Led Lenser K2 vs. MagLite Solitaire LED
Saturday, February 8. 2014
A while ago I a friend send a link to Jamie and Adam Tested -YouTube channel. I'm a fan of Mythbusters, so he knew that I'd love their stuff. One of the videos they have there is Inside Adam Savage's Cave: Hacking a Flashlight for Adam's EDC. So, I felt that I should blog about flashlights too.
Last year my old and trustworthy MagLite Solitaire broke down after serving me well for 18 years and I had to get a replacement. My old Solitare became un-fixable due to some sort of stress in the inside plastic parts. They broke down to a number of new pieces that didn't fit anymore. Apparently my key chain with number of keys in it cause stress to a flashlight's guts.
In the above video Adam is doing a hack to his JETBeam. Me as a Leatherman man I went for a Led Lenser (apprently they are owned by same company). Model K2 to be specific. However it turned to be a mistake. The LED is bright, it really is, and the flashlight is really tiny, but its aluminum body is not built to be hung in a key chain and stuffed into a pocket over and over again. It broke after 8 months of "usage". Actually I didn't use the lamp that much, but ... It broke. Aow come on! My previous lamp lasted for 18 years!
Here is a pic of the broken Led Lenser K2 (the short one) next to my new flashlight:

Thankfully my favorite flashlight company is back! I don't know what MagLite did for 15 years or so, but they certainly lost the market leader position by not releasing any new products for a very, very long time. So... after failing with Led Lenser I went back to MagLite. Their new LED-products are really good and I got one of their new releases a Solitaire LED. I'm hoping it lasts a minimum of 18 years! 
Advanced mod_rewrite: FastCGI Ruby on Rails /w HTTPS
Friday, February 7. 2014
Huawei B593: Forcing 4G LTE mode
Thursday, February 6. 2014
First I'd like to apologize. At least twice I've said that it is impossible to force B593 to stay out of 3G-mode and force it to stay on 4G LTE. That is not true. It is an incorrect statement by me and I'm sorry that I didn't investigate the facts before making such statements.
Here is a (slightly photoshopped) screenshot of my own device:
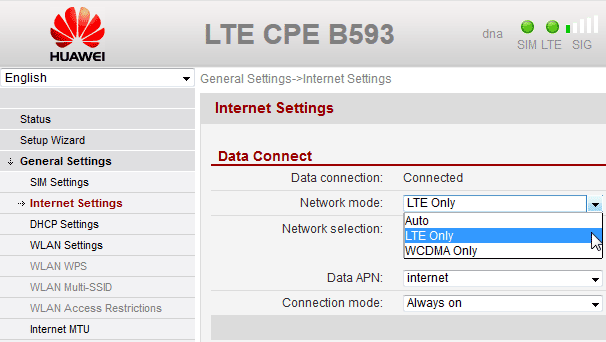
There actually is such an option in General Settings --> Internet Settings --> Network mode. And you can select LTE Only and it will work as expected.
For device hackers, the /var/curcfg.xml will have the setting:
<?xml version="1.0" ?>
<InternetGatewayDeviceConfig>
<InternetGatewayDevice>
<WANDevice NumberOfInstances="3">
<WANDeviceInstance InstanceID="2">
<WANConnectionDevice NumberOfInstances="1">
<WANConnectionDeviceInstance InstanceID="1">
<WANIPConnection NumberOfInstances="2">
<WANIPConnectionInstance InstanceID="1"
X_NetworkPriority="LTE Only"
Valid options for X_NetworkPriority "AUTO", "WCDMA Only" and "LTE Only".
After changing the setting my connection has been more stable than ever (on Danish 3's firmware). There has been occasions where my connection has dropped to 2.5G, see the blog post about it, but after fixing the LTE-only -mode things changed to most robust ever.
SplashID wasted my entire password database
Wednesday, February 5. 2014
I've been using SplashID as my password solution. See my earlier post about that. Today I tried to log in into the application to retrieve a password, but it turned out my user account was changed into null. Well... that's not reassuring. 
After the initial shock I filed a support ticket to them, but I'm not expecting any miracles. The database has been lost in my bookkeeping. The next thing I did was checked my trustworthy(?) Acronis True Image backups. I had them running on daily rotation and this turned out to be the first time I actually needed it for a real situation.
They hid the "Restore files and directories" -option well. My laptop is configured to run backups for the entire disk, so the default recover-option is to restore the entire disk. In this case that seems a bit overkill. But in the gear-icon, there actually is such an option. After discovering the option (it took me a while reading the helps), the recover was user friendly and intuitive enough. I chose to restore yesterday's backup to the original location. The recover went fine, but SplashID database was flawed on that point. I simply restored two days old backup and that seemed to be an intact one.
Luckily I don't recall any additions or changes to my passwords during the last two days. It looks like I walked away with this incident without harm.
Update 7th Feb 2014:
I got a reply to my support ticket. What SplashData is saying, that the password database is lost due to a bug (actually they didn't use that word, but they cannot fool me). The bug has been fixed in later version of SplashID. Luckily I had a backup to restore from. IMHO the software should have better notification about new versions.
Managing PostgreSQL 8.x permissions to limit application user's access
Wednesday, February 5. 2014
I was working with a legacy project with PostgreSQL 8 installation. A typical software developer simply does not care about DBA enough to think more than once about the permissions setup. The thinking is that for the purpose of writing lines of working code which executes really nice SQL-queries a user with lots of power in its sleeves is a good thing. This is something I bump into a lot. It would be a nice eye-opener if every coder would had to investigate a server which has been cracked into once or twice in the early programming career. I'm sure that would improve the quality of code and improve security thinking.
Anyway, the logic for ignoring security is ok for a development box, given the scenario that it is pretty much inaccessible outside the development team. When going to production things always get more complicated. I have witnessed production boxes which are running applications that have been configured to access DB with Admin-permissions. That happens in an environment where any decent programmer/DBA can spot out a number of other ignored things. Thinking about security is both far above the pay-grade and the skill envelope your regular coder possesses.
In an attempt to do things the-right-way(tm), it is a really good idea to create a specific user for accessing the DB. Even better idea is to limit the permissions so, that application user cannot run the classic "; DROP TABLE users; -- " because lacking the permission to drop tables. We still remember Exploits of a Mom, right?
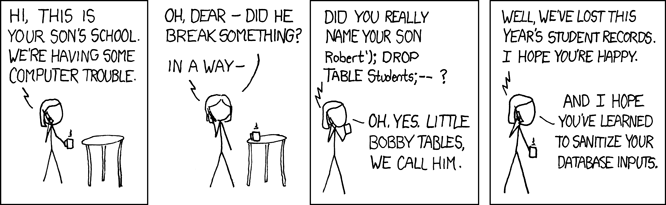
Image courtesy of xkcd.com.
Back to reality... I was on a production PostgreSQL and evaluated the situation. Database has owner of postgres, schema public had owner of postgres, but all the tables, sequences and views where owned by the application user. So any exploit would allow the application user to drop all tables. Not cool, huh!
To solve this three things are needed: first, owner of the entire schema must be postgres. Second, the application user needs only to have enough permission for CRUD-operations, nothing more. And third, the schema must not allow users to create new items on it. As default everybody can create new tables and sequences, but if somebody really pops your box and can run anything on your DB, creating new items (besides temporary tables) is not a good thing.
On a PostgreSQL 8 something of a trickery is needed. Version 9.0 introduced us the "GRANT ... ALL TABLES IN SCHEMA", but I didn't have that at my disposal. To get around the entire thing I created two SQL-queries which were crafted to output SQL-queries. I could simply copy/paste the output and run it in pgAdmin III query-window. Nice!
The first query to gather all tables and sequences and change the owner to postgres:
SELECT 'ALTER TABLE ' || table_schema || '.' || table_name ||' OWNER TO postgres;'
FROM information_schema.tables
WHERE
table_type = 'BASE TABLE' and
table_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'ALTER SEQUENCE ' || sequence_schema || '.' || sequence_name ||' OWNER TO postgres;'
FROM information_schema.sequences
WHERE
sequence_schema NOT IN ('pg_catalog', 'information_schema')
It will output something like this:
ALTER TABLE public.phones OWNER TO postgres;
ALTER SEQUENCE public.user_id_seq OWNER TO postgres;
I ran those, and owner was changed.
NOTE: that effectively locked the application user out of DB completely.
So it was time to restore access. This is the query to gather information about all tables, views, sequences and functions:
SELECT 'GRANT ALL ON ' || table_schema || '.' || table_name ||' TO my_group;'
FROM information_schema.tables
WHERE
table_type = 'BASE TABLE' and
table_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'GRANT ALL ON ' || table_schema || '.' || table_name ||' TO my_group;'
FROM information_schema.views
WHERE
table_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'GRANT ALL ON SEQUENCE ' || sequence_schema || '.' || sequence_name ||' TO my_group;'
FROM information_schema.sequences
WHERE
sequence_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'GRANT ALL ON FUNCTION ' || nspname || '.' || proname || '(' || pg_get_function_arguments(p.oid) || ') TO my_group;'
FROM pg_catalog.pg_proc p
INNER JOIN pg_catalog.pg_namespace n ON pronamespace = n.oid
WHERE
nspname = 'public'
It will output something like this:
GRANT ALL ON public.phones TO my_user;
GRANT ALL ON SEQUENCE public.user_id_seq TO my_user;
NOTE: you need to find/replace my_user to something that fits your needs.
Now the application was again running smoothly, but with reduced permission in effect. The problem with all this is that TRUNCATE-clause (or DELETE FROM -tablename-) are still working. To get the maximum out of enhanced security, some classification of data would be needed. But the client wasn't ready to do that (yet).
The third thing is to limit schema permissions so that only usage is allowed for the general public:
REVOKE ALL ON SCHEMA public FROM public;
GRANT USAGE ON SCHEMA public TO public;
Now only postgres can create new things there.
All there is to do at this point is to test the appliation. There should be errors for DB-access if something went wrong.
Tar: resolve failed weirness
Tuesday, February 4. 2014
Installing own CA root certificate into openSUSE
Monday, February 3. 2014
Change iCloud account in iOS 7 - Is it possible?
Sunday, February 2. 2014
The way Apple chose to implement changing iCloud-account is far from making any sense at all. The phrase "Delete Account" puts every users' imagination into high gear. By clicking this red button what could possibly go wrong! Does it implode your entire iCloud-account with all the data in it so that everything is gone permanently and forever? Or does it simply disconnect that particular iOS device from the Apple's cloud?
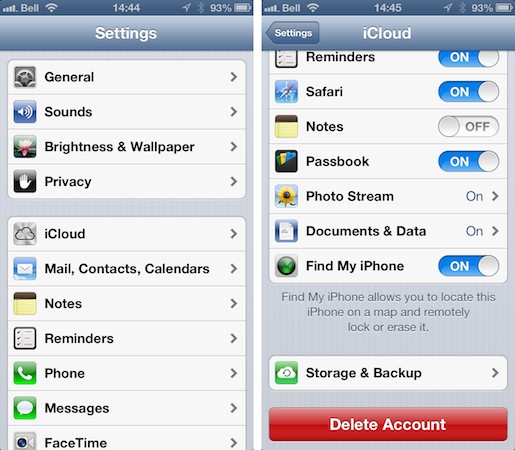 Image courtesy of http://assets.ilounge.com/images/articles_jdh/ask-20121114-1.jpg
Image courtesy of http://assets.ilounge.com/images/articles_jdh/ask-20121114-1.jpg
Apparently it is the latter one. The user interface is really poorly designed, no matter what. I think the idea was to scare users from testing what happens if they click it.
The discussion-thread in Apple's forums (HT4895 How do I change my iCloud account to my new apple ID?) is one of the sources for confirmation, that it does not wipe your account. It just detaches that particular device from your cloud-account.
To actually change the device to use a new iCloud account is much more tricky, as the article points out. And on top of that, iMessage, Facetime and AppStore still need to re-connect separately. Luckily that's not a big deal at that point.
However, if you combine changing the account with taking a new iPad into use, then you see a flood of e-mail from Apple. The e-mails come from different systems at Apple, but it certainly made me laugh a for a while. There are e-mails from Find My iPhone (my device was iPad), then there are security notifications about Apple ID being used in a new device and when all is set up, there is the welcome to a new device -mail. It would sound like a better idea to switch the account into some sort of changing-devices -mode, but they don't have that yet.
The good thing is that it is possible to change accounts. The bad thing is that they implemented the bare minimum of it.

