Databricks CentOS 8 stream containers
Monday, February 7. 2022
Last November I created CentOS 8 -based Databricks containers.
At the time of tinkering with them, I failed to realize my base was off. I simply used the CentOS 8.4 image available at Docker Hub. On later inspection that was a failure. Even for 8.4, the image was old and was going to be EOLd soon after. Now that 31st Dec -21 had passed I couldn't get any security patches into my system. To put it midly: that's bad!
What I was supposed to be using, was the CentOS 8 stream image from quay.io. Initially my reaction was: "What's a quay.io? Why would I want to use that?"

Thanks Merriam-Webster for that, but it doesn't help.
On a closer look, it looks like all RedHat container -stuff is not at docker.io, they're in quay.io.
Simple thing: update the base image, rebuild all Databricks-images and done, right? Yup. Nope. The images built from steam didn't work anymore. Uff! They failed working that bad, not even Apache Spark driver was available. No querying driver logs for errors. A major fail, that!
Well. Seeing why driver won't work should be easy, just SSH into the driver an take a peek, right? The operation is documented by Microsoft at SSH to the cluster driver node. Well, no! According to me and couple of people asking questions like How to login SSH on Azure Databricks cluster, it is NOT possible to SSH into Azure Databricks node.
Looking at Azure Databricks architecture overview gave no clues on how to see inside of a node. I started to think nobody had ever done it. Also enabling diagnostic logging required the premium (high-prized) edition of Databricks, which wasn't available to me.
At this point I was in a full whatta-hell-is-going-on!? -mode.
Digging into documentation, I found out, it was possible to run a Cluster node initialization scripts, then I knew what to do next. As I knew it was possible to make requests into the Internet from a job running in a node, I could write an intialization script which during execution would dig me a SSH-tunnel from the node being initialized into something I would fully control. Obiviously I chose one of my own servers and from that SSH-tunneled back into the node's SSH-server. Double SSH, yes, but then I was able to get an interactive session into the well-protected node. An interactive session is what all bad people would want into any of the machines they'll crack into. Tunneling-credit to other people: quite a lot of my implementation details came from How does reverse SSH tunneling work?
To implement my plan, I crafted following cluster initialization script:
LOG_FILE="/dbfs/cluster-logs/$DB_CLUSTER_ID-init-$(date +"%F-%H:%M").log"
exec >> "$LOG_FILE"
echo "$(date +"%F %H:%M:%S") Setup SSH-tunnel"
mkdir -p /root/.ssh
cat > /root/.ssh/authorized_keys <<EOT
ecdsa-sha2-nistp521 AAAAE2V0bV+TrsFVcsA==
EOT
echo "$(date +"%F %H:%M:%S") Install and setup SSH"
dnf install openssh-server openssh-clients -y
/usr/libexec/openssh/sshd-keygen ecdsa
/usr/libexec/openssh/sshd-keygen rsa
/usr/libexec/openssh/sshd-keygen ed25519
/sbin/sshd
echo "$(date +"%F %H:%M:%S") - Add p-key"
cat > /root/.ssh/nobody_id_ecdsa <<EOT
-----BEGIN OPENSSH PRIVATE KEY-----
b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAAA
1zaGEyLW5pc3RwNTIxAAAACG5pc3RwNTIxAAAAhQQA2I7t7xx9R02QO2
rsLeYmp3X6X5qyprAGiMWM7SQrA1oFr8jae+Cqx7Fvi3xPKL/SoW1+l6
Zzc2hkQHZtNC5ocWNvZGVzaG9wLmZpAQIDBA==
-----END OPENSSH PRIVATE KEY-----
EOT
chmod go= /root/.ssh/nobody_id_ecdsa
echo "$(date +"%F %H:%M:%S") - SSH dir content:"
echo "$(date +"%F %H:%M:%S") Open SSH-tunnel"
ssh -f -N -T \
-R22222:localhost:22 \
-i /root/.ssh/nobody_id_ecdsa \
-o StrictHostKeyChecking=no \
nobody@my.own.box.example.com -p 443
Note: Above ECDSA-keys have been heavily shortened making them invalid. Don't copy passwords or keys from public Internet, generate your own secrets. Always! And if you're wondering, the original keys have been removed.
Note 2: My init-script writes log into DBFS, see exec >> "$LOG_FILE" about that.
My plan succeeded. I got in, did the snooping around and then it took couple minutes when Azure/Databrics -plumbing realized driver was dead, killed the node and retried the startup-sequence. Couple minutes was plenty of time to eyeball /databricks/spark/logs/ and /databricks/driver/logs/ and deduce what was going on and what was failing.
Looking at simplified Databricks (Apache Spark) architecture diagram:
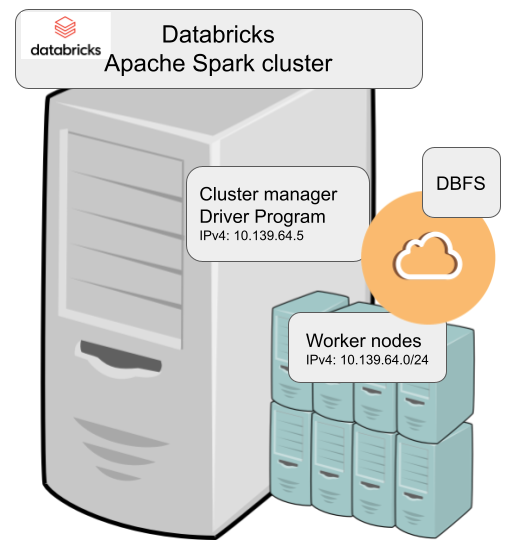
Spark driver failed to start because it couldn't connect into cluster manager. Subsequently, cluster manager failed to start as ps-command wasn't available. It was in good old CentOS, but in base stream it was removed. As I got progress, also ip-command was needed. I added both and got the desired result: a working CentOS 8 stream Spark-cluster.
Notice how I'm specifying HTTPS-port (TCP/443) in the outgoing SSH-command (see: -p 443). In my attempts to get a session into the node, I deduced following:
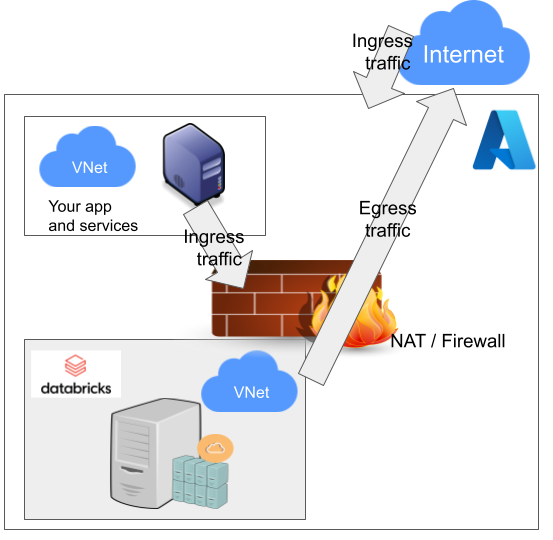
As Databricks runs in it's own sandbox, also outgoing traffic is heavily firewalled. Any attempts to access SSH (TCP/22) are blocked. Both HTTP and HTTPS are known to work as exit ports, so I spoofed my SSHd there.
There are a number of different containers. To clarify which one to choose, I drew this diagram:
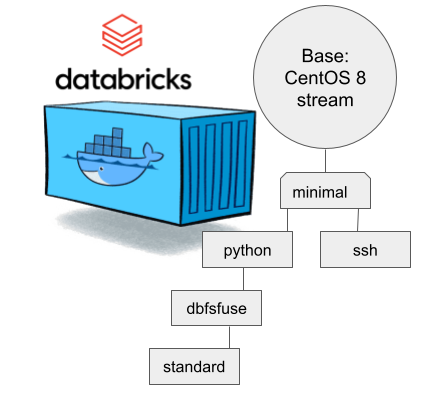
In my sparking, I'll need both Python and DBFS, so my choice is dbfsfuse. Most users would be happy with standard, but it only adds SSHd which is known not to work. ssh has the same exact problem. The reason for them to exist, is because in AWS SSHd does work. Among the changes from good old CentOS into stream is lacking FUSE. Old one had FUSE even in minimal, but not anymore. You can access DBFS only with dbfsfuse or standard from now on.
If you want to take my CentOS 8 brick-containers for a spin, they are still here: https://hub.docker.com/repository/docker/kingjatu/databricks, now they are maintained and get security patches too!

