to be all lower-case for them to load properly. The class-names and filenames are in CamelCase, but putting them like that makes loading fail.
The obvious thing is that the editor is 150 pixels high. I didn't set the width, but since the editor is a simple div, any size can be set.
Auto-expanding
This is a plugin expansion for the previous. The only real difference is that this type of editor does not overflow. Ever. It keeps auto-expanding to any possible size to be able to display the entire text at once. During testing I found out that the auto-resize -code does not work on all browsers. There seems to be a discrepancy of exactly one line on for example Chrome. The bug manifests itself when you try to edit the last line, pretty much nothing is visible there. I didn't fix the bug, as I concluded that I won't be using this mode at all.
HTML for declarative instantiation:
<div id="terms-Editor" data-dojo-type="dijit.Editor"
height="" minHeight="100px"
data-dojo-props="extraPlugins:['alwaysshowtoolbar','insertanchor','viewsource']">
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit.</p>
</div>
This has three things to be taken into notice:
- The auto-expansion is achieved by plugin called alwaysshowtoolbar. It does not work in current Dojo version of 1.9.1, I had to fix it. See the patch at the end of this post.
- It is absolutely critical to set the height="". Forget that and the alwaysshowtoolbar-plugin does not work.
- It is advisable to set a minimum height, in my example I'm using 100 pixels. The editor will be really slim, if there is no text. This sets the size into something visually appealing.
Manually resizable
This is how a <TEXTAREA> behaves on many modern browsers. When using plugin statusbar you'll get a handle to resize the block. During testing I found out that it is a bad idea to allow the user to be able to make the editor wider. I enhanced the class with additional parameter which gets passed to plugin's constructor to limit the ResizeHandle functionality.
Example:
![]()
HTML for declarative instantiation:
<div id="terms-Editor" data-dojo-type="dijit.Editor"
height="200px"
data-dojo-props="extraPlugins:[{name:'statusbar',resizeAxis:'y'},'insertanchor','viewsource']">
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit.</p>
</div>
Note that specifying the resizeAxis won't work in your code. If you really want the code I can e-mail it to you, it is longish enough for me not to post it here. The height is 200 pixels initially, but user can make the editor any size.
Hope this helps to clarify the complexity of this fine editor. It would be also nice if a filed bug report would be processed in Dojo-project. Also their discussion in Google Groups is closed, the group is set to moderate any posts, but there is nobody doing that. So, effectively new people cannot post. There is nothing left, but to complain in a blog.
Appendix 1:AlwaysShowToolbar.js patch to fix the plugin-loading
--- dojo/dijit/_editor/plugins/AlwaysShowToolbar.js.orig 2013-07-19 13:21:17.000000000 +0300
+++ dojo/dijit/_editor/plugins/AlwaysShowToolbar.js 2013-08-02 17:31:44.384216198 +0300
@@ -13,7 +13,7 @@
// module:
// dijit/_editor/plugins/AlwaysShowToolbar
- return declare("dijit._editor.plugins.AlwaysShowToolbar", _Plugin, {
+ var AlwaysShowToolbar = declare("dijit._editor.plugins.AlwaysShowToolbar", _Plugin, {
// summary:
// This plugin is required for Editors in auto-expand mode.
// It handles the auto-expansion as the user adds/deletes text,
@@ -198,4 +198,11 @@
}
});
+ // Register this plugin.
+ // For back-compat accept "alwaysshowtoolbar" (all lowercase) too, remove in 2.0
+ _Plugin.registry["alwaysshowtoolbar"] = _Plugin.registry["alwaysshowtoolbar"] = function(args){
+ return new AlwaysShowToolbar();
+ };
+
+ return AlwaysShowToolbar;
});
IPv6 through WLAN access-point
Wednesday, August 21. 2013
I had a glitch with my DD-WRT -setup as it failed to pass-trough native IPv6-traffic on my own network. It took me a while to understand why only IPv4-traffic was getting trough it, but I managed to get it working. Here is my setup:
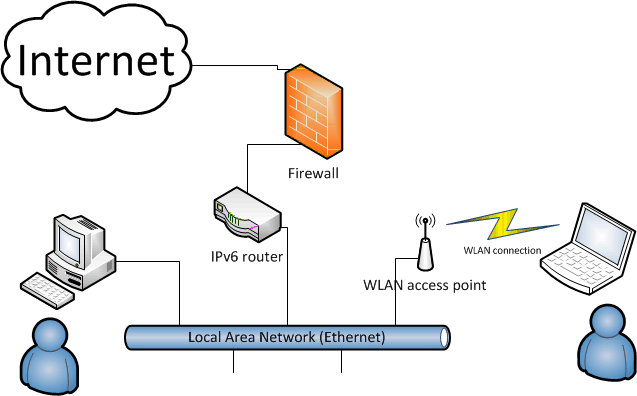
It is pretty trivial, the internet connection goes trough firewall and a router. Behind the router, there is my wired Ethernet and wireless connection to mobile devices. I had no issues with wired devices, IPv6 was working fine, so I guessed my WLAN-setup was flawed.
A closer inspection revealed, that my DD-WRT was configured to use IPv6 Stateless address autoconfiguration. This is part of IPv6-specification and a closer inspection of the traffic reveals, that autoconfiguration is done with couple of specially crafted ICMPv6-packets. I bumped into Mr. Matt Brown's blog, which pointed me to the RFC 4862 which defines the protocol. It states that there exists two kinds of nodes:
- router - a node that forwards IP packets not explicitly addressed to itself
- host - any node that is not a router
Then it struck me:
My WLAN access-point is considered a router, altough it is a bridge by definition, but for the sake of IPv6 autoconfiguration it is a router. As it came out, the autoconfiguration packages are using link-local addresses from address-space of fe80::/64, which by definition won't survive a hop over a router. (Which in my mind I didn't have, it was a WLAN bridge!)
The plan was to:
- disable the autoconfiguration from the WLAN access-point and manually define a static IPv6-address
- use a static default route from the WLAN access-point and confirm that it has proper IPv6-connectivity
- run router advertisement daemon (RADVD) to advertise the WLAN access-point as a proper router for any wireless clients
- make sure, that any incoming traffic from the mobile clients is properly routed to the real IPv6-router, and confirm that traffic flows both ways
This was actually very easy to do into DD-WRT. After disabling and enabling the wireless interface on my Windows 8, I finally got a default route:
PS C:\Windows\system32> netsh interface ipv6 show route
Publish Type Met Prefix Idx Gateway/Interface Name
------- -------- --- ------------------------ --- ------------------------
No Manual 256 ::/0 18 fe80::c2c1:c0ff:c2c1:c0ff
This was nice! Everything simply started working. What I'm still looking for are ways of getting the default route without disable/enable for the interface. Both, on Linux and Windows.
NTPd vs. Chrony
Monday, August 19. 2013
In my Fedora 19 I've been wondering why my NTPd does not start on boot. It used to do so couple of Fedora installations ago. This is not a big deal, so I've been mostly ignoring it. Today I dug up some energy to investigate.
The reason was much simpler than I tought. On my very short checklist were:
- Confirm that systemd has ntpd.service enabled, it was.
- Confirm that ntpd.service has a dependency to start the service after network interfaces are up, it was chained to do a single ntpdate update and start the daemon after it.
- Needed interfaces have not been blocked and/or needed interfaces have been enabled in config, everything was out-of-the-box: all network interfaces allowed.
The daemon even had the panic-threshold disabled in the config, so it wouldn't choke on startup if time was badly off for some reason. I found no reason for the daemon to start.
However, doing a search for ntpd in /usr/lib/systemd/system revealed what was going on. chronyd.service has Conflicts=ntpd.service in the service description. WTF?! What the hell is chronyd?
According to http://chrony.tuxfamily.org/ it is "a pair of programs which are used to maintain the accuracy of the system clock on a computer". Sounds like a NTPd to me. Running netstat confirmed the fact:
# netstat -nap | fgrep :123
udp 0 0 0.0.0.0:123 0.0.0.0:* 666/chronyd
udp6 0 0 :::123 :::* 666/chronyd
The daemon does bind to NTP-ports. To get chronyd running properly, all I had to do was add proper time source and allowed updates from my LAN with allow-directives.
That's it!
Linux failing to mount iSCSI on boot
Thursday, August 15. 2013
My Fedora 19 failed to boot if I had an entry for an iSCSI-mount in /etc/fstab. During boot the system just fell to emergency mode. To get the box to boot, I simply did a "stupd man's solution", and commented the line out. This is what happens if I have the standard line in fstab:
![]()
My fstab line is:
/dev/qnap /mnt/qnap ext4 defaults 1 0
It took me a while to get back to the issue and investigate, it was that bad. This is the clue I found on Fedora project's documentation about iSCSI. They said, that any iSCSI-volumes should be mounted with a special flag _netdev. I changed to that, and hey presto! During bootup, it first does something and then mounts the iSCSI-drive. I merged those two occurrences into a single photo:
![]()
It works! I'm so happy about this. For clarity, the fstab-line is:
/dev/qnap /mnt/qnap ext4 _netdev 0 0
QNAP Turbo NAS firmware version 4
Wednesday, August 14. 2013
QNAP released their version 4 firmware. Its GUI has iPad-look and feel and is a major improvement overall. It has all the existing features (actually I don't know of any new interesting things), but the management interface has been completely re-written. It responds much faster and is really nice to use. Actually the version 3 GUI was very, very slow to log-in or respond to a click. It looks like this:
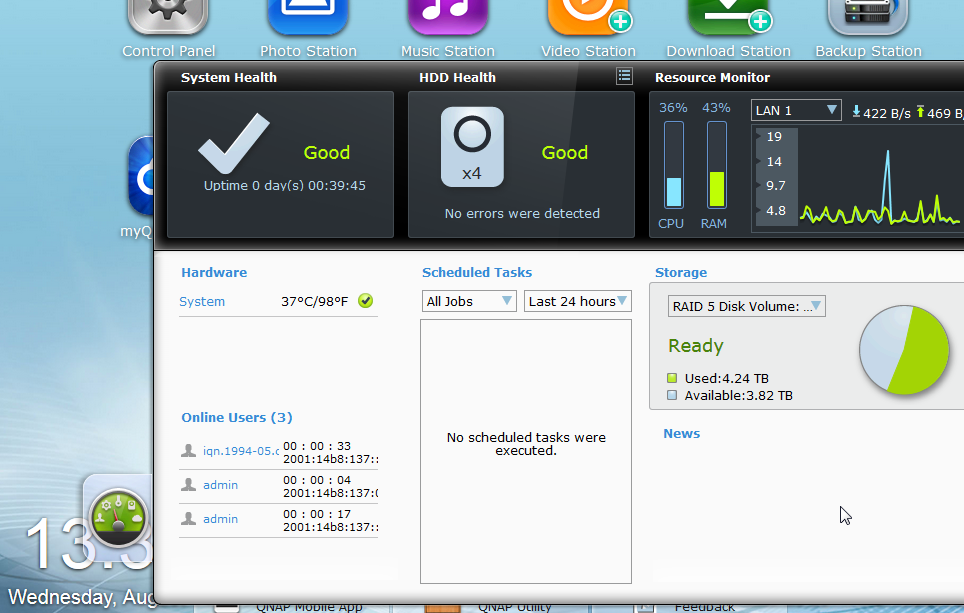
The only thing I noticed that didn't work was date/time settings. It chose a GMT-12 time zone for some reason. It does work in the background, I'm using Europe/Helsinki TZ and it shows EEST correctly on SSH-connection:
[~] # date
Wed Aug 14 13:24:52 EEST 2013
Also, I noticed that daylight savings time -setting displays the correct TZ.
To fix the NTP-client I did following:
# /sbin/setcfg NTP "Server1 IP" -my-IP-here-
# /etc/init.d/ntpd.sh stop
# /etc/init.d/ntpd.sh start
This does not reflect the change to the GUI.
Anyway, I'm looking forward to see the next firmware to fix those issues.
Own RPM package: Make symlink survive update/freshen
Friday, August 9. 2013
During my ventures in the Linux-land, I constantly package and re-package RPMs. Sometimes to introduce new functionality to existing package or to simply get a newer version that distro vendor is prepared to offer. Number of times I've created packaging to software that is not in the distro at all.
Another thing I love using are symlinks. I can have newer and older package of a software and can simply switch with updating the symlink into correct version. When I combined those two, it bit me in the ass.
I had quite simple script-blocks to handle the symlink:
%post
cd /my/package/directory/
%{__rm} -f my.cool.symlink-name
ln -s package/library/my.cool my.cool.symlink-name
%preun
%{__rm} -f /my/package/directory/my.cool.symlink-name
On install, that worked, but on update/freshen there was no symlink left. I was puzzled, why is that? Little bit of googling revealed two pieces of information: RPM spec-file documentation about scripts, especially the Install/Erase-time Scripts -part and 2nd the Fedora Project's packaging information, especially the scriptlet ordering. I'll abbreviate the Fedora's ordering here omitting the non-interesting parts:
- %pre of new package
This is the part where my script confirms that the symlink exists. - (package install)
- %post of new package
- %preun of old package
During update/freshen, this is the part where my script removes the symlink created in 1.)
Crap!
- (removal of old package)
- %postun of old package
Further reading of RPM spec-docs said "the argument passed to version 1.0's scripts is 1". Ok, nice to how, but now what? How can I utilize the information? What is the exact syntax for the script? The only usable information I found was in the Fedora packaging instructions, there was an example:
%preun
if [ $1 = 0 ] ; then
/sbin/install-info --delete %{_infodir}/%{name}.info %{_infodir}/dir || :
fi
So this was the thing I had to try. My solution is to change the %preun-block:
%preun
if [ $1 -lt 1 ] ; then
# This is really an un-install, not deleting previous version on update
%{__rm} -f /my/package/directory/my.cool.symlink-name
fi
I did that and upgraded the package. Poooof! The symlink was gone like there was no change at all. WHY? I upgraded the revision number of the package and upgraded again. NOW it worked! Nice.
There is a simple explanation what happened. It says in the Fedora project's order-list that "%preun of old package". OLD package! It works starting from the next update, but not on the first one.
Anyway I was delighted to get that one sorted.
Running Linksys E4200 access point
Thursday, August 8. 2013
I got one of Linksys wireless access points. The original idea was to install Linux into it with DD-WRT, but the operation failed miserably due the fact, that there are actually two kinds of E4200 APs. Guess who has the "wrong" kind. That would be my 3rd Linksys wireless access-point. I love their products due to extensive Linux-support and very high quality hardware. Now it looks like, this one didn't turn out like I planned.
Anyway, the thingie had a very old firmware and I thought that it would be a good idea to upload the newest factory firmware into it. That failed immediately, all I got was a "Image File Is Incorrect" error message. The message was spat out from the GUI almost immediately, so I decided to debug it. Here is the code I found:
var len = F.file.value.length;
var ext = new Array('.','i','m','g');
if (F.file.value == '') {
alert(fwupgrade.upgradefile);
return false;
}
var IMAGE = F.file.value.toLowerCase();
for (i=0; i < 4; i++) {
if (ext[i] != IMAGE.charAt(len-4+i)){
alert(hupgrade.wrimage);
return false;
}
}
Nice! The manufacturer designated file of FW_E4200_2.1.39.145204.SSA hardly matches the required .img file extension. Also on the code side: is the way of checking for the file extension completely braindead, or is it just me? Guess what would happen, if the filename would contain less than 4 characters.
It was safe to rename the file and upload the firmware. It didn't brick the thing. There seems to be plenty of people having the same issue. The unit seems to have interesting ports open, nobody knows why. Here are the port scan results:
Starting Nmap 6.25 ( http://nmap.org ) at 2013-08-07 13:47 EEST
Nmap scan report for 192.168.1.1
Host is up (0.0017s latency).
Not shown: 992 closed ports
PORT STATE SERVICE
53/tcp open domain
80/tcp open http
139/tcp open netbios-ssn
443/tcp filtered https
445/tcp open microsoft-ds
8083/tcp open us-srv
49152/tcp open unknown
49153/tcp open unknown
MAC Address: 58:6D:8F:GG:2G:3G (Cisco-Linksys)
Nmap done: 1 IP address (1 host up) scanned in 1.32 seconds
There is a project to get Linux running on Marvell-chipsets also, but the site seems to be down. So, I'm linking the WikiDevi page instead: http://wikidevi.com/wiki/Linksys_E4200_v2
Hopefully that pans out and there will be support for DD-WRT some day.

