Steam games installing DirectX on every start
Thursday, May 30. 2013
Parallels Plesk Panel 11 hangs on backup
Monday, May 27. 2013
For some unknown reason a customer's backup job hung. A ps axuww looked like this after a failed kill 3150 attempt:
3150 ? Z 0:00 [mysqldump] <defunct>
There was no other way of getting rid of that other than a reboot. It didn't help, though. It automatically re-started the backup job and did the same thing again.
All customer's services were disabled, there was Suspend domain until backup task is completed -setting enabled. At that point I was really screwed. The backup job turned undead and all customer's services were out of action. Nice going!  The message that was given from Parallels Panel at control panel was: "The subscription is temporarily suspended until the backup or restore process is complete".
The message that was given from Parallels Panel at control panel was: "The subscription is temporarily suspended until the backup or restore process is complete".
Parallels forums had an article about unsuspending a domain. I did the same thing for a subscription. Apparently at the time of writing in Plesk 9, there were no subscriptions. So I ran this:
/usr/local/psa/bin/subscription -u customer's domain name here.com -status enabled
It helped! It un-suspended the services. The backup is not working yet, but the services were running again. I need to further investigate the backup issue and get back about that.
Playstation 3 failing to load updates
Friday, May 24. 2013
Something really weird happened. My Playstation 3 refused to load updates. I retried at least 50 times, but it failed to load measly 24 MiB update from Sony.
A quick Google-search reveals, that plenty of people are suffering from this problem.
In my case the fix was to change wired connection into wireless. I have no idea what the difference is, but for some reason it did the trick.
Getting the updates into PS3 is rather complex as observed from the network traffic. An update is a HTTP-request and the load is split into 4 parallel loads. Example:
GET /tppkg/np/NPEB00874/NPEB00874_T8/0bbab4e7b137739f/EP4350-NPEB00874_00-NETFLIXRIGEL01EU-A0104-V0100-PE.pkg?product=0085&downloadId=be00b7cc&q=2058b9eb8ab5f2492012c6c5b5a73320d1bde7f004d5cb6734fa2ebf322b971e&serverIpAddr=87.248.207.254&downloadType=fm HTTP/1.1
Host: b0.ww.np.dl.playstation.net
Range: bytes=6126400-12252799
I don't understand why they do that. Obviously there is some sort of bug in the 4.41 firmware.
Update 4th July 2013:
Problem still exists in 4.46 firmware. I had major trouble updating, since my PS3 didn't get 100% of the firmware. The error message reads: "An error occurred during the download operation. A connection to the server cannot be established (80710723)".
![]()
Linux 3.9 SCSI working with Hyper-V
Thursday, May 23. 2013
Mac OS X encrypted Timemachine USB-drive
Wednesday, May 22. 2013
I got a new iMac and wanted to use an USB-drive as Time Machine backup destination for it. When it comes to easily movable backup-drives, my policy is to encrypt them. If a drive is lost/stolen/misplaced, other people don't get to access my data.
When OS X sees an empty USB-drive, and there is no Time Machin already set up, it asks if you'd like to use the newly found drive as Time Machine backup destination, which is nice and user friendly. During Time Machine setup, there is a checkbox "Encrypt drive". I checked it, but whatwhatwhat?! It refused to work. Error message:
![]()
There was an error preparing the Time Machine backup disk "TimeMachine" and an additional explanation: The given file system is not supported on Core Storage.
Well... that's strange. I have no idea what a Core Storage is, or why an Apple formatted HFS+ partition would not be a valid (encrypted) backup destination.
Here is what I did. My drive was already formatted when I got it:
$ diskutil list disk3
/dev/disk3
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *1.0 TB disk3
1: EFI 209.7 MB disk3s1
2: Microsoft Basic Data WD Backup 1000.0 GB disk3s2
There is a 1 TiB Western Digital drive with a NTFS-partition on it. So I had to delete the partition and create a better suitable one:
$ diskutil partitionDisk disk3 1 GPT HFS+ TimeMachine 1T
Started partitioning on disk3
Unmounting disk
Creating the partition map
Waiting for the disks to reappear
Formatting disk3s2 as Mac OS Extended with name TimeMachine
Initialized /dev/rdisk3s2 as a 931 GB HFS Plus volume
Mounting disk
Finished partitioning on disk3
/dev/disk3
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *1.0 TB disk3
1: EFI 209.7 MB disk3s1
2: Apple_HFS TimeMachine 999.9 GB disk3s2
This is the partition setup that refuses to work.
After couple of hours of Googling I found the solution:
$ diskutil enableJournal disk3s2
Journaling has been enabled for volume TimeMachine on disk3s2
I seem to have misplaced the links already. Sorry. Anyway, the problem was that I didn't enable journaling on the partition. I can understand why that is a requirement for Time Machine. Having a journaled partition adds robustness to write operations. The real questions are:
- Why creating a HFS+ partition does not enable journaling automatically?
- On Linux creating EXT2 or EXT3 partition does not enable journaling automatically
- On Linux creating EXT4 journaling is enabled by default
- Why doesn't Time Machine state the reason?
- Saying that Core Storage is not supported is a bit vague!
Mac OS X terminal UTF-8 over SSH
Tuesday, May 21. 2013
Something weird happens in OS X Terminal locale settings. Whenever I open an SSH-connection to one of my Linux-boxes, they refuse to properly set up an UTF-8 locale.
The session goes something like this. Checking locale settings on OS X terminal:
$ locale
LANG=
LC_COLLATE="C"
LC_CTYPE="UTF-8"
LC_MESSAGES="C"
LC_MONETARY="C"
LC_NUMERIC="C"
LC_TIME="C"
LC_ALL=
Open SSH-connection and check locale settings on Linux end:
~> locale
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: Cannot set LC_ALL to default locale: No such file or directory
LANG=en_US.UTF-8
LC_CTYPE=UTF-8
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
Aow come on! Something went wrong.
The fix on the OS X end is not to set the environment variables. In the Terminal settings, there is:
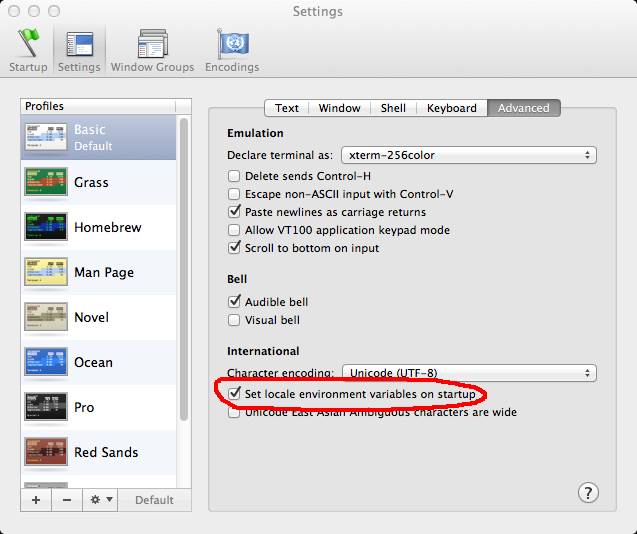
The setting Set locale environment variables on startup needs to be UNset. It is checked out-of-the-box. Then it yields:
$ locale
LANG=
LC_COLLATE="C"
LC_CTYPE="C"
LC_MESSAGES="C"
LC_MONETARY="C"
LC_NUMERIC="C"
LC_TIME="C"
LC_ALL=
The LC_CTYPE is not set. Over SSH-connection to Linux, it yields:
~> locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
Now there are no error messages. The next thing to do is to try to find somebody responsible. Whose job it is to fix this.
Google doing the same thing as Skype
Friday, May 17. 2013
Upcoming: Proper Hyper-V guest support for Linux
Thursday, May 16. 2013
Dojo 1.8 / 1.9 on Zend Framework 1
Wednesday, May 15. 2013
Serendipity commenting with proxy
Tuesday, May 14. 2013
PDF creator MSCOMCTL.OCX fail
Tuesday, May 7. 2013
Limiting Time Machine backup size on NAS
Monday, May 6. 2013
Earlier I wrote about getting a Linux-based NAS-box to host Apple Time Machine backups.
I was reviewing my settings on the Mac and realized the text in the Time Machine: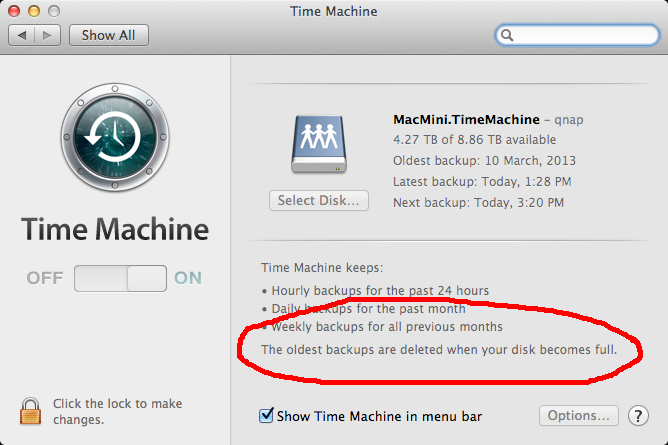
Well... I have lots of disk space there. Not all of it is can be taken by my Mac's backups, so ... Something needed to be done.
I mounted the AFP-share and confirmed the max size of my sparsebundle:
hdiutil imageinfo Mac\ mini.sparsebundle/
It said (unsurprisingly):
Size Information:
Total Bytes: 8855484092416
That is 8+ TiB!! Oh my! There is no way that I can afford to have that much of Apple backups. Luckily there is a way to reduce the size:
hdiutil resize -size 500g -shrinkonly Mac\ mini.sparsebundle/
Now checking the size will yield something reasonable (500 GiB):
Size Information:
Total Bytes: 537214885888
That is something, that I can easily accept.
The information came from:
- http://untoro.wordpress.com/2011/06/07/how-to-limit-space-used-by-time-machine/
- http://nikhilhaas.com/blog/limit-size-of-time-machine-backup-on-wd-my-book-live/
Also I did this to limit the size. I have no idea if it actually does anything.
defaults write /Library/Preferences/com.apple.TimeMachine MaxSize 405600
Perhaps somebody can comment this.
Acronis True Image 2013 restore failing: NTFS as raw partition
Sunday, May 5. 2013
This is a follow up for my earlier post about Acronis experiences.
So, I decided to get a new motherboard/CPU/memory -triplet. I did what I usually do, except this time I was using Acronis and this time my computer had fake RAID-1 drive from ICH10R-chip. At the time I didn't think none of this matters, I just went forward with the hardware upgrade. New components booted the first time without any real issues. I re-configured the existing drives with the RAID-1 and booted to the Windows for the first time.
My boot drive is SSD, and I have large RAID-1 array for files. I got into Windows, logged in, plenty of grievance as expected. Lots of new devices found, RAID-missing, etc. no real surprises there. I re-partitioned the RAID-1 drive and started Acronis. The idea was to do a restore of my previous data and go forward with configuring the new parts. To my surprise, Acronis announced that it cannot do a restore into my D:-drive. Initially I didn't think much of it, since Acronis said, that it needs to reboot and restore will continue. Sounds good to me.
After the reboot I was in a Linux-environment with Acronis pretty much automatically doing everything. The only choice was to abort the restore and two checkboxes. Shutdown after restore or reboot after restore. There was 800 GiB of data and estimate was 7 hours. I checked the shutdown and left.
Next day I came back to see what happened. PC was shut down. Most likely the restore succeeded and shut down after completion. I booted into Windows to see that there was no D:-drive. The partition was gone too. WTF?!
During following days I repeated the process 3 more times with varying parameters from restore. No results. Windows saw my RAID-1 mirror as a raw partition each time. No files, no resonable results. It would be fair to say that I was pissed. What a piece of crap backup software! The value of backup is in the possibility of doing a restore of it. This "fine" product didn't deliver. Unbelievable!
Next I got a Fedora Linux 18 Live DVD to see how my drives were visible there. Then the idea hit me! In out-of-the-box Linux, a fake RAID ICH10R mirror is seen as two physical drives. Not as single RAID-1 volume. Sure, the volume can be configured into Linux too, but out-of-the-box it didn't do that. What are the chances Acronis' restore Linux does the same? I'd bet serious money on that.
So, apparently in ICH10R there is offset in the drive if it is configured as RAID-drive. Many real RAID-controllers don't do that. A RAID-mirror is two physical drives mirrored and you can take either one of those and it will work as JBOD.
Acronis' knowledge base recommended doing the restore in Windows (sorry, I lost the articlea already). So, The next thing I did was to purchase a True Image 2013 Plus Pack. I got Windows 7 AIK, installed it, installed the newly purchased Plus Pack and started to create a Windows restore image. The image maker did something for a while and then "Error occurred while creating the image". Nothing more. No details. No log-file. No nothing. Completely useless piece of crap!
So, I spent around 9 days while trying to get my data back. I had purchased even more crappy software from Acronis, and had no joy from my new parts.
I went back to square one. Why doesn't the partition restore start in Windows? Why does it say, that it needs to reboot and go to Linux? WTF?! I investigated more and realized that whenever I create a D:-drive, it gets locked by operating system right after it get's ready. That must be the reason for Acronis to want a reboot.
SOLUTION:
I created the RAID-1 array, quick-formatted it as NTFS, but assigned it as H:-drive. Now Windows didn't want to lock that. Apparently my yet-to-be-restored data had something the OS wanted. The data wasn't available, but OS happily locked the drive while hoping for the data to appear. I did a restore to the H:-drive. This time it took 10 hours. Apparently Linux restore is much faster (or they both took 10 hours, I don't know).
After the restore completed, I just re-arranged the drive letters so that my succesfully restored RAID-1 mirror got the D:-letter again. A reboot and everything was fine! Uuu-jeah!  Oh happy, oh joy!
Oh happy, oh joy!
PS. If anyone is interested. There are 3D Mark 20111 results from my box publicly available.

