Setting up Azure AD Application from Azure DevOps pipeline Powershell task, Part 1 of 2: The theory
Monday, May 6. 2019
This one is about Microsoft Azure Cloud platform. Specifically about Azure DevOps Services. And specifically about accessing Azure Active Directory with appropriate permissions and changing settings there. For anybody knowing their way around Azure and Azure AD, there is nothing special about it. Tinkering with AD and what it contains is more or less business-as-usual. Doing the same without a mouse and keyboard is an another story.
Given the complexity of this topic, this part is mostly about getting a reader aligned what the heck I'm talking about. Next part is for a techical person to enjoy all the dirty details and code.
Disclaimer: If you are reading this and you're thinking this is some kind of gibberish magic, don't worry. You're not alone. This is about a detail of a detail of a detail most people will never need to know about. Those who do, might think of this as something too difficult to even attempt.
DevOps primer
When talking about DevOps (see Microsoft's definition from What is DevOps?) there is an implied usage of automation in any operation. In Azure DevOps (analogous with most other systems), there is a concept of "pipeline". It's the way-of-working and achieving results in automated way. There are inputs going to the pipe, then steps to actually do "the stuff" resulting in desired output. Nothing fancy, just your basic computing. Computers are designed and built for such tasks, eating input and spitting out output.
Going even further into the dirty details: What if what you desire is to automate the setup of an entire system. In any reasonable cloud system there are: computing to do the processing, pieces of assorted storage to persist your precious stuff, entry-points to allow access to your system and what not. As an example, your cloud system might consist of a: web server, SQL-database, Redis cache and load balancer. That's four different services to get your stuff running. Somebody, or in DevOps, someTHING needs to set all that up. 100% of all the services, 100% of all the settings in a service need to be setup and that needs to be done AUTOmatically. Any knowledgeable human can go to Azure Portal and start clicking to build the required setup.
Doing the same thing automated is couple difficulty settings harder. The obvious difference between a human clicking buttons and a script running is, that the script is a DOCUMENTATION about how the system is built. "I document my work!" some annoyed people yell from the back rows. Yes, you may even document your work really well, but code is code. It doesn't forget or omit anything. Also, you can run the same script any number of times to setup new environments or change the script to maintain existing ones.
Azure Active Directory, or AD
Most applications with or without web will never use AD. Then there are software developers like me, who want to store users into such an active location. Lots of other developers abandon that as too-complex-to-do and build their own user management and user vaults themselves with services of their own choosing. That's totally doable. No complaints from here. However, using ready-built authentication mechanisms by fine Azure devs at Microsoft make a lot of sense to me. You're very likely to simply "get it right" by reading couple of manuals and calling the designated APIs from your application. You might even get to be GDPR-compliant without even trying (much).
So, that's my motivation. Be compliant. Be secure. Be all that by design.
Azure AD Application
Most people can grasp the concept of Active Directory easily. When expanded to AD applications, things get very abstract very fast and the typical reaction of a Joe Regular is to steer away from the topic. If you want to use AD authentication for an application you wrote yourself, or somebody else wrote, this is the way it needs to be done. Not possible to avoid any longer.
So, now my application is compliant and secure and all those fancy words. The obvious cost is, that I need to understand very complex mechanisms, setup my services and carefully write code into my application to talk to those services I set up earlier. All this needs to be done correctly while nothing here is trivial. Couple dozen of parameters need to align precisely right. The good part in all that is: if you make a itsy bitsy tiny mistake, your mistake doesn't go unnoticed. Your entire house of cards collapses and your application doesn't work. No user can use the system. So, ultimately somebody notices your mistake! 
Since nobody loves making mistakes, that sure sounds something most people like to AUTOmate. I need to be sure, that with a click of a button all my settings are AUTOmatically correct both in Azure AD and in my own application.
Azure DevOps pipeline
To automate any setup in Azure cloud computing environment, the obvious choice is to use Azure DevOps. As always, there are number of options you can go with, but the fact remains: the most natural choice is to stick with something you already have, doesn't cost anything extra and is very similar to something you'll be using anyway. So, you choose to go with Azure DevOps, or Visual Studio Online or Team Foundation Services on-line or whatever it used to be called earlier. Today, they call it Azure DevOps Services.
In a release pipeline you can do anything. There are tons of different types of tasks available in out-of-the-box experience of Azure DevOps and you can install tons more from 3rd-party extensions.
Sample:
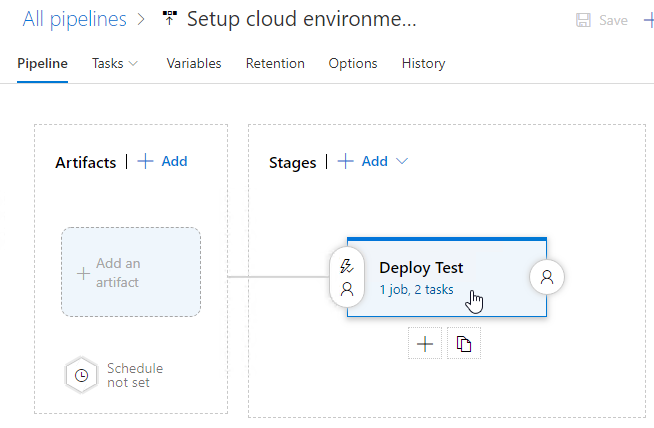
What I have in the above image is a screenshot from my Azure DevOps release pipeline. As you can see, it is a mockup, there is no source artifact it could consume. I was lazy and didn't do a build pipeline to create something there. But for the sake of this blog post, please imagine there being an imaginary artifact for this release pipeline to be able to function properly.
Anyway, there is a single stage called "Deploy Test" to simulate setup/maintenance of my Testing environment. There could be any number of stages before and after this one, but again, I was lazy and didn't do a very complex setup. As the image depicts, there is 1 job in the stage containing 2 tasks. A "task" in a pipeline is the basic building block. Defining a pipeline is just grouping tasks into jobs and grouping jobs into stages forming up the actual process, or pipeline of doing whatever the desired end goal requires. All this can be done in YAML, but feel free to wave your mouse and keyboard the do the same.
Azure DevOps pipeline task of a job of a stage
On the single stage this pipeline has, there is one job containing two tasks. The job looks like this:
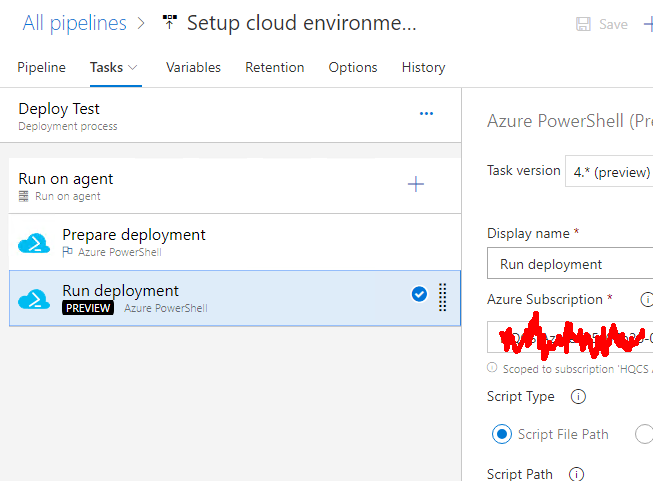
An Azure PowerShell task (read all about them from https://docs.microsoft.com/en-us/azure/devops/pipelines/tasks/deploy/azure-powershell) is a piece of PowerShell script run in a deployment host with a suitable Azure Service Principal (for some reason they call them Service Connections in Azure DevOps) having a set of assigned permissions in the destination Azure tenant/subscription/resource group. This is a very typical approach to get something deployed in a single task. Very easy to setup, very easy to control what permissions are assigned. The hard part is to decide the actual lines of PowerShell code to be run to get the deployment done.
Luckily PowerShell in Azure DevOps comes with tons of really handy modules already installed. Also, it is very easy to extend the functionaly by installing modules from a PowerShell repository of your own choosing on-the-fly in a task. More about that later.
Azure DevOps pipeline task doing Azure AD setup
That's the topic of part 2 in this series. Theory part concludes here and the really complex stuff begins.
Breaking the paywall
Wednesday, April 3. 2019
Newspaper media and magazines have been suffering from digitalization for two decades. Quite few of the traditional publishers have been struggling to keep their revenue stream flowing.
Back in the 90s Internet-boom they simply went to net "because they had to". No clue what to do there, though. Paper sales were going strong, no actions required. Then the obvious happened, people stopped subscribing their paper services. Meanwhile, same people who cancelled their subscriptions, were reluctant to pay for the service on the net. Reasons were multitude: bad implementation of the site, bad implementation of subscription and payment, etc.
Past couple years the trend has been to simply block readers out of the site by erecting a paywall. That will keep the free leechers out (like me), but I'm not certain it would improve the sales. Maybe it does, because lot of the media is doing that. However, yet again the implementation is really bad. There must be enough complexity in the paywall that people like me cannot simply run something like this in Javascript console:
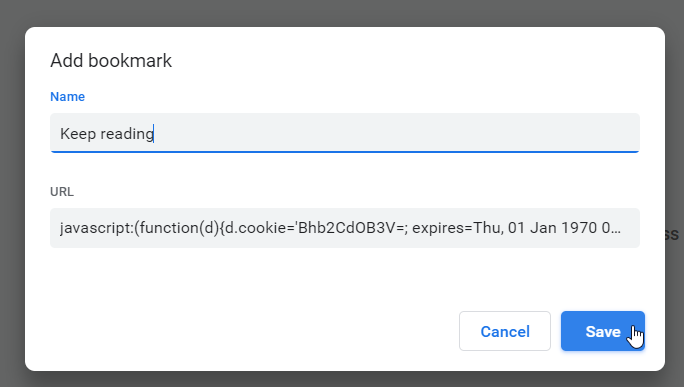
javascript:(function(d){d.cookie='Bhb2CdOB3V=; expires=Thu, 01 Jan 1970 00:00:00 UTC; path=/; domain=.tivi.fi;'})(document)
If you have no idea what a Javascript console is (most non-developer don't), don't worry. Here is the same thing as a bookmarklet. Concept of bookmarking sites into your browser is past gone, everybody just googles everything. Since nobody maintains bookmarks, it is not-so-user-friendly to manage bookmarks in a modern browser. However, the idea of you is to create a Javascript bookmark, aka. bookmarklet. In chrome, something like this:
Then it is easy to just click the bookmark when you run out of reads. Reload the page and keep reading!
Finally:
Apologies for the newspaper publisher for pissing in their coffee pot. Your product is good and I have enjoyed reading the articles, it's just the price point, you're too expensive! My motivation here is to offer you a pro-bono implementation evaluation. Hint: you failed badly.
I totally expect them to improve their implementation. Also I promise not to maintain any possible hacks their future versions may include. Also I'd like to offer a piece of advice.
There are two real options you can go with:
1) implement mandatory login
or
2) keep some articles free, some behind paywall. That seems to be the only working option of keeping people like me out of your system.
Azure support for cloud-dyndns Python-script
Monday, April 1. 2019
StackExchange flair received
Monday, March 11. 2019
Whoa! I finally hit the long awaited 200 point mark in Stack Overflow. The good part about that is, Stack Exchange starts publishing a public badge they'll call "flair". They do this to make it possible for me to publicly boast about my prowess. To get some public boasting going on, my flair looks like this:

All of you Peeping Toms out there, I'll save you couple keystrokes of googling: My ![]() public user profile is at https://stackexchange.com/users/1684769/hqjatu
public user profile is at https://stackexchange.com/users/1684769/hqjatu
Blog improvement: Responsive theme
Sunday, March 10. 2019
Going back in the memory lane, back in 2009 Mr. Wroblewski coined up a term "mobile first". At the time pocket computers, or not-so smart phones where a new thing, but booming heavily. First iPad wasn't out there and tablet computing was merely a curiosity. Still Mr. Wroblewski envisioned a future, where most of the web browsing would be done with a mobile device.
To state the obvious: Mr. Wroblewski was not wrong in his statement. His future vision started becoming a reality in April 2015 when Google as the #1 authority on website content, announced they would be demoting pages not being mobile user friendly. In November 2016 Google announced Mobile-first Indexing initiative. In March 2018 they followed up on that and started rolling out mobile-first indexing.
Rougly past 4-5 years this blog of mine has been suffering from this demotion and I really started taking the hit in 2018. Originally I chose this paper-style theme for this blog when I first created it in 2013, and it has been unchanged ever since. Not doing anything about it was an obvious mistake on my part. However, it took a while for Serendipity theme repository to even have properly implemented responsive design themes, so it was impossible for me to change the theme. Still, why would I even want to change the way my blog looks like!
Finally: I chose to improve the theme by making it responsive. In practice, I bootstrapped it with Bootstrap. This is a super-cool project originally created by few guys at Twitter. Read the Wikipedia article about that at https://en.wikipedia.org/wiki/Bootstrap_(front-end_framework). Getting to understand the 12 column grid system takes a while, but when you do the groundwork of arranging page content to rows and columns and realize that you can get six different chunks of display real estate by 1, 2, 3, 4, 6 and 12 columns depending on user's screen size, the results will be amazing! Most of this trickery doesn't even require any JavaScript to run. Adding floating navigation bars and such will require JS, but majority of the goodies work fully on bare HTML/CSS.
So, this is where I stared my journey with:
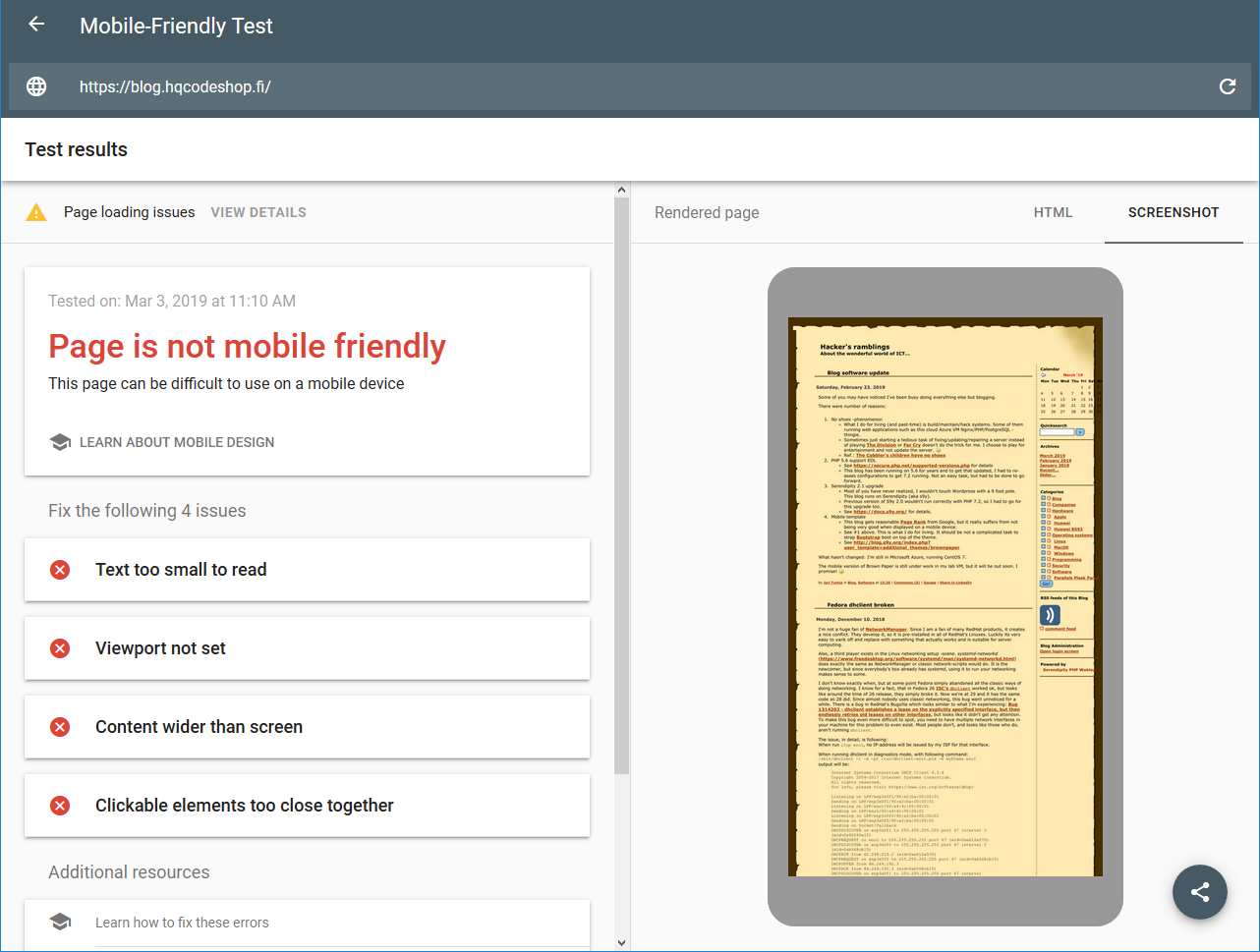
Google Mobile-Friendly Test spits out a lot of grievance from my blog.
This is the result with this new theme applied:
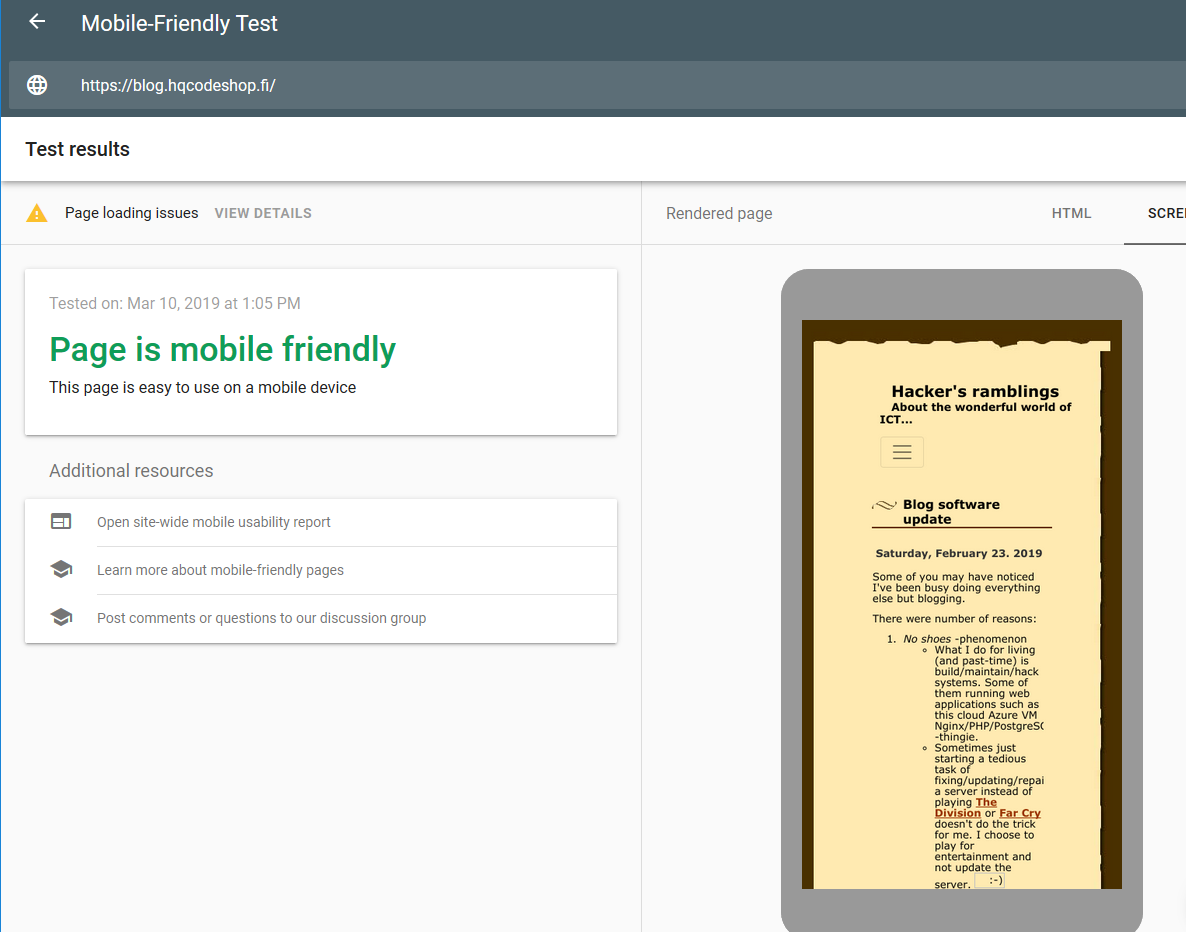
Oh yeah! Now GoogleBot should be much happier with this one. For those of you who want to play around with this, just go make the browser window very narrow and see the point where screen breaks and drops the right side menu off. To access the goodies on right side menu, a hamburger menu will be added to the top of the page.
GoogleBot tester isn't completely happy about my page, there are some load errors. However, I'm not sure exactly what the load errors are as they're labeled "other". Tons of people in The Net are suffering the same. Warning says:
Page partially loaded
Not all page resources could be loaded. This can affect how Google sees and understands your page. Fix availability problems for any resources that can affect how Google understands your page.
Based on lot of other people's comments found in web, the "errors" are merely warnings and they may or may not reduce the page rank. I'm agreeing with some people commenting, that the test Googlebot smartphone client is using super-short timeouts forcing people to optimize their websites to do as little loading as fast as possible.
The standard disclaimer applies:
If any of you think, that this theme doesn't work properly or I did something wrong. Drop me a comment or go to my Github fork at https://github.com/HQJaTu/additional_themes/tree/brownpaper-r2 and create a new pull request. I'm more than interested in keeping this new theme running optimally.
RouterPing - Gathering ICMPv4 statistics about a router
Monday, September 24. 2018
Parsing multi-part sitemap.xml with Python
Wednesday, July 11. 2018
User experience (or ux) in a nutshell
Monday, July 9. 2018
DynDNS updates to your Cloud DNS
Sunday, April 15. 2018
Long live ReCaptcha v1!
Thursday, April 5. 2018
Ok. It's dead! It won't live long.
That seems to suprise few people. I know it did surprise me.
Google has had this info in their website for couple years already:
What happens to reCAPTCHA v1?
Any calls to the v1 API will not work after March 31, 2018.
Starting in November 2017, a percentage of reCAPTCHA v1 traffic will begin to
show a notice informing users that the old API will soon be retired.
Yup. This blog showed information like this on comments:

Now that the above deadline is gone, I had to upgrade S9y ReCaptcha plugin from git-repo https://github.com/s9y/additional_plugins/tree/master/serendipity_event_recaptcha. There is no released version having that plugin yet.
Now comments display the v2-style:

To get that running, I simply got the subdirectory of plugins/serendipity_event_recaptcha with the content from Github and went for settings:

I just filled in the new API-keys from https://www.google.com/recaptcha and done! Working! Easy as pie.
Update 5th April 2018:
Today, I found out that Spartacus has ReCaptcha v2 plugin available to S9y users. No need to go the manual installation path.
Monopoly
Sunday, January 21. 2018
Since most of the revenue earned by my empolyer comes from Candy Crush, a lot of swag around the office is somehow related. Very understandable, that.
This time we all got a Monopoly-game, but not the regular one everybody has been playing. Ok, to be entirely clear on this, threre are a minimum of 37 different language editions of the game, so in which country you spent your childhood, make it depend which streets the game you used to play has. Anyway, this is the Candy Crush -edition of Monopoly:

Also very understandably we did discuss different aspects of the game, one of them being about the winning tactics.
I started thinking, if it would be possible to just go to The Net and get some source code for a Monopoly-simulator and try to program some rules to a bot, which would then play against other bots and see which approach would be more likely to win in the long run.
Quite easily, I found a Python-version of the game by Juan Manuel Contreras from GitHub. Unfortunately, the work by him is quite unfinished, so I chose to fork it and continue from that point. I didn't touch the .py-files, only the Jupyter notebook -version of the game.
As a result of some weekend coding, I have:
- Class for user game logic
- Lots of game functionality, moving around, collecting rent, buying, selling, going bankrupt
- Winning the game
The resulting notebook is quite bug-free, but there are still some game rules, that aren't properly followed. Especially the situation where a player defaults, all the assets need to go to creditor. If creditor is another player, then to that, if bank, there needs to be an auction where other players may purchase the defaulting user's properties. Doing auctions between AI-players is not that easy, so none of that is implemented.
The same AI-module would be needed in a situation where a player lands on an unowned property. According to rules, that needs to be auctioned if the player doesn't want to buy it. Not so easy to do with Python.
Also, the Chance-cards are not implemented, so it is impossible to get a Get-out-of-jail -card. Yet.
By running the game in the sim for couple hundred times, I found that with 5 players, it is very likely to get into a situation where nobody can build houses/hotels. Also, if there are not many houses/hotels, the other players are unlikely to land on those properties and the game will run forever with all players accumulating wealth indefinitely. To get around that, I'm detecting such a situction and artificially doubling rents. That rule is not in the original Monopoly-rules. How human players would solve this situation is to trade/barter properties between each other to gain building rights. A thing not so easy to implement with any programming language.
That Python Monopoly -project was just a fun thing to do. I'm not sure if I'll continue it any further. The code is out there, if you're interested.
Perl - The most disliked programming language?
Sunday, November 26. 2017

As you can see the top-3 three really stand out of the rest! You can easily disregard 2nd and 3rd "best", as nobody really uses VBA or Delphi anymore. Unlike those, Perl is being used. Even your Linux has it installed. All, but the tiny distros pre-install it into base image. Also those popular Mint and similar have it as an option. The obvious reason why Perl is being installed used everywhere is the wide popularity back in the 90s. Perl pre-dates Linux and was pretty much the only scripting language in that era, if not counting BASH or Tcsh scripting. Then times changed and Perl paved the way for PHP, Ruby, Python and the likes.
I don't understand who would NOT love a programming language that can be written with shift-key pressed down all the time!
Here, I present some of the most beautiful pieces of code ever written in Perl (also known as Obfuscated Perl Contest):
- The 1st Annual Obfuscated Perl Contest, Best in "The Perl Journal" category:
package S2z8N3;{
$zyp=S2z8N3;use Socket;
(S2z8N3+w1HC$zyp)&
open SZzBN3,"<$0"
;while(<SZzBN3>){/\s\((.*p\))&/
&&(@S2zBN3=unpack$age,$1)}foreach
$zyp(@S2zBN3){
while($S2z8M3++!=$zyp-
30){$_=<SZz8N3>}/^(.)/|print $1
;$S2z8M3=0}s/.*//|print}sub w1HC{$age=c17
;socket(SZz8N3,PF_INET,SOCK_STREAM,getprotobyname('tcp'))&&
connect(SZz8N3,sockaddr_in(023,"\022\x17\x\cv"))
;S2zBN3|pack$age}
- The 4st Annual Obfuscated Perl Contest, 3rd in Do Something Powerful category:
$_=q(s%(.*)%$_=qq(\$_=q($1),$1),print%e),s%(.*)%$_=qq(\$_=q($1),$1),print%e
- The 5h Annual Obfuscated Perl Contest, Winner of The Old Standby category:
#:: ::-| ::-| .-. :||-:: 0-| .-| ::||-| .:|-. :||
open(Q,$0);while(<Q>){if(/^#(.*)$/){for(split('-',$1)){$q=0;for(split){s/|
/:.:/xg;s/:/../g;$Q=$_?length:$_;$q+=$q?$Q:$Q*20;}print chr($q);}}}print"\n";
#.: ::||-| .||-| :|||-| ::||-| ||-:: :|||-| .
Who would ever hate that?
Look! Even this kitten thinks, it's just a concise form of programming. Nothing to be hated.

Microsoft Azure: The remote server returned an error: (400) Bad Request - explained
Thursday, July 6. 2017
This article is specific to an attempt to upload a .vhd image. I did my tinkering with PowerShell running Add-AzureRmVhd command.
My attempt to upload was something like this (backtick ` is just a multi-line character in PowerShell):
Add-AzureRmVhd -ResourceGroupName blog `
-Destination https://blobs.blob.core.windows.net/vmimages/server.vhd `
-LocalFilePath '.\disk.vhd'
... and it failed. Exactly like many other people have experienced.
After a while of googling and reading docs, the entire problem/solution became apparent. I was reading article Introduction to Microsoft Azure Storage, which has following note in it:
Note
Blob storage accounts support only block and append blobs, and not page blobs.
To understand the gravity of that is beyond this blog post, but idea is that all .vhd images need to be on a page blob. So, I just created my Azure Storage Account wrong. This is the correct way of doing it:
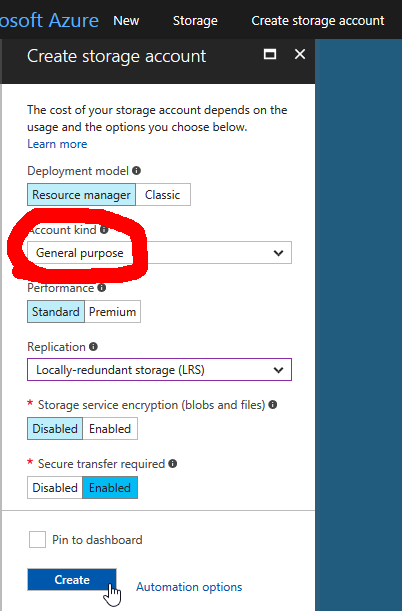
Make sure the Storage Account type is "General Purpose". To check what you have, go to properties:
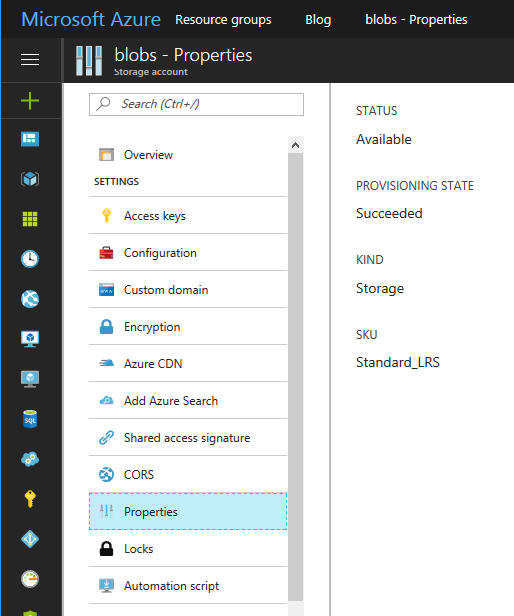
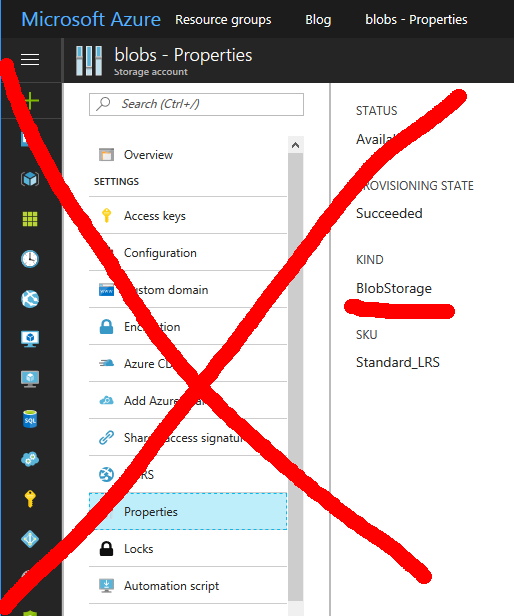
Your "Kind" of storage needs to be "Storage" for General Purpose. If you see "Blob Storage", you'll need to do another approach.
There are plenty of good and valid usage for Storage Account of "Blob Storage", but running your VMs isn't one of them.
Book club: Security Engineering
Monday, September 12. 2016
Every once in a while I have enough time to read books. The ones made out of paper having printed words and images on the paper. And pretty much 98% of the books I've read in the last couple of decades have something to do with my profession. There is one book, that's worth mentioning: Security Engineering by Ross Anderson.

The price point for getting this one is a non-issue, you can download the entire book as a PDF with no cost at http://www.cl.cam.ac.uk/~rja14/book.html (that's at University of Cambridge). Having the book available is fully intentional, as four years have passed, author and publisher have agreed to place the material freely available for anybody interested. I most sincerely thank Mr. Anderson of doing that.
Of yourse, I recommend you to support this good work and purchase one. Go to Amazon, or similar and get your own copy. It will include a digital copy, all you have to do is go to above link and download one.
I'd definitely recommend this book to anybody ever designing or implementing anything with a computer. As the phrase goes: “Smart people learn from their mistakes. But the real sharp ones learn from the mistakes of others.” This is your chance of getting ahead and learning how some smart people blundered in their design and/or implementation of security. There is so much information in the book, but I found the case studies being the best part. The general idea is to get an injection of experience and start to think like hackers do.
My recommendation is that, for anybody working in software engineering should memorize this book and have an exam taken, so that it is crystal clear how secure systems are done.
Purpose of Git by The Man himself
Monday, April 11. 2016
Two facts: I'm not a fan of Git, actually I dislike it very much. The second one is: I use git daily in my line of work. The (almost) third one is, that I'm pretty much alone with my thoughts.
Steve Bennet shares some of my dislikement, his blog posting 10 things I hate about Git is one of my definite favorites. Actually I don't agree on every one of his points there. Especially #8 I kinda think as a good thing to have and do.
So, my opinion is, that pretty much nobody should be using Git. That being said, it's the #1 version control tool used widely by every single major organization producing any software at all. For example Microsoft is (or at least was) putting lot of development hours into libgit to make it suit their needs better. It would be impossible to land a software development job today without any skills with git. It's a de facto thing among my peers. Its not going anywhere, at least anytime soon.
The reason why IMHO almost nobody should be using Git is that it suits everyday work poorly. If your everyday work is developing Linux kernel, then you're excluded. The tool will suit your needs perfectly. The reason is revealed by author himself in TED February 2016.

Go see the interview here.
So, here goes:

The purpose of Git is "only created for me to maintain my first big project", aka. Linux kernel. It's not meant for me, it's not meant for small or medium or large organizations to use. Git was meant for Mr. Torvalds to use and help his project management. No wonder I find it unsuitable for my line of work.

