Apache mod_rewrite: Blocking unwated requests
Thursday, February 11. 2016
How to stop Windows 10 upgrade bullying
Sunday, February 7. 2016
The problem
Ok. Microsoft has amped up their "upgrade now" campaign to a ridiculous level.
First Microsoft Marketing chief Chris Capossela "warned" about Windows 7 being insecure. Warned in quotes because my initial reaction was: "Oh really!? Is it really possible, that a Windows can not be secure operating system." 
While this machine is eligble for a free Win 10 upg, I just don't want to do that yet. I will upgrade eventually, but at the time I choose, not some ignorant corporate chose for me. So, Mr. Capossela explained that users who choose Windows 7 do so “at your own risk, at your own peril” and he revealed Microsoft has concerns about its future software and hardware compatibility, security and more.
Now the latest development is, that Windows 10 upg is a recommended update as they're now aggressively pushing Windows 10 upgrades. Meaning, that have to actively dodge it every time I'll upgrade this box of mine.
Further details about KB2952664 a Compatibility update for upgrading Windows 7 patch @ Softpedia article.
The information
The annoyance looks like this:
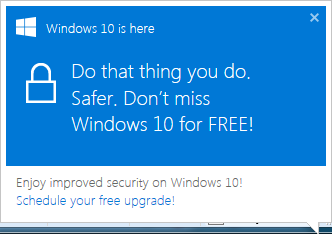
In the process list of the victim machine, there is a GWXUX.exe producing that. Actually there are other GWX-prefixed processes capturing your machine, but for the sake of this blog post I'm ignoring that crap.
Ages ago Microsoft release KB article ID 3080351, How to manage Windows 10 notification and upgrade options. It contains all kinds of useless information about modifying registry entries like HKLM\Software\Microsoft\Windows\CurrentVersion\WindowsUpdate\OSUpgrade value ReservationsAllowed.
What the article doesn't mention is, that it also hijacks your disk space at C:\$Windows.~BT and C:\$Windows.~WS. I got a tip from an article and found 5 GiB of crap already loaded to my computer. I ran cmd.exe (with administrator credentials) to free up my SSD-space:
C:\Windows\system32>attrib -h "C:\$Windows.~BT"
C:\Windows\system32>attrib -h "C:\$Windows.~WS"
C:\Windows\system32>cd "C:\$Windows.~BT"
C:\$Windows.~BT>takeown /f . /R /D Y
C:\$Windows.~BT>icacls . /grant Administrators:(OI)(CI)F /T
C:\Windows\system32>cd "C:\$Windows.~WS"
C:\$Windows.~WS>takeown /f . /R /D Y
C:\$Windows.~WS>icacls . /grant Administrators:(OI)(CI)F /T
After doing all that, reading all the information, changing all the registry values and removing pre-loaded waste... It didn't work. What the article doesn't mention, that one of the GWX-processes runs in background and snoops those registry values and changes them back! Yes. You read it right. The fuckers go to your computer and make better choices for your registery. Their flawed reasoning is, that you obviously have to be some sort of moron not to go for their ultimate product right now, or preferably yesterday. And as you (the moron), the owner of your computer running a lesser "insecure" OS, need Microsoft's help to make better decisions.
OH, COME ON! Not cool. 
I'm NOT upgrading to Windows 10 yet, because I (as in me) am in control here. Not Microsoft (as in them).
The solution
After spending countless hours and experiencing a number of setbacks, when the timers kicked on I stumbled into somebody having exactly the same problem as I do. He also had a solution for it. Here is the article Using GWX Control Panel to Permanently Remove the 'Get Windows 10' Icon.
GWX Control Panel looks like this:
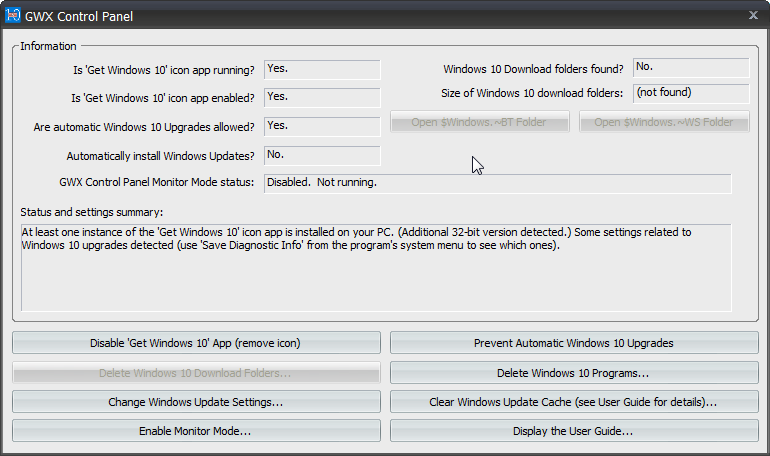
With this application, no need to game of Whack-a-Mole anymore. The not wanted and not needed crap will just fly out with a click of a button. Example of getting rid of pre-loaded Windows 10 installation files:
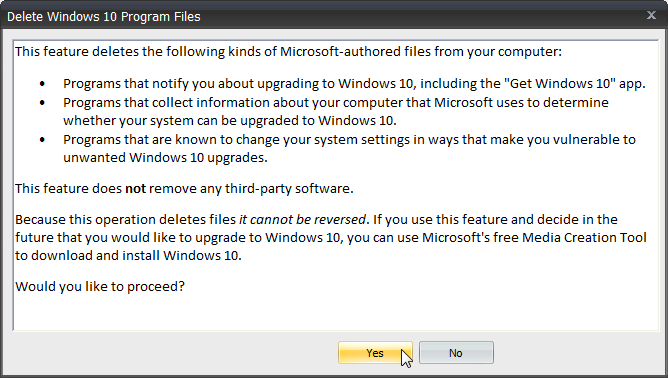
Ultimately the cleaned up machine will report:
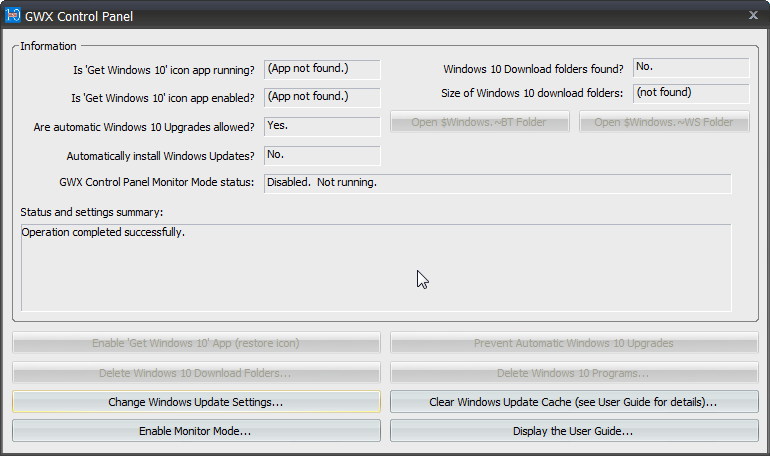
List of goodies include:
- Is 'Get Windows 10' icon app running? App not found
- Is 'Get Windows 10' icon app enabled? App not found
- Windows 10 Download folders found? No
Oh yes!
The application has an option to stay as a background process to keep monitoring, that evil Microsoft processes stay gone. I didn't test that, as just kicking all the crap out of my computer did the trick. Now I was back on the drivers' seat. Now I can decide when to do the upgrade.
Temperature measurement limits of La Crosse WS2357
Thursday, February 4. 2016
Guess what happens right before hell freezes over? Your weather station indicates dew point of 136 °C. Kinda funny.
Good thing that Weather Underground allows you to edit by removing data points. So, there are couple gaps in my graphs now:
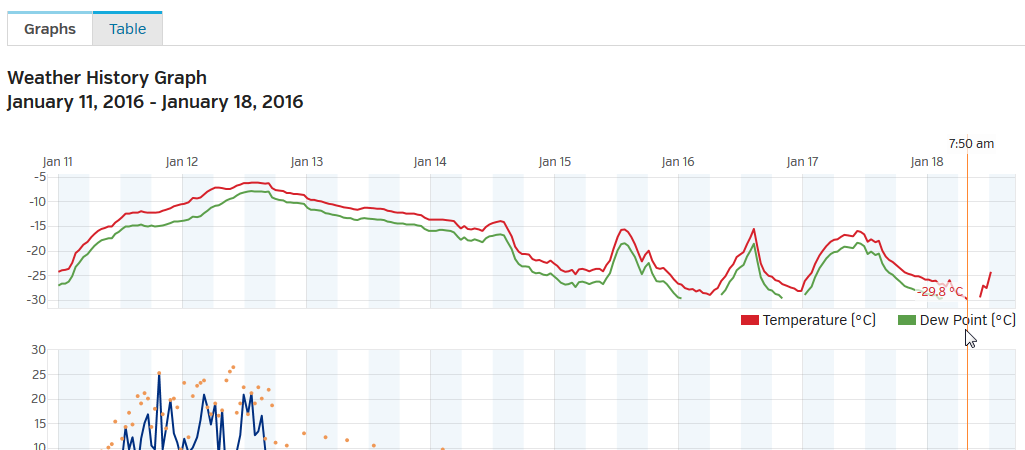
The reson for this weird behaviour can be found from the spec:

OMG! The lower bound of outside temperature measurement is -29.9 °C. In Finland that can be reached occasionally.
Fortunately I'm using open source software, Open2300. With very little debugging I found the code:
double temperature_outdoor(WEATHERSTATION ws2300, int temperature_conv)
...
return ((((data[1] >> 4) * 10 + (data[1] & 0xF) +
(data[0] >> 4) / 10.0 + (data[0] & 0xF) / 100.0) - 30.0));
double dewpoint(WEATHERSTATION ws2300, int temperature_conv)
...
return ((((data[1] >> 4) * 10 + (data[1] & 0xF) +
(data[0] >> 4) / 10.0 + (data[0] & 0xF) / 100.0) - 30.0));
There is a formula to convert raw data read from RS-232 -line to celsius.
My patch to fix this is:
--- svn/rw2300.h 2015-01-19 23:42:17.728311172 +0200
+++ JaTu/rw2300.h 2016-02-04 23:58:45.675123710 +0200
@@ -24,6 +24,7 @@
#include <math.h>
#include <sys/types.h>
#include <sys/stat.h>
+#include <float.h>
#define MAXRETRIES 50
#define MAXWINDRETRIES 20
@@ -56,6 +57,8 @@
#define MAX_APRS_HOSTS 6
+#define TEMPERATURE_OVERFLOW FLT_MIN
+
typedef struct {
char name[50];
int port;
--- svn/wu2300.c 2015-01-19 23:42:16.619287028 +0200
+++ JaTu/wu2300.c 2016-01-18 10:13:21.252092414 +0200
@@ -53,15 +53,18 @@
/* READ TEMPERATURE OUTDOOR - deg F for Weather Underground */
-
- sprintf(tempstring, "&tempf=%.2f", temperature_outdoor(ws2300, FAHRENHEIT) );
- strcat(urlline, tempstring);
-
+ tempfloat = temperature_outdoor(ws2300, FAHRENHEIT);
+ if (tempfloat > TEMPERATURE_OVERFLOW) {
+ sprintf(tempstring, "&tempf=%.2f", tempfloat );
+ strcat(urlline, tempstring);
+ }
/* READ DEWPOINT - deg F for Weather Underground*/
-
- sprintf(tempstring, "&dewptf=%.2f", dewpoint(ws2300, FAHRENHEIT) );
- strcat(urlline, tempstring);
+ tempfloat = dewpoint(ws2300, FAHRENHEIT);
+ if (tempfloat > TEMPERATURE_OVERFLOW) {
+ sprintf(tempstring, "&dewptf=%.2f", tempfloat );
+ strcat(urlline, tempstring);
+ }
/* READ RELATIVE HUMIDITY OUTDOOR */
--- svn/fetch2300.c 2015-01-19 23:42:17.728311172 +0200
+++ JaTu/fetch2300.c 2016-01-18 10:09:46.762108076 +0200
@@ -35,7 +35,7 @@
char tendency[15];
char forecast[15];
struct config_type config;
- double tempfloat_min, tempfloat_max;
+ double tempfloat, tempfloat_min, tempfloat_max;
int tempint, tempint_min, tempint_max;
struct timestamp time_min, time_max;
time_t basictime;
@@ -63,7 +63,11 @@
/* READ TEMPERATURE OUTDOOR */
- sprintf(tempstring, "To %.1f\n", temperature_outdoor(ws2300, config.temperature_conv) );
+ tempfloat = temperature_outdoor(ws2300, config.temperature_conv);
+ if (tempfloat == TEMPERATURE_OVERFLOW)
+ sprintf(tempstring, "To OVR\n");
+ else
+ sprintf(tempstring, "To %.1f\n", tempfloat);
strcat(logline, tempstring);
temperature_outdoor_minmax(ws2300, config.temperature_conv, &tempfloat_min,
@@ -79,8 +83,11 @@
/* READ DEWPOINT */
-
- sprintf(tempstring, "DP %.1f\n", dewpoint(ws2300, config.temperature_conv) );
+ tempfloat = dewpoint(ws2300, config.temperature_conv);
+ if (tempfloat == TEMPERATURE_OVERFLOW)
+ sprintf(tempstring, "DP OVR\n");
+ else
+ sprintf(tempstring, "DP %.1f\n", tempfloat );
strcat(logline, tempstring);
dewpoint_minmax(ws2300, config.temperature_conv, &tempfloat_min,
There I introduce a hard-limit of TEMPERATURE_OVERFLOW and check if that has been reached. If yes, the invalid value is not sent to WUnderground.
I've contacted the author of Open2300 about this, but haven't received a response.
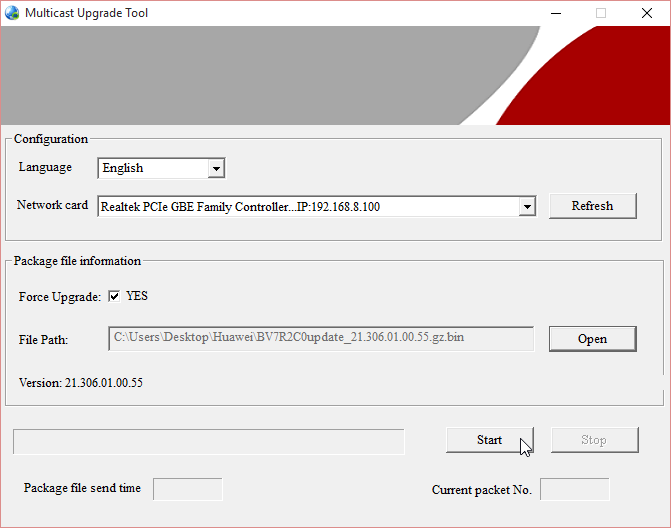
Huawei E5186 Firmware Upgrade with Multicast Upgrade Tool
Monday, January 25. 2016
Typical firmware upgrade for any entwork applicance is done via web-interface. The obvious catch in that is, that you need to authenticate, move to a suitable page and upload a file to accomplish that. In rare cases, hardware has an "upgrade mode", which allows you to inject a new firmare to the device without any proper authentication. For hacking, this opens a completely new avenue. If one could modify a firmware (and sign it), it would be possible to unlock locked devices, unlock features, or introduce new functionality.
Getting the box to the upgrade mode sounds easy:
turn power off from the device, keep WPS and Wi-Fi buttons pressed, kick on the power and at a suitable time release the Wi-Fi button. Then normal boot process is stopped and the box will wait for a firmware file to be delivered to it. In reality, it's bit tricky. Possible to do, but bit tricky.
Prerequisites
To get the upgrade rolling you'll need following things:
- Huawei E5186s-22a router
- A computer running Windows 7, 8 or 10
- Administrator permissions for changing TCP/IP settings is required
- An ethernet cable to connect the computer to the router's LAN-port
- A firmware file to upload, filename will be something like
BV7R2C0update_<version number>.gz.bin - Multicast Upgrade Tool
- This is not publicly available file
- Tool's filename is
multicast_upgrade_tool.exe, 3354624 bytes - The one I got was packaged into
multicast.rar, 1040927 bytes. - SHA-256 sum of
multicast_upgrade_tool.exeis6224fe8fb0ec628a29ade1d7d5fb2db5183bfd43486037d0cdf8c363e8ed8eca
- WinRar packing utility from http://www.win-rar.com/ installed and working on your Windows
Setup
This is what my setup looks like:

I didn't have any switches or any other network appliance there, I just hooked the other end of the cable to my laptop and one end to the router. (The Kabuto car in the bottom corner is optional )
Next thing you'll need to confirm is your firewall software (or Windows built in one). Depending on what you have it may not allow the outgoing traffic.
The definition of upgrade traffic profile is as follows:
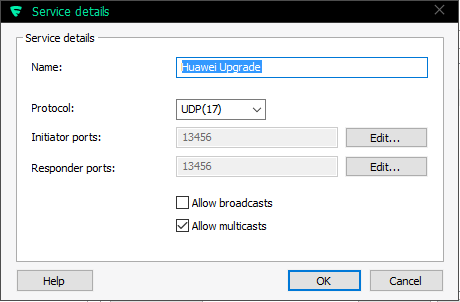
It is UDP, both initiator and responder are at port 13456. The obvious thing that you need to notice is, that traffic is multicast.
My firewall rule is:
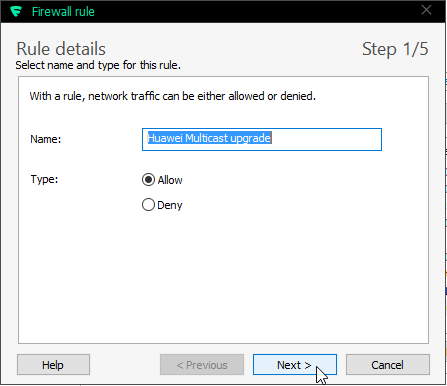
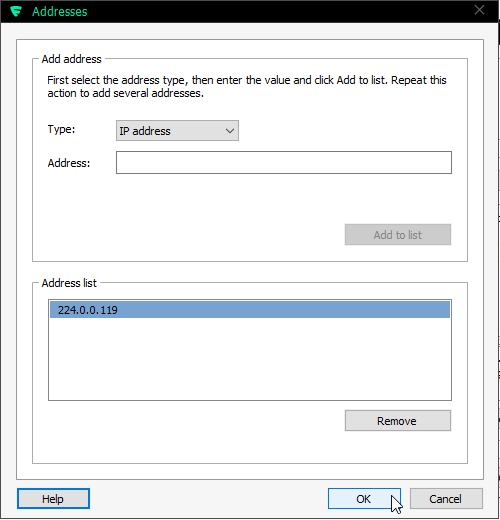
Make sure you'll allow outgoing traffic to multicast address 224.0.0.119. For any layman, that looks like just another IP-address, but it isn't one. It is in multicast address range and will be handled differently by TCP/IP-stack.
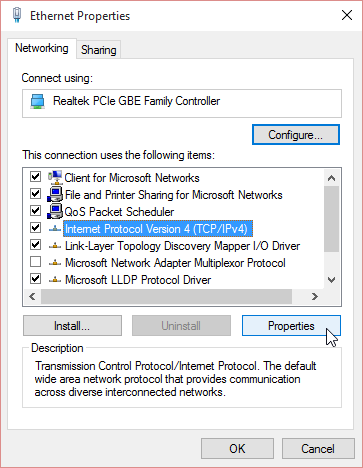
As all you TCP/IP savvy people know, multicast works no matter what your computer's IP-address is. That being said, I still recommend you change the computer's IP-address to network 192.168.8/24 which is used by the E5186. It is done from control panel (the screen shots are from Windows 10):
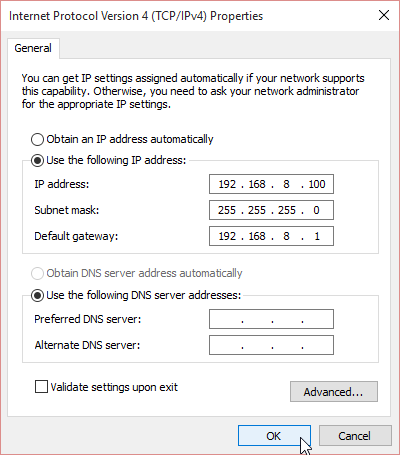
I didn't bother setting up any DNS-servers there. It will work without. The value of 192.168.8.100 is recommended by Huawei manual, so I used that.
Final setup thing is to make sure your Multicast Upgrade Tool can access WinRAR. On startup this will happen:
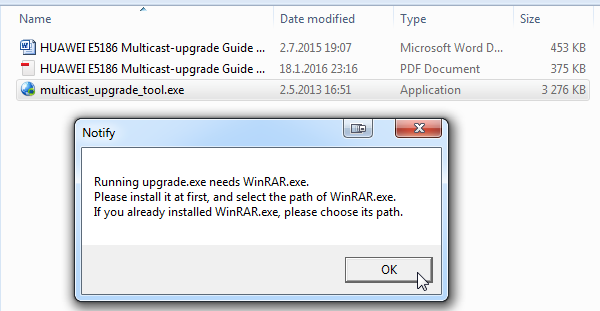
Just point the file selector to your already installed WinRAR:
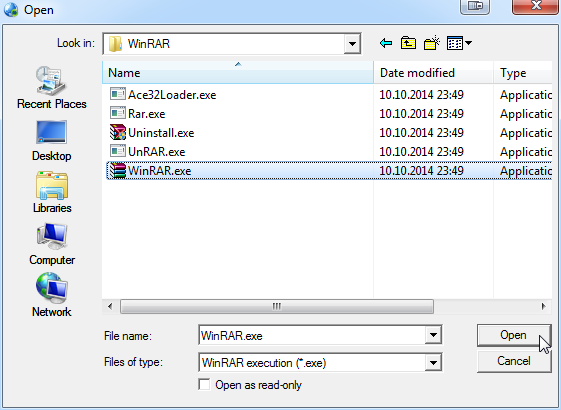
That's it. That will do for the setup.
Update
Now this is the time to start practicing the upgrade mode -switch on power up.
First the normal, non-interrupt bootup sequence. It will look like this on your LEDs:

Serial console logs indicate, that you'll have 0,850 seconds from power-on to words "not in router upgrade mode" to be logged. So, I strongly suggest, that you'll keeps WPS and Wi-Fi buttons when you flip the power switch.
Your window-of-opportunity to release the Wi-Fi -button is between 0,850 and 1,890 seconds from power-on. If you release earlier, it's same as not pressing them at all. If you'll press them longer, you'll get the phrase "not in router upgrade mode" to the log, meaning that you failed.
This is what a success will look like:

If your blue LED keeps lit, like this:
 Then everything is still ok. I cannot reproduce that every time, but I successfully updated firmwares with that status also. The idea is, that the blue LED keeps lit.
Then everything is still ok. I cannot reproduce that every time, but I successfully updated firmwares with that status also. The idea is, that the blue LED keeps lit.
In that state the router is expecting you to start sending the file:
When you're successfully sending, the LEDs will indicate it:
 The Wi-Fi LED will blink. It will go off once a while, but don't worry about it.
The Wi-Fi LED will blink. It will go off once a while, but don't worry about it.
You can monitor the number of times, the file has been sent:
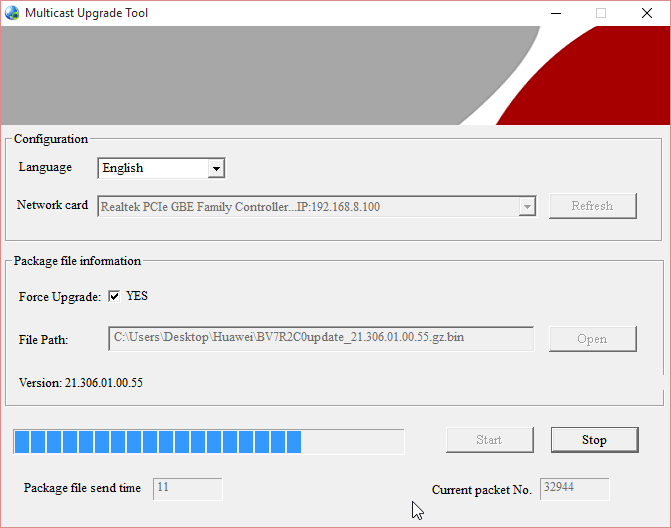
The entire upgrade can take like 10 minutes and you'll be transferring the file any number of times. Once I had to transfer it 11 times, before E5186 got all the bits of it.
Don't lose hope here!
Completing update
When your upgrade is completed and you're ready to power off the router, LEDs will look like this:
 The Wi-Fi LED will go on and off slowly. It will keep doing that forever or until you power of the unit, whichever comes first.
The Wi-Fi LED will go on and off slowly. It will keep doing that forever or until you power of the unit, whichever comes first.
Now you're done!
Go ahead kick the power back on and see how it went.
Huawei E5186 RS-232 pins explained
Saturday, January 23. 2016
For the 2nd time, I got an E5186 loaner (post about the 1st time here). This time with permission to take a closer look inside.
Since this one had already RS-232 wires soldered, I took them for closer inspection. Un-boxing is exactly like in B593, 3 PH-2 screws holding the cover in place. Two at the bottom of the unit (one covered with a warranty paper) and one screw at the back between LTE-antennas.
Layout
After popping the cork, the board's flipside looks like this:

In this unit, there is no need to pry open none of the 4 shiny ESD covers. All the good stuff is on the other side. Again, 4 PH-2 screws holding the board in place.
Board, right side up:

In this case, the obvious clue for me was the already soldered RS-232 wires. I'm also publishing another picture by KOSH, a LTEforum.at activist, describing some of the good parts an E5186 board has:

There are 2 of: LTE/UMTS antennas on top corners, 5 GHz WLAN antennas at the sides and 2,4 GHz WLAN antennas on the bottom corners. The picture doesn't point out the locations of RS-232 pins, only the ground and Vcc pins.
Linux
A closer look of the Linux side pins right next to the SIM-slot:

No surprises there, the signal levels of RS-232 were 1,8 volts. It means, that an expensive USB-RS232 adapter is rquired for access. Your run-of-the-mill cheap 3,3 volt adapters are completely useless for this.
The descripions of RX/TX are from the point of the router (DCE), not from your computer (that would be DTE). It means, that any output signal (TX or transmit) described in the picture should be connected to input of the computer (RX or receive).
A bootup output of that port would be:
Digital core power voltage set to 0.9375V
Decompressing...done
CFE version 6.37.14.34 (r415984) based on BBP 1.0.37 for BCM947XX (32bit,SP,)
Build Date: Sat Jun 13 09:28:20 CST 2015 (l00285057@MBB-V7R1-CPE)
Copyright (C) 2000-2008 Broadcom Corporation.
Init Arena,cfe repair version
Config GPIOs.
Init Devs.
Boot partition size = 262144(0x40000)
flash_init: bootsz = [0x80000]
add new online part !!!!!!!!
flash_init:flash_size:[0x8000000][0x2000000|33554432]
DDR Clock: 400 MHz
Info: DDR frequency set from clkfreq=800,*400*
et0: Broadcom BCM47XX 10/100/1000 Mbps Ethernet Controller 6.37.14.34 (r415984)
CPU type 0x0: 800MHz
Tot mem: 131072 KBytes
CFE mem: 0x00F00000 - 0x010AC8E4 (1755364)
Data: 0x00F646F0 - 0x00F65184 (2708)
BSS: 0x00F65190 - 0x00FAA8E4 (284500)
Heap: 0x00FAA8E4 - 0x010AA8E4 (1048576)
Stack: 0x010AA8E4 - 0x010AC8E4 (8192)
Text: 0x00F00000 - 0x00F55E40 (351808)
Device eth0: hwaddr 00-90-4C-0F-0F-00, ipaddr 192.168.1.1, mask 255.255.255.0
gateway not set, nameserver not set
not in router upgrade mode
Loader:raw Filesys:raw Dev:nflash0.os File: Options:(null)
Loading: ..... 5853216 bytes read
Entry at 0x00008000
Closing network.
Starting program at 0x00008000
[ 2.950000] console [ttyS0] enabled, bootconsole disabled
[ 2.950000] serial8250.0: ttyS1 at MMIO 0x18000400 (irq = 117) is a 16550
[ 2.960000] brd: module loaded
[ 2.970000] loop: module loaded
[ 2.970000] [CHIP_COMM] LINE:849: [client] socket send fail!
[ 2.980000] DRV_RHPC: Detect Modem fail with 0x1, run startup status detection thread!!
[ 2.990000] Platform Driver Remote Host Procedure Call init.
[ 2.990000] Enter ecall init
[ 3.000000] Finish ecall init
[ 3.000000] tsk:kthread_run is success!
[ 3.000000] SCSI Media Changer driver v0.25
[ 3.010000] pflash: found no supported devices
[ 3.020000] bcmsflash: found no supported devices
[ 3.070000] Boot partition size = 524288(0x80000)
[ 3.080000] lookup_nflash_rootfs_offset: offset = 0x200000
[ 3.080000] nflash: squash filesystem with lzma found at block 35
[ 3.090000] Creating 4 MTD partitions on "nflash":
[ 3.090000] 0x000000000000-0x000000080000 : "boot"
[ 3.100000] 0x000000080000-0x000000200000 : "nvram"
[ 3.110000] 0x000000200000-0x000002a00000 : "linux"
[ 3.110000] 0x0000004600f8-0x000002a00000 : "rootfs"
[ 3.120000] PPP generic driver version 2.4.2
[ 3.120000] PPP Deflate Compression module registered
[ 3.130000] PPP BSD Compression module registered
[ 3.130000] PPP MPPE Compression module registered
[ 3.140000] NET: Registered protocol family 24
[ 3.140000] SLIP: version 0.8.4-NET3.019-NEWTTY (dynamic channels, max=256).
[ 3.150000] usbmon: debugfs is not available
[ 3.150000] ehci_hcd: USB 2.0 'Enhanced' Host Controller (EHCI) Driver
[ 3.160000] ehci_hcd 0000:00:0b.1: EHCI Host Controller
[ 3.170000] ehci_hcd 0000:00:0b.1: new USB bus registered, assigned bus number 1
[ 3.210000] ehci_hcd 0000:00:0b.1: irq 111, io mem 0x18021000
[ 3.230000] ehci_hcd 0000:00:0b.1: USB 0.0 started, EHCI 1.00
[ 3.230000] hub 1-0:1.0: USB hub found
[ 3.240000] hub 1-0:1.0: 2 ports detected
[ 3.240000] ohci_hcd: USB 1.1 'Open' Host Controller (OHCI) Driver
[ 3.250000] ohci_hcd 0000:00:0b.0: OHCI Host Controller
[ 3.250000] ohci_hcd 0000:00:0b.0: new USB bus registered, assigned bus number 2
[ 3.260000] ohci_hcd 0000:00:0b.0: irq 111, io mem 0x18022000
[ 3.320000] hub 2-0:1.0: USB hub found
[ 3.320000] hub 2-0:1.0: 2 ports detected
[ 3.330000] xhci_hcd 0000:00:0c.0: xHCI Host Controller
[ 3.330000] xhci_hcd 0000:00:0c.0: new USB bus registered, assigned bus number 3
[ 3.340000] xhci_hcd 0000:00:0c.0: irq 112, io mem 0x18023000
[ 3.350000] xhci_hcd 0000:00:0c.0: Failed to enable MSI-X
[ 3.350000] xhci_hcd 0000:00:0c.0: failed to allocate MSI entry
[ 3.360000] usb usb3: No SuperSpeed endpoint companion for config 1 interface 0 altsetting 0 ep 129: using minimum values
[ 3.370000] xHCI xhci_add_endpoint called for root hub
[ 3.380000] xHCI xhci_check_bandwidth called for root hub
[ 3.380000] hub 3-0:1.0: USB hub found
[ 3.390000] hub 3-0:1.0: 1 port detected
[ 3.390000] usbcore: registered new interface driver cdc_acm
[ 3.400000] cdc_acm: v0.26:USB Abstract Control Model driver for USB modems and ISDN adapters
[ 3.410000] usbcore: registered new interface driver usblp
[ 3.410000] Initializing USB Mass Storage driver...
[ 3.420000] usbcore: registered new interface driver usb-storage
[ 3.420000] USB Mass Storage support registered.
[ 3.430000] usbcore: registered new interface driver usbserial
[ 3.430000] USB Serial support registered for generic
[ 3.440000] usbcore: registered new interface driver usbserial_generic
[ 3.450000] usbserial: USB Serial Driver core
[ 3.450000] USB Serial support registered for GSM modem (1-port)
[ 3.460000] usbcore: registered new interface driver option
[ 3.460000] option: v0.7.2:USB Driver for GSM modems
[ 3.470000] USB Serial support registered for pl2303
[ 3.470000] usbcore: registered new interface driver pl2303
[ 3.480000] pl2303: Prolific PL2303 USB to serial adaptor driver
[ 3.480000] u32 classifier
[ 3.490000] Performance counters on
[ 3.490000] Actions configured
[ 3.490000] Netfilter messages via NETLINK v0.30.
[ 3.500000] nf_conntrack version 0.5.0 (1935 buckets, 7740 max)
[ 3.510000] ctnetlink v0.93: registering with nfnetlink.
[ 3.510000] nf_conntrack_rtsp v0.6.21 loading
[ 3.520000] xt_time: kernel timezone is -0000
[ 3.520000] IPVS: Registered protocols ()
[ 3.520000] IPVS: Connection hash table configured (size=4096, memory=32Kbytes)
[ 3.530000] IPVS: ipvs loaded.
[ 3.530000] IPv4 over IPv4 tunneling driver
[ 3.540000] nf_nat_rtsp v0.6.21 loading
[ 3.540000] ip_tables: (C) 2000-2006 Netfilter Core Team
[ 3.550000] arp_tables: (C) 2002 David S. Miller
[ 3.550000] TCP cubic registered
[ 3.560000] NET: Registered protocol family 10
[ 3.560000] lo: Disabled Privacy Extensions
[ 3.570000] tunl0: Disabled Privacy Extensions
[ 3.570000] ip6_tables: (C) 2000-2006 Netfilter Core Team
[ 3.580000] IPv6 over IPv4 tunneling driver
[ 3.580000] sit0: Disabled Privacy Extensions
[ 3.590000] ip6tnl0: Disabled Privacy Extensions
[ 3.590000] NET: Registered protocol family 17
[ 3.600000] Bridge firewalling registered
[ 3.600000] Ebtables v2.0 registered
[ 3.600000] L2TP core driver, V2.0
[ 3.610000] PPPoL2TP kernel driver, V2.0
[ 3.610000] 802.1Q VLAN Support v1.8 Ben Greear
[ 3.620000] All bugs added by David S. Miller
[ 3.640000] Northstar brcmnand NAND Flash Controller driver, Version 0.1 (c) Broadcom Inc. 2012
[ 3.650000] NAND device: Manufacturer ID: 0x2c, Chip ID: 0xf1 (Micron NAND 128MiB 3,3V 8-bit)
[ 3.660000] Spare area=64 eccbytes 56, ecc bytes located at:
[ 3.660000] 2 3 4 5 6 7 8 9 10 11 12 13 14 15 18 19 20 21 22 23 24 25 26 27 28 29 30 31 34 35 36 37 38 39 40 41 42 43 44 45 46 47 50 51 52 53 54 55 56 57 58 59 60 61 62 63
[ 3.680000] Available 7 bytes at (off,len):
[ 3.680000] (1,1) (16,2) (32,2) (48,2) (0,0) (0,0) (0,0) (0,0)
[ 3.690000] Scanning device for bad blocks
[ 3.780000] Options: NO_AUTOINCR,NO_READRDY,BBT_SCAN2NDPAGE,
[ 3.790000] Creating 5 MTD partitions on "brcmnand":
[ 3.790000] 0x000002a00000-0x000003e00000 : "userdata"
[ 3.800000] 0x000003e00000-0x000005200000 : "app"
[ 3.800000] 0x000005200000-0x000005c00000 : "webui"
[ 3.810000] 0x000005c00000-0x000006000000 : "online"
[ 3.810000] 0x000006000000-0x000008000000 : "upg"
[ 3.830000] VFS: Mounted root (squashfs filesystem) readonly on device 31:3.
[ 3.840000] devtmpfs: mounted
[ 3.840000] Freeing init memory: 236K
/sbin/hotplug2: No such file or directory
insmod: ipv6.ko: no module by that name found
insmod: cannot insert '/lib/modules/2.6.36.4brcmarm+/kernel/drivers/net/igs/igs.ko': Operation not permitted (-1): Operation not permitted
hotplug detected product: 12d1/1443/1
hotplug detected product: 12d1/1443/1
insmod: bcm57xx.ko: no module by that name found
boardflags:100
That looks a lot like a B593-s22 booting. A 2.6.36 Linux there running on a 32-bit BCM947XX chip.
LTE
The other RS-232 port has following pins:

It outputs something like this on a boot:
onchip
NF boot!
UnSec_boo Wä123
sec disable
456
[0000005ms]
[0000005ms]
[0000005ms]*********************************************************
[0000006ms]FASTBOOT simple console, enter 'help' for commands help.
[0000006ms]*********************************************************
[0000006ms]balong_version_get_hw_version doesn't judge udp!
[0000007ms]balong_version_get_hw_version: HARDID = 0X00040000
[0000007ms]Hisilicon NANDC_V6.00 initialize...
[0000007ms]NAND device: Manufacturer ID: 0x000000ad, Chip ID: 0x000000ac (Hynix NAND 512MiB 1,8V 8-bit)
[0000008ms]Partition Table list(HEX):ptable 1.00HI6930_V7R2_MCPEm3boot
[0000008ms]NO. |offset |loadsize |capacity |loadaddr |entry |property |count |id |name |
[0000009ms]------------------------------------------------
[000000Ams]00000001: 00000000 ,00000000 ,00040000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000101 ,m3boot
[000000Ams]00000002: 00040000 ,00000000 ,001c0000 ,4fe00000 ,4fe00000 ,00004000 ,00000000 ,00000102 ,fastboot
[000000Bms]00000003: 00200000 ,00000000 ,00200000 ,00000000 ,00000000 ,00004800 ,00000000 ,00000103 ,nvbacklte
[000000Cms]00000004: 00400000 ,00000000 ,00400000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000104 ,nvimg
[000000Cms]00000005: 00800000 ,00000000 ,00400000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000105 ,nvdload
[000000Dms]00000006: 00c00000 ,00000000 ,00200000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000106 ,nvdefault
[000000Ems]00000007: 00e00000 ,00000000 ,00400000 ,00000000 ,00000000 ,00004000 ,00000000 ,0000010d ,oeminfo
[000000Ems]00000008: 01200000 ,00000000 ,0be00000 ,00000000 ,00000000 ,00004001 ,00000000 ,00000116 ,online
[000000Fms]00000009: 0d000000 ,00000000 ,00800000 ,4ffc0000 ,4ffc0000 ,00004000 ,00000000 ,00000107 ,kernel
[0000010ms]0000000a: 0d800000 ,00000000 ,00800000 ,4ffc0000 ,4ffc0000 ,00004000 ,00000000 ,00000108 ,kernelbk
[0000010ms]0000000b: 0e000000 ,00000000 ,00200000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000109 ,m3image
[0000011ms]0000000c: 0e200000 ,00000000 ,00600000 ,00000000 ,00000000 ,00004000 ,00000000 ,0000010b ,dsp
[0000011ms]0000000d: 0e800000 ,00000000 ,00200000 ,00000000 ,00000000 ,00004000 ,00000000 ,0000011b ,misc
[0000012ms]0000000e: 0ea00000 ,00000000 ,02800000 ,50d10000 ,50d10000 ,00004000 ,00000000 ,0000010a ,vxworks
[0000013ms]0000000f: 11200000 ,00000000 ,00100000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000112 ,wbdata
[0000013ms]00000010: 11300000 ,00000000 ,00100000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000113 ,reserve2
[0000014ms]00000011: 11400000 ,00000000 ,00300000 ,00000000 ,00000000 ,00004001 ,00000000 ,00000114 ,reserve3
[0000015ms]00000012: 11700000 ,00000000 ,00c00000 ,00000000 ,00000000 ,00004001 ,00000000 ,0000010f ,om
[0000015ms]00000013: 12300000 ,00000000 ,0ad00000 ,00000000 ,00000000 ,00004001 ,00000000 ,0000010e ,system
[0000016ms]00000014: 1d000000 ,00000000 ,02d00000 ,00000000 ,00000000 ,00004001 ,00000000 ,00000117 ,cdromiso
[0000017ms]00000015: 1fd00000 ,00000000 ,00280000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000118 ,cache
[0000017ms]00000016: 1ff80000 ,00000000 ,00040000 ,00000000 ,00000000 ,00004000 ,00000000 ,00000119 ,recovery-a
[0000018ms]00000017: 1ffc0000 ,00000000 ,00040000 ,00000000 ,00000000 ,00004000 ,00000000 ,0000011a ,recovery-b
[0000019ms]^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[0000019ms]fastboot: nv dload cap is 0x00400000.
[000001Ams]fastboot: dload nv invlv_blk_num:7, total_blk_num:32!
[000001Ams]fastboot: dload nv skip total bad blk:0!
[000001Bms]warning: end page size not aligned :addr_logic:0x008e5000,blockleft:0x00000104
[0000025ms]nv boot init ok!
[0000026ms][tsensor]: tsensor init ok!
[0000026ms]board_init ok
[0000028ms]USB FastBoot: V0.9
[0000028ms]Machine ID: 3339 v0
[0000028ms]Build Date: Jun 13 2015, 09:54:53
[0000028ms]
[0000028ms]Serial Number: UNKNOWN
[0000028ms]
[0000028ms]Heap:0x5fd3c220 -- 0x5fd3c860, 1600
[0000029ms][pmu]: volt_id 35's voltage can not be set!
[0000029ms]
[0000029ms][pmu]: volt_id 39's voltage can not be set!
[000002Ams]
[000002Ams]Please distribute uart with command L/V/M...
[000002Ams] heap:0x5fd3c220 -- 0x5fd3c860, 1600
[000002Ams]OCR_AUTO_ENUM_FLAG_ADDR = 4fe1fff8 flag =eab35f51 !
[000002Bms]
[000002Bms] [ ON OFF ] Start up by Cold Reset!,reboot_cmd=0x90a7b368.
[000002Bms]balong_version_get_hw_version doesn't judge udp!
[000002Cms]balong_version_get_hw_version: HARDID = 0X00040000
[000002Cms]balong_version_get_hw_version doesn't judge udp!
[000002Cms]balong_version_get_hw_version: HARDID = 0X00040000
[000002Dms][fastboot]: boot_mode 1
[000002Dms]boot m3image from flash
[000002Dms]ptn:5fd36bbc , ptn->start = 0e000000 ptn->length = 00200000
[000002Dms]ptn:5fd36bbc , ptn->loadaddr = 00000000 ptn->entry = 00000000
[000002Ems]warning: end page size not aligned :addr_logic:0x0e00b000,blockleft:0x000003a8
[000002Fms]boot linux from flash
I don't think this side boots properly, so the output has only HiSilicon NAND-flash and Hynix DRAM mentioned.
Finally
I didn't manage to get any kind of console or prompt. There are couple of points where the Linux-side says "Press Enter to continue...", but event that didn't work. To me, it looks like the unit is not taking any input.
If you have any further information, please drop a comment below.
What is the going price for ... ?
Thursday, January 21. 2016
Just something out of one honeypot:
INbox mailer ==>> $7 Smtp Inbox Ip ==>> $ 10 Smtp inbox Domain ==>> $8 Smtp Unlimited ==>> $20 Shell ==>> $4 cPanel ==>> $5 RDP administrator ==>> $15 RDP user ==>> $6 SSH ROOTS ==>> $8 Emails Leads Individual 100,000 ==>> $25 Emails leads Co-operate 100,000 ==>> $50
If you're paying more than that, they're ripping you off.
Since the product descriptions are quite terse, I'm not sure what is an "INbox mailer", or what's the difference between "Smtp Inbox Ip" and "Smtp inbox Domain". A "Shell" or "cPanel" is self-descriptive, that's a simple access to *nix or a web-based hosting system. RDPs are for Windows remote access. But if you're buying 100k e-mail addresses, why are co-operate ones twice as expensive? That I don't know.
If you purchase those services, please let me know!
Doing fiber installations
Sunday, January 17. 2016
Year and half ago I wrote about my new super-fast Internet-connection. Since in this area the fiber-connections are installed to all buildings regardless you're going to use it or not, I had a possibility to start using also the second one. As the connection was already there, all my telco had to do was send the cable guy to install a fiber to copper media converter.
Or, so you'd think. The standard operating procedure seems to be to ship out needed hardware from the telco's central warehouse to me and eventually the cable guy would arrive and do the setup. The sales guy failed to mention this procedure to me. I received a shipment of my brand new toys:

I just unboxed all the stuff and started studying how to do the installation myself. My own experience on the subject is highly limited. Whenever fiber-optics are involved, all the installations are done by trained professionals, not curious hackers like me.
Anyway, this is the media converter a CTS (Connection Technology Systems, aka. Zyxel) HET-3005:

Specs say:
- Interface
- LAN Port: 10/100/1000Base-T RJ-45 x 4
WAN Port: 1000Base-X x 1 or 10/100/1000Base-T x 1
- LAN Port: 10/100/1000Base-T RJ-45 x 4
- Standards
- IEEE 802.3 10Base-T
- IEEE 802.3u 100Base-TX/FX
- IEEE 802.3ab 1000Base-T
- IEEE 802.3z 1000Base-X
- IEEE 802.3x Flow Control
According to manual, a HET-3005 comes in multiple versions. Mine is a model: HET-3005W2A(SM-10/20)-DR, it has following ports in it:
- Fiber Port
- Speed: 1000
- Type: WDM
- Connector: SC
- Distance: 10/20KM
- Ports: 1
- TP Port
- Speed: 10/100/1000
- Ports: 4
In the fiber-world it seems, that connectors are always inside the box, of course I had to pop the hood:

On top of the pic, there is a fiber connector (a SC-connector, I guess):

It mentions following details:
- Dual rate
- Single mode, 10 km
- TX/RX: 1310/1550 nm
When studying Gigabit Ethernet, the only possible ones are:
- 1000BASE-LX10
- Single-mode fiber using 1310 nm wavelength 10 km
- 1000BASE-BX10
- Single-mode fiber, over single-strand fiber: 1490 nm downstream 1310 nm upstream 10 km
For obvious reasons of not having dual-rate in it, LX10 goes out. However in BX10, it's funny how specs mention downstream to be 1490 nm, but the equipment has 1550 nm.
So, only with the box, there isn't much to do. Luckily they kinda knew it and in the box there was a suitable patch cable:

The ends are different. I don't know why, but studying the Wikipedia article about Optical fiber connector says, that IEC 61754-4 defines a SC-connector. A careful analysis of it revealed, that the square one wasn't a match for the HET-3005. The wider one with non-square form fits in nicely:

Now I'll need to figure out what to do with the other end. I went to study the connections. A following box with obvious incoming fiber-optic cable rising from the ground was attached to a wall:

Sure thing, I popped the hood on that to see what it had eaten:

At the lower left hand corner, there is a black cable incoming. The cable guy stripped it and exposed the single-mode fibers in it (two of them) and welded them into the fiber of the blue connector. The welds have been properly covered with some sort of shink-wrap and can be seen in the yellow cable holder. Since the black box was a dead end, it had no electrical parts in it, my next focus was the blue connector at the bottom of the box:

That red connector had a fiber running to a box converting fiber to a DVB-C -signal and distributing that on a 75 Ω coaxial cable for TV-signal distribution into my house. However, the right connector was free. I simply had to try it:

Yep! A nice fit. The more important thing was, that it made my media converter box to indicate a functioning WAN-signal.
Just to confirm the SC-connector, I went back to pictures of my Inteno FG500, it had:

But that's inside the box, it has dual-purpose functionality of doing TV-signal and ethernet in two halves of the same unit.
After couple of days me finishing the install, the cable guy called in and wanted to come do the setup. I just told him that's its all done and ready.
Recycling used Samsung laser printer cartridges
Wednesday, January 6. 2016
Every now and then I need a paper copy of something. In Finland, which to my observations is quite far advanced in the paperless processes (working environment or otherwise), that's rare. The obvious exception to the rule is bookkeeping and banks. They won't live without a hard-copy of something. For the purpose of producing a printout I have a Samsung color laser printer. When it was new, I even made a humorous note of it.
The general grievance about modern printers is, that they cost around € 200,- and almost immediately run out of [insert a name of expensive supply product here]. In my case, nothing else than all colors cost way above € 300,-. But that's not my rant-of-the-day, I knew all about that when I decided to have the unit shipped to my front door. Korean engineers @ Samsung made the actual process of changing a color cartridge a very simple one. I have to say, that hardest part in that is un-boxing the new ones. They are so tightly vacuum-sealed. So, no groaning about that one either.
What do you do with those darned expired things, when you're done!!

I had replaced the black cartridge earlier, it always runs out first. In this instance, I replaced only the colour ones (CMY). So, only 3 useless boxes to throw out of the house.
From The Web, I found somebody having the same problem. This article is in Finnish, but it's pretty much about Samsung color cartridge not having any kind of recycling info in it. Samsun's rep reponnds, that "oh yes, there are instructions". This is the only thing I found about the subject:

It says to go to www.samsung.com/printer/recycle for information. I did and landed at Samsung S.T.A.R Programme (Samsung’s Takeback And Recycle). It has following information about returning used cartridges at How to return your used cartridge -page:
- Place your used cartridge in the bag and box which came with your new Samsung toner cartridge. In case you wish to send more than one cartridge for recycling, please put all cartridges in one big box, or tape the individual boxes together.
- Close the box using clear tape;
- Register yourself/your company on our STAR website. In case you have already registered yourself/your company, please log in using your user name and password. Chose the number of empty cartridges you would like to return and press the ‘get your label!’ button. Your order will be processed immediately. Only one (1) return label will be sent to your registered email address or will pop up at your screen;
- Print the return label and place it on the large side of the box. If the return label contains a bar code, please keep this bar code visible;
- Drop off your box at the nearest post office or include it in your usual mail collection.
Well, I guess I'll have to register to the site and get myself some clear packing tape. After doing that, it was possible to print following packing slip:

Looks like a valid customer return information required by postal services. Now the last thing is to go to a post office and leave the bundle there.
So, the information was there. Obviously the entire process is a bit more complex than just taking out the garbage, but I guess Samsung guys will properly handle all the troublesome waste there. That should save the Earth!
S9y plugins: Adding codeTag into CKEditor
Sunday, January 3. 2016
As you may have noticed, I blog a lot about code, computers and operating system configurations. In writtern form, it is very convenient to use Teletype Text -formatting. Here is a demo of the difference:
Do Until NoMoreSwaps = True
NoMoreSwaps = True
For Counter = 1 To (NumberOfItems - 1)
If List(Counter) > List(Counter + 1) Then
NoMoreSwaps = False
Temp = List(Counter)
List(Counter) = List(Counter + 1)
List(Counter + 1) = Temp
End If
Next
NumberOfItems = NumberOfItems - 1
Loop
and:
Do Until NoMoreSwaps = True
NoMoreSwaps = True
For Counter = 1 To (NumberOfItems - 1)
If List(Counter) > List(Counter + 1) Then
NoMoreSwaps = False
Temp = List(Counter)
List(Counter) = List(Counter + 1)
List(Counter + 1) = Temp
End If
Next
NumberOfItems = NumberOfItems - 1
Loop
(Code sample courtesy of Rosetta Code)
Any experienced software developer will prefer the fixed-width font. However, an out-of-the-box Serendipity blog software won't make that possible. I don't get the logic behind that, but there is a drastic change in functionality. To the not-so-user-friendly direction, I'd like to add.
Since version 2.0 S9y has been using CKEditor as HTML-editor on the admin-side. It is a pretty good component and has a number of excellent plugins already available. Getting a codeTag-plugin to work shouldn't be too hard, I guess. Yep! Guessed wrong.
Just downloading a zip-file, and uncompressing it at serendipity/htmlarea/ckeditor/ckeditor/plugins/-directory. Is a good start, but the editor won't react to that, something more is needed.
After a lot of investigating, I figured to add the name of the plugin into into serendipity/htmlarea/ckeditor_s9y_plugin.js. It has a line in it:
var customplugins = 'mediaembed,procurator,cheatsheet,';
adding codeTag into the list does absolutely nothing. It does load the plugin, but as a default, the plugin does nothing that you can see or touch. There is another file with list of editor's icons at serendipity/htmlarea/ckeditor_s9y_config.js. It has an array with list of icons to display:
config.toolbar_Default = []
It looks like this:

After adding this hash-definition into the config.toolbar_Default -array:
{ name: 'codetag', items: [ 'Code' ] }
makes the icon to appear:

... but it doesn't do much when you click it.
Yet another round of debugging revealed, that there is a fixed list of allowed HTML-tags in the same file. The variable is called config.extraAllowedContent. The line is very long, but abbreviated version is something like this:
config.extraAllowedContent = 'mediainsert[*]{*}(*); ... ;pre[*](*);';
I added this to the end of the list:
code;tt;
Now it works as expected!
If you're planning a patch, here are my changes. Run it in serendipity/htmlarea/:
--- ckeditor_s9y_plugin.js.orig 2015-07-24 15:02:54.000000000 +0300
+++ ckeditor_s9y_plugin.js 2016-01-01 15:52:18.333527235 +0200
@@ -17,7 +17,7 @@
// Plugin Dependencies: widget Add-on Dependencies: Line Utilities and Clipboard
// mediaembed is a fast and simple YouTube code CKEditor-Plugin: v. 0.5+ (https://github.com/frozeman/MediaEmbed, 2013-09-12) to avoid ACF restrictions
// procurator and cheatsheet are S9y only plugins
- var customplugins = 'mediaembed,procurator,cheatsheet,';
+ var customplugins = 'mediaembed,procurator,cheatsheet,codeTag,';
// for any new instance when it is created - listen on load
CKEDITOR.on('instanceReady', function(evt){
--- ckeditor_s9y_config.js.orig 2015-07-24 15:02:54.000000000 +0300
+++ ckeditor_s9y_config.js 2016-01-01 16:07:39.055518012 +0200
@@ -65,7 +65,7 @@
- Allow for custom attributes/classes in code blocks
*/
// protect
- config.extraAllowedContent = 'mediainsert[*]{*}(*);gallery[*]{*}(*);media[*]{*}(*);script[*]{*}(*);audio[*]{*}(*);div[*]{*}(*);span[*]{*}(*);img[height,width];pre[*](*);';
+ config.extraAllowedContent = 'mediainsert[*]{*}(*);gallery[*]{*}(*);media[*]{*}(*);script[*]{*}(*);audio[*]{*}(*);div[*]{*}(*);span[*]{*}(*);img[height,width];pre[*](*);code;tt;';
// Do not use auto paragraphs, added to these allowed tags (only!). Please regard that this was marked deprecated by CKE 4.4.5, but is a need for (our use of) extraAllowedContent - check this again by future versions!
config.autoParagraph = false; // defaults(true)
@@ -252,7 +252,8 @@
{ name: 'mediaembed', items: [ 'MediaEmbed' ] },
{ name: 'others', items: s9ypluginbuttons },
{ name: 'document', groups: [ 'mode', 'document', 'doctools' ], items: [ 'Source' ] },
- { name: 'about', items: [ 'About' ] }
+ { name: 'about', items: [ 'About' ] },
+ { name: 'codetag', items: [ 'Code' ] }
];
// console.log(JSON.stringify(config.toolbar_s9y));
Recovering Windows 7 OEM License Key
Saturday, January 2. 2016
In my hugely popular article about Transferring Windows 7 OEM license to a new hard drive, I kept insisting, that you absolutely positively need to know your SLP-key before processing. Couple days ago I was working on a recovery of a failed hard drive and realized, that it's not completely true.
As the troubled drive had already been replaced with a brand new SSD, I had the HDD in an USB-dock for investigation purposes:

The new Windows 7 OEM had already been installed, but not activated. As I didn't know the SLP-key I was planning to do the phone activation with COA-key. At that point I realized, that it was possible to use the Magical Jelly Bean Keyfinder from another drive:
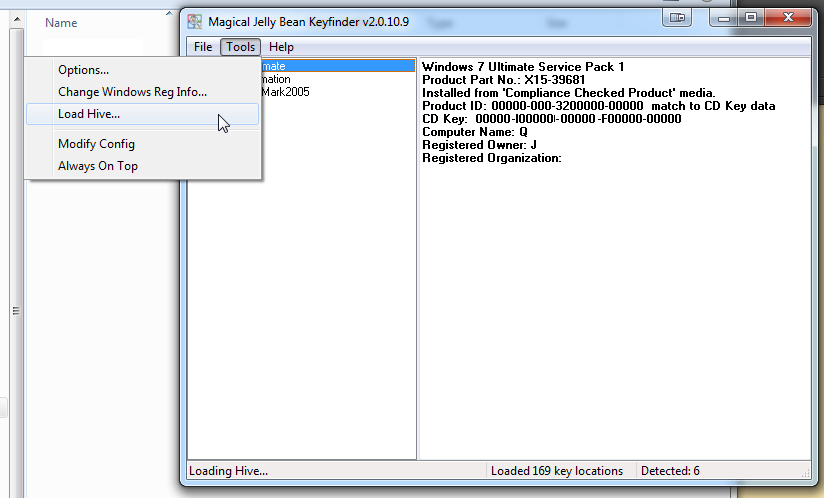
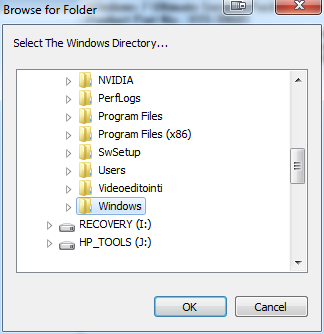
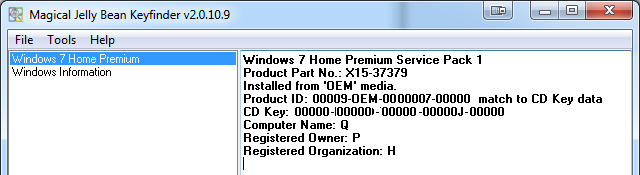
It wasn't much simpler than that! A simple copy/paste -operation to get the key in and Windows activated.
The requirement seems to be to point to a %windir% and system32\config\ is assumed on top of that.
Storix - Story of Anthony Johnson continues
Friday, January 1. 2016
Earlier I wrote about Storix and it's author Mr. Johnson.
The story developed further on 15th Dec when a jury gave its verdict about the copyright infrightment claim. A court decided that the copyrigt was transferred to company on 2003. Mr. Johnson claimed that a written memo of 2004 as an annual report didn't transfer the copyright:
It foolishly stated that my sole proprietorship was changed to an S Corp and "all assets" were
transferred over. Of course, I was referring to the cash in the business account, the furniture and
computers. But the jury, based on the courts generic instructions which were contrary to actual
copyright law, decided that it should include any personal assets related to the business,
or any "language that might encompass a copyright".
Obviously this is not the end of the story. There will be a round of appeals.
Btw. In their press release Storix claims to be "the #1 provider of disaster recovery solutions for more than 2,000 global customers". I think there has to be some other player in the disaster recovery business having more customers.
64-bit Firefox for Windows - Finally!
Sunday, December 20. 2015
On version 43 Firefox announced: Firefox 64-bit for Windows Available.
Whoa! Already? I've been waiting for that to happen since 2005 when Fedora Core 4 was released. It had a 64-bit Firefox in it. Actually Fedora Core 3 had one, but it was a beta version and I didn't use it ever. So my 11 year wait is over.
Mozilla's release policy is ... how to put it ... confusing? Insane? Mindless? Linux and OS X had proper versions of my favorite browser years ago, but on Windows, they seriously dopped the ball. Competition have had 64-bit builds for: Internet Explorer, Opera, Chrome, Dillo and what not. Even the mostly malfunctioning slow piece of crap Edge has a 64-bit build of it.
Back in 2011 there was a decent version of 64-bit Firefox 8 in the works. See article Firefox 8 for Windows x64: Has 64-bit browsing finally come of age? about that. Then came 2012 and at end of that year something happened: Mozilla quietly kills Firefox 64-bit for Windows, despite an estimated 50% of testers using it.
Here is the 2012 Mozilla’s manager list of bullshit reasons for not doing a 64-bit version:
- Many plugins are not available in 64-bit versions.
- The plugins that are available don’t work correctly in Firefox because we haven’t implemented things like windowproc hooking, which means that hangs are more common.
- Crashes submitted by 64-bit users are currently not high priority because we are working on other things.
- This is frustrating for users because they feel (and are!) second-class.
- It is also frustrating for stability team triage because crash-stats does not easily distinguish between 32-bit and 64-bit builds in the topcrash lists and other reports. We basically ignore a set of nightly “topcrashes” because they are 64-bit only. (See bug 811051).
I'd still like to point out that at that time Linux and OS X had it. The list is total bullshit, as the crash reports and triage would have easily identified build bitness with minor changes, if only there would have been a true will of doing it. Most of people like me didn't care about lacking plugin support. Everything that I needed was already there and working.
Since there were a lot of comments about not doing the 64-bit Windows version, there was some flip-flopping about the decision: Mozilla backpedals on Firefox 64-bit for Windows, will keep nightly builds coming after all.
There were couple of silent years, then the project had a come-back. On 2014: Mozilla is making plans for 64-bit Firefox browser. As the decision was in to go for 64-bit, the only thing missing was developer resources. Obviously Mozilla was busy developing features, not the 64-bit build. Hower, last summer there was news: Mozilla delays 64-bit Firefox for Windows again. And finally, couple of releases later they had the official stable version out.
The obvious effect will be for Cyberfox. 8pecxstudios has been very active in the 64-bit scene and I've been using their excellent product for couple of years. My previous favorite, Waterfox advertises being a high performance browser based on the Mozilla platform made specifically for 64-Bit systems. They say that Waterfox has one thing in mind: speed, however, it's in a very low maintenance mode and currently it is 3 versions behind. In my book, that's unmaintained already.
I strongly doubt that none of the excuse-list items have vaporized. I'm glad that the version is out, but not very happy that it took so many years. This entire case is a disgrace.
Stop the insanity! There are TLDs longer than 4 characters
Wednesday, December 2. 2015
Installing multi-user Ruby with RVM
Tuesday, November 24. 2015
I needed to run some Ruby-code in my Fedora-box, but the RPM-packaged version wasn't a decent or recent one. Since it is standard procedure and native to Ruby programming language to use Ruby version manager (or RVM), it also opens immense possibilities of running any existing Ruby version in same machine without the versions colliding with each other, this is definitely something that people need to know how to do.
There is plenty of good information about this in the net, for example How to Install Ruby 2.1.2 on CentOS & RHEL using RVM. However, the definite source is of course Installing RVM manual at RVM.io.
When it comes to multi-user installations, docs say "For server administrators - For an installation usable by all users on the system - This also used to be called the System-Wide Install. Using this type of installation without knowledge how umask works is a big security risk". RVM has a very simple filesystem permission -based security model, which will collapes if umask is not set correctly in multi-user mode. However, the worst-case scenarios include some gems have incorrect permissions set and only the user how installed it can un-install. Ultimate worst-case scenario is, that people not belogning to rvm-group can install and un-install modules. In a system-wide setup other people tampering with critical resources can be fatal, hence the obligatory warnings.
My case is much simpler, I need the same stuff for myself to develop with and for the system to run with. That's how I know I develop, test and run the same libraries. I wouldn't dream on sharing the stuff with other persons and calling that secure.
Back to setup of my RVM, current ruby version information:
$ ruby -v
ruby 2.0.0p353 (2013-11-22 revision 43784) [x86_64-linux]
To start the installation, a simple one-liner will do:
$ curl -sSL http://get.rvm.io | sudo bash -s stable -- --ignore-dotfiles
It will download the latest stable installer bash-script and immediately execute it with flag not to use user's own files. This is more suitable for machine-wide mode. The really important thing is to use sudo. Installation will fail to setup correctly, if doing it as root. Another security warning here: you will be trusting blindly on something you downloaded from the web. Hey! They call it open-source.
The installation will work only on Bourne shells. I'd recommend using Bash with all RVM-operations. The installer will say something like this:
Downloading https://github.com/rvm/rvm/archive/master.tar.gz
Creating group 'rvm'
Installing RVM to /usr/local/rvm/
Installation of RVM in /usr/local/rvm/ is almost complete:
First you need to add all users that will be using rvm to 'rvm' group,
and logout - login again, anyone using rvm will be operating with `umask u=rwx,g=rwx,o=rx`.
To start using RVM you need to run `source /etc/profile.d/rvm.sh`
in all your open shell windows, in rare cases you need to reopen all shell windows.
# Thank you for using RVM!
# We sincerely hope that RVM helps to make your life easier and more enjoyable!!!
#
# ~Wayne, Michal & team.
In case of problems: http://rvm.io/help and https://twitter.com/rvm_io
If your system didn't have an user group called rvm, it does now. As the instructions say, it's your task now to assign users to that group. You can do it like this:
$ getent group rvm
rvm:x:983:
Your group ID will change, of course. Add your user to this new group like this (I'm doing it as root, sudo will do the trick also):
# usermod -a -G rvm joeuser
# getent group rvm
rvm:x:983:joeuser
Yet again, the instructions above say, that this addition will NOT take effect until one of these happens:
- User logs in. If you're adding yourself, log out first.
newgrp-command is issued, newgrp(1) - Linux man page
RVM installer will add a file into /etc/profile.d/ to do some settings at login:
-rwxr-xr-x. 1 root root 1203 Nov 23 19:39 /etc/profile.d/rvm.sh
If you need to have the settings in effect, all you need to do is source it:
$ source /etc/profile.d/rvm.sh
Anyway, now the rig is ready, we only need an installed Ruby version to get the ball rolling. To get an idea what's out there, get a list of all available Rubies there are:
$ rvm list known
# MRI Rubies
[ruby-]1.8.6[-p420]
[ruby-]1.8.7[-head] # security released on head
[ruby-]1.9.1[-p431]
[ruby-]1.9.2[-p330]
[ruby-]1.9.3[-p551]
[ruby-]2.0.0[-p647]
[ruby-]2.1[.7]
[ruby-]2.2[.3]
[ruby-]2.2-head
ruby-head
I'm urging to go for the install, but my first install attempt stalled on some missing libraries. There was a prompt asking for my password, but I chose not to enter my personal password to a script. So:
# yum install libyaml-devel readline-devel libffi-devel sqlite-devel
When those landed, let's go for an install:
$ rvm install ruby-2.1.7
The installer will output a lot, some of it is:
Searching for binary rubies, this might take some time.
No binary rubies available for: fedora/20/x86_64/ruby-2.1.7.
Continuing with compilation. Please read 'rvm help mount'
to get more information on binary rubies.
Checking requirements for fedora.
Requirements installation successful.
Installing Ruby from source to: /usr/local/rvm/rubies/ruby-2.1.7,
this may take a while depending on your cpu(s)...
ruby-2.1.7 - #downloading ruby-2.1.7,
this may take a while depending on your connection...
ruby-2.1.7 - #extracting ruby-2.1.7 to /usr/local/rvm/src/ruby-2.1.7....
ruby-2.1.7 - #configuring...
ruby-2.1.7 - #post-configuration..
ruby-2.1.7 - #compiling...
ruby-2.1.7 - #installing...
ruby-2.1.7 - #making binaries executable..
ruby-2.1.7 - #downloading rubygems-2.4.8
ruby-2.1.7 - #extracting rubygems-2.4.8....
ruby-2.1.7 - #removing old rubygems.........
ruby-2.1.7 - #installing rubygems-2.4.8...
ruby-2.1.7 - #gemset created /usr/local/rvm/gems/ruby-2.1.7@global
ruby-2.1.7 - #importing gemset /usr/local/rvm/gemsets/global.gems...
ruby-2.1.7 - #generating global wrappers........
ruby-2.1.7 - #gemset created /usr/local/rvm/gems/ruby-2.1.7
ruby-2.1.7 - #importing gemsetfile /usr/local/rvm/gemsets/default.gems
evaluated to empty gem list
ruby-2.1.7 - #generating default wrappers........
ruby-2.1.7 - #adjusting #shebangs for (gem irb erb ri rdoc testrb rake).
Install of ruby-2.1.7 - #complete
Ruby was built without documentation,
to build it run: rvm docs generate-ri
But ultimately, you're good to go:
$ ruby -v
ruby 2.1.7p400 (2015-08-18 revision 51632) [x86_64-linux]
To get back to my original task, I installed a gem:
$ gem install davclient
Fetching: davclient-0.0.8.gem (100%)
Successfully installed davclient-0.0.8
Parsing documentation for davclient-0.0.8
Installing ri documentation for davclient-0.0.8
Done installing documentation for davclient after 0 seconds
1 gem installed
That's it! Everything is ready.
Apple iPhone 7 giveaway scam
Wednesday, November 18. 2015
Looks like I'm on a roll. I was home watching a movie and while at it, I got interested about an actor in it and his other work in TV. In normal situation, I'd just flip open one of my laptops, but none were at arm's reach. However, my iPad was. For any movie buff like me, the one an only definite site is Internet Movie Database, or IMDb. Their mobile site is pretty good, but I wanted to give their iOS app a go.
The Incident
I installed the app, and went to iOS Safari to google something, which I don't even remember anymore. Pretty much when I opened the Safari something really weird happened (unfortunately for most of the readers, all of this is in Finnish):
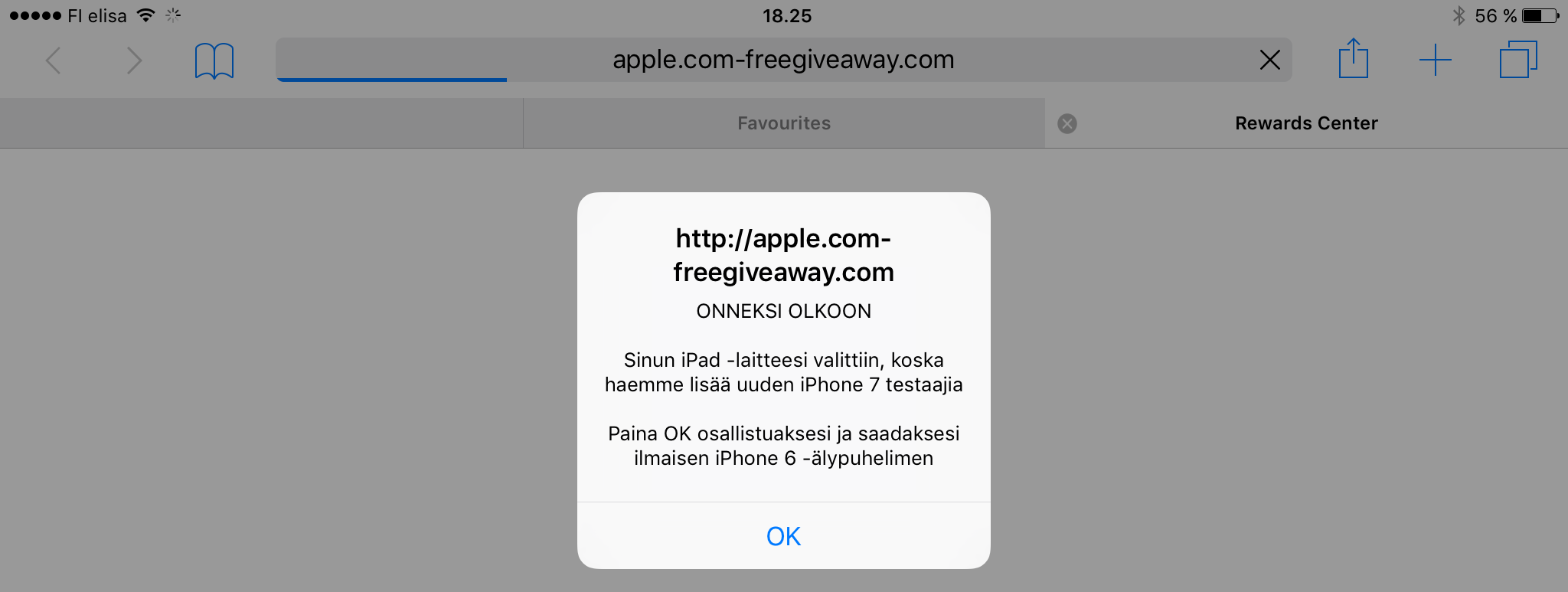
My iPad was selected out of 20 Finnish ones, to get a free iPhone 7 in 2016 when it will be released. WTF!!? For a split second, I - a seasoned software security professional, thought "wow, I'm must be really lucky!" Then the experience kicked in: "This is a scam!" At that point I started taking screenshots of everything I saw on the iPad screen.
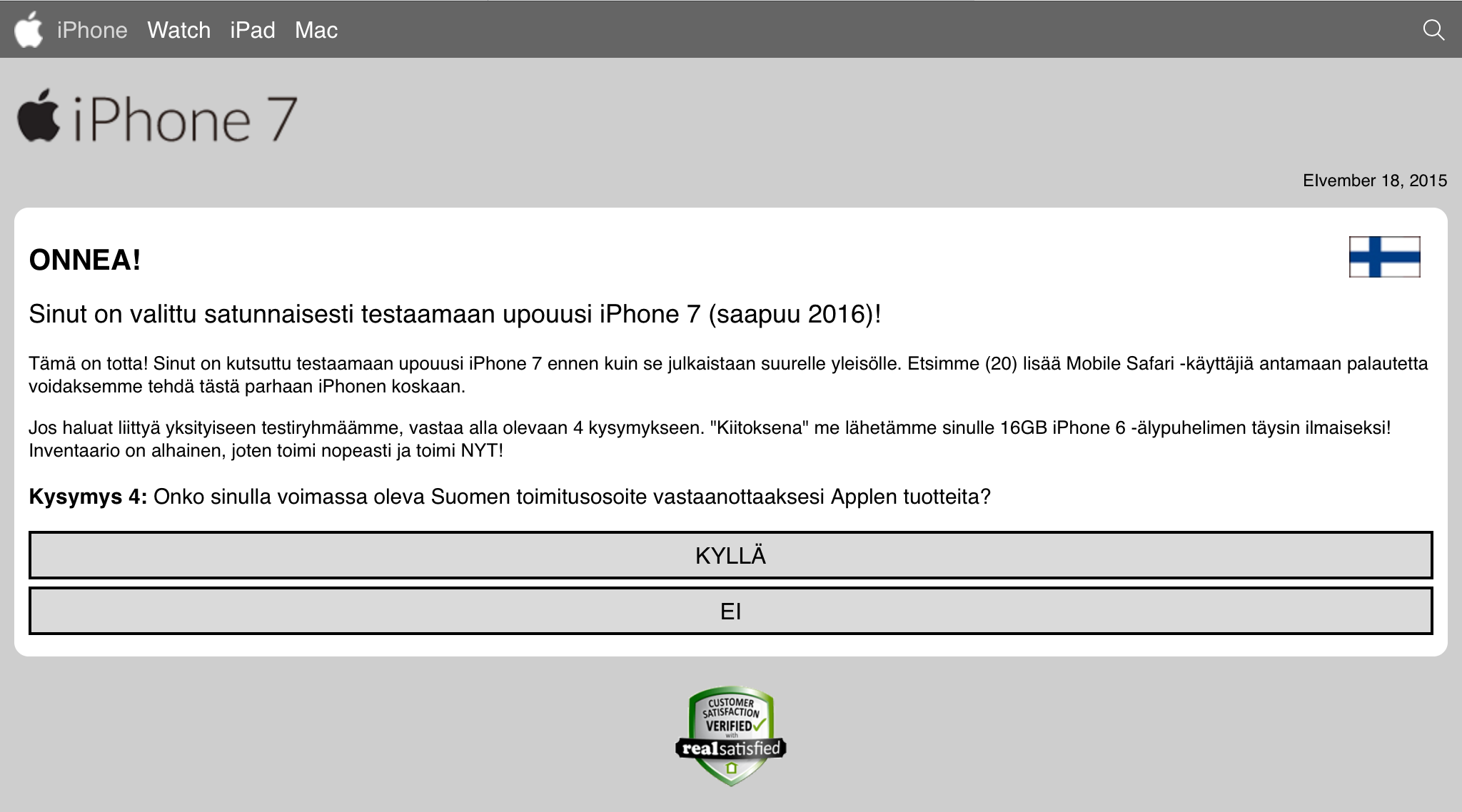
Once I got rid of the modal alert-box, there were four bogus questions of "Do you own an Apple product?" and about the future features the iPhone 7 should have and the final one about "Do you have an address in Finland which can be used to deliver your iPhone 7?":
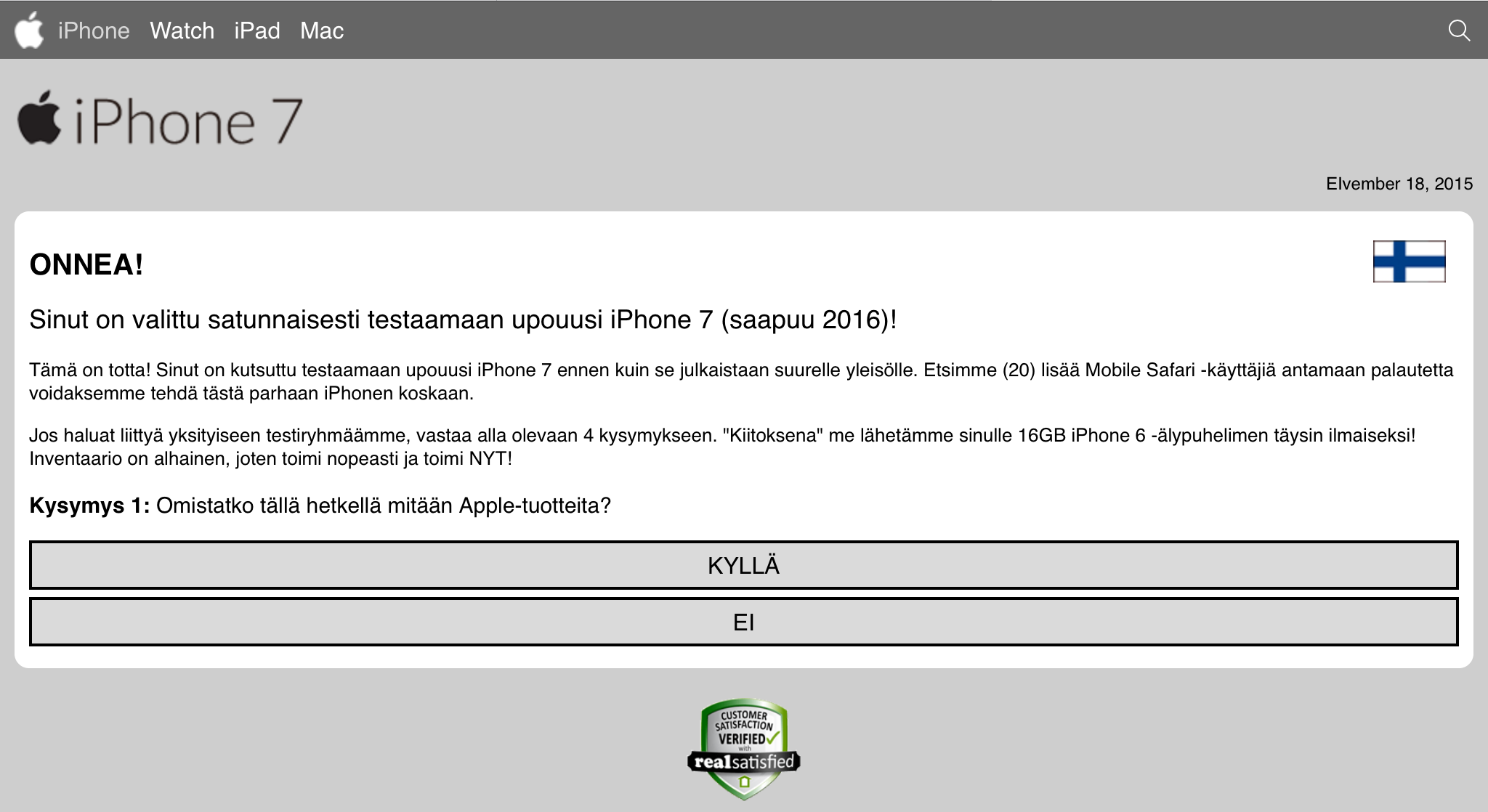
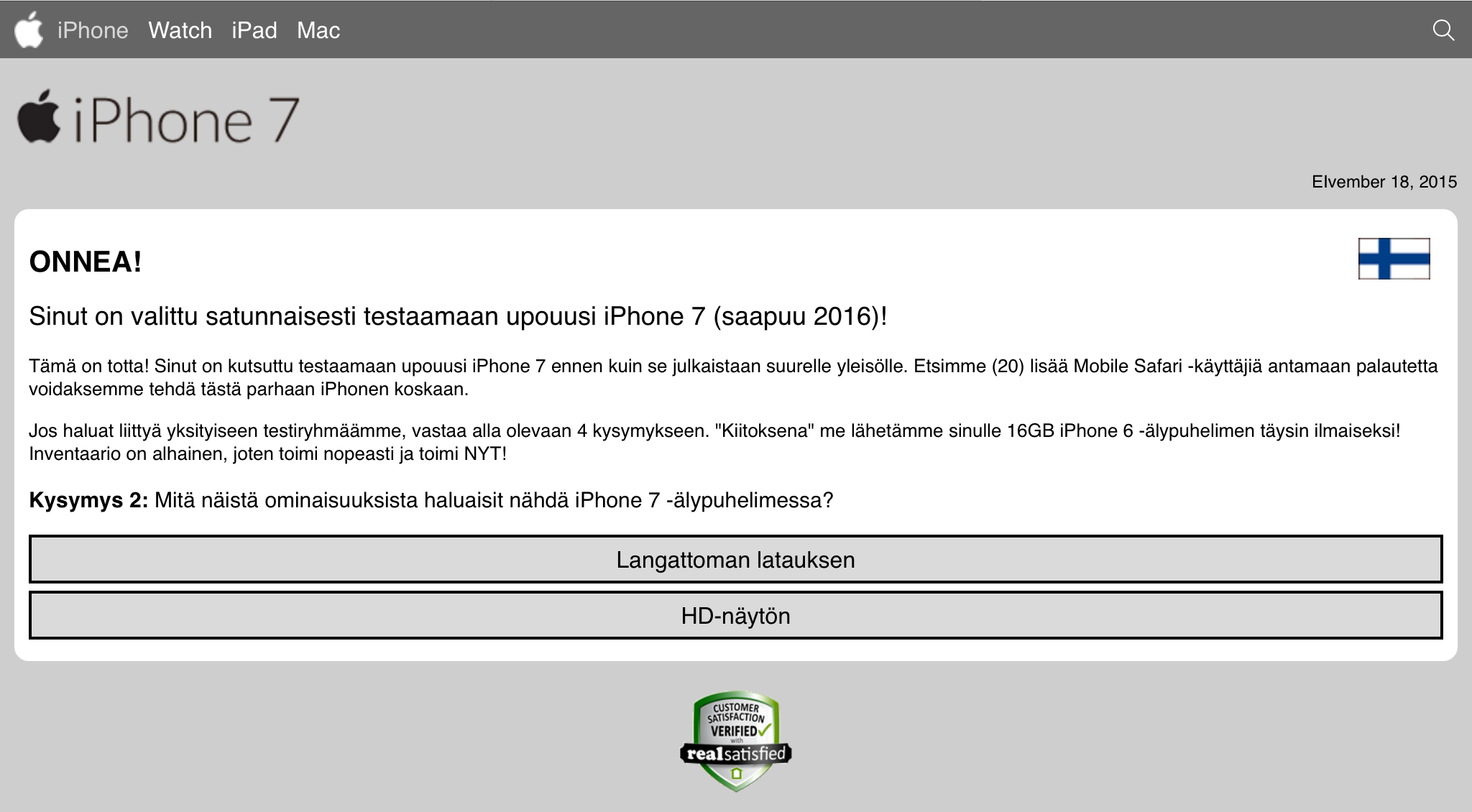
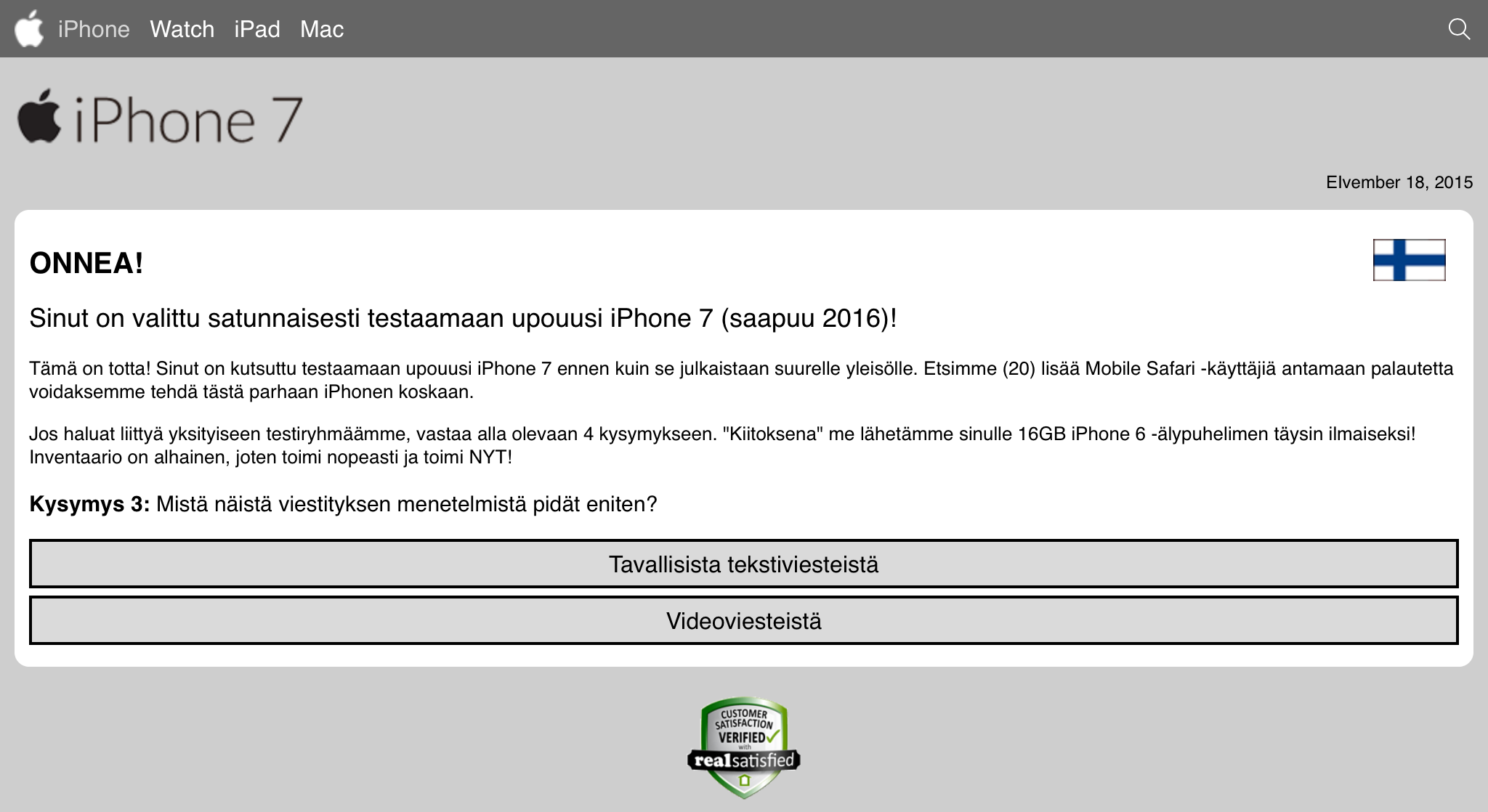
After those, there was a fake "check" for eligibility and a smooth transition to customer testimonials page:

The language was horrible all the way. Finnish is a tricky language for anybody else to master in a believable manner. For example the month name "Elvember" doesn't mean anything in Finnish.
Finally, when I clicked the large blue "yes, gimme my free gift" -button, I ended up in even weirder page asking my personal information:
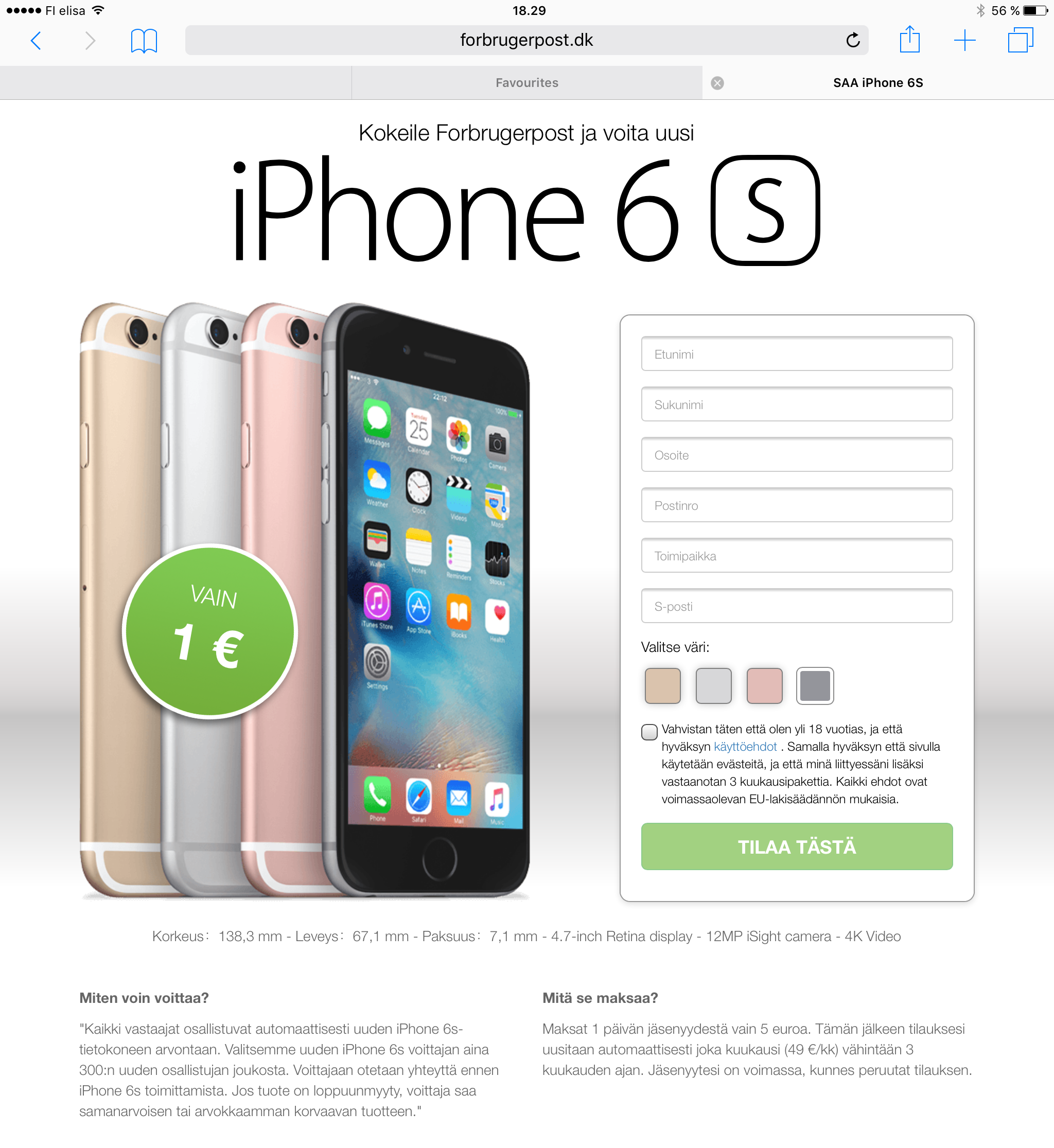
At this point I lost interest. I have no clue, that's their end game and what they would be using my information for, but I simply didn't want to even enter any fake info there.
Question 4 about address may point to some sort of smuggling scam, so that the unfortunate address would be used to send some sort of contraband which the criminals would liberate from mailbox before nobody notices. I have no proof of that happening.
The Injection
At this point, the relevant question was: What the hell happened?
Where did that page arrive into my Safari? Isn't iOS supposed to be the safest mobile OS there is? Is it really that easy to get past security? What did I do wrong to allow this to happen?
The good thing with this was that I was running in my own Wi-Fi. There I have a basic setup to keep me informed what's going on, so to the logfiles I went:
- 18.11.2015 18:22:13: App Store was started, lot of requests made to load data and graphics for it
- 18.11.2015 18:22:18: A search was made to App Store, it was me searching for "imdb"
- 18.11.2015 18:22:49: 14,801,031 bytes were downloaded from Apple's cloud, that was me downloading the IMDb app
- 18.11.2015 18:23:05: Lot of traffic into various resources to initialize the loaded app. Partial list of sites:
- http://ios-app-config.media-imdb.com/6.3.1/ipad.json.gz - iPad configuration in JSON-format from IMDb
- http://b.scorecardresearch.com/ - Market research company
- http://aax-eu.amazon-adsystem.com/ - Amazon, Inc. advertisement system, they own IMDb
- http://ia.media-imdb.com/ - Image server for IMDb
- https://api.imdbws.com - Unknown IMDb server
- https://app.imdb.com - Unknown IMDb server
- https://gsp-ssl.ls.apple.com - Unknown Apple server
- https://fls-na.amazon.com - Unknown Amazon server
- 18.11.2015 18:24:43: Safari was launched,
- http://apple.com-freegiveaway.com/sweeps/custom/fi/lp25_46ulp/ was loaded
- 18.11.2015 18:29:35: Questions were completed
- http://bit.ly1bddlxc.com/click - start of redirecting
- http://trkyad.com/ - middle point
- http://forbrugerpost.dk/campaign/iphone6s/ - personal information form
- done
IMDb app pulled in some garbage and triggered the page load into my Safari. Unbelievable!
If you want to study my movements, here is the logfile:
iPhone7scam-10-squid_access-iPad-abbreviated.log
I have omitted the IPv6 address of my iPad, it will be displayed as 2001::87b4, which is obviously not the address.
Motive and opportunity has already been explained, when it comes to means, the Objective-C code to open a page in iOS Safari from an app would be a single line:
[[UIApplication sharedApplication] openURL:[NSURL URLWithString: [@"apple.com-freegiveaway.com/sweeps/custom/fi/lp25_46ulp/"]]];
In my opinion an outside threat is not feasible, this had to be an inside job.
The Facts
A simple kick into Google search engine revealed for example Possible Iphone 7 Scam at Apple discussions. This has been going on since July 2015, at least, possibly earlier.
The page I was forced to go was http://apple.com-freegiveaway.com/sweeps/custom/fi/lp25_46ulp/
Couple of queries for the DNS and ICANN whois:
# host apple.com-freegiveaway.com
apple.com-freegiveaway.com is an alias for com-freegiveaway.com.
com-freegiveaway.com has address 54.194.31.154
com-freegiveaway.com has address 54.77.203.0
com-freegiveaway.com:
Registrant Contact
Name: Registration Private
Organization: Domains By Proxy, LLC
At the HTML-source of the freegiveaway.com-page, the redirect to the personal information form is at bit.ly1bdDlXc.com, but the actual form is at forbrugerpost.dk, a Danish domain. Querying for those:
# host bit.ly1bdDlXc.com
bit.ly1bdDlXc.com is an alias for h918i.voluumtrk2.com.
h918i.voluumtrk2.com has address 52.28.97.9
h918i.voluumtrk2.com has address 54.93.143.19
# host trkyad.com
trkyad.com has address 198.254.77.23
# host forbrugerpost.dk
forbrugerpost.dk has address 191.235.217.33
forbrugerpost.dk mail is handled by 10 mail.forbrugerpost.dk.
forbrugerpost.dk mail is handled by 100 backup-mx.zitcom.dk.
ly1bdDlXc.com:
Registrant Contact
Name: Registration Private
Organization: Domains By Proxy, LLC
trkyad.com:
Registrant Contact
Name: H Pieters
Organization: Your Product In Mind
Domain name: forbrugerpost.dk
DNS: forbrugerpost.dk
Status: Active
Created: 2007/11/07
Registrant:
Userid: FA7610-DK
Name: FORBRUGERPOST ApS
Address: Skibbrogade 3, 2.
Zipcode & City: 9000 Aalborg
Country: Danmark
Phone: +4588888484
IP-address owners:
# geoiplookup 54.194.31.154 54.77.203.0 52.28.97.9 54.93.143.19
GeoIP Country Edition: IE, Ireland
GeoIP City Edition, Rev 1: IE, 07, Dublin, Dublin, N/A, 53.333099, -6.248900, 0, 0
GeoIP ASNum Edition: AS16509 Amazon.com, Inc.
# geoiplookup 198.254.77.23
GeoIP Country Edition: US, United States
GeoIP City Edition, Rev 1: US, CA, California, Newport Beach, 92663, 33.626701, -117.931198, 803, 949
GeoIP ASNum Edition: AS19994 Rackspace Hosting
# geoiplookup 191.235.217.33
GeoIP Country Edition: IE, Ireland
GeoIP City Edition, Rev 1: IE, N/A, N/A, N/A, N/A, 53.347801, -6.259700, 0, 0
GeoIP ASNum Edition: AS8075 Microsoft Corporation
Conclusions: services are running in Ireland, Amazon and Microsoft data centers and Rackspace, California. Domains are hidden behind proxies so, that the real owners of the domains are hidden. Even the Danish one is proxy-owned. About the Dutch one registered to Rotterdam, I'm not sure, that could be a real one. They use it only for redirect, maybe because they don't want to burn that so soon.
The Outcome
For the record, I'm talking about IMDb app version 6.3.1:
And there was no way, I was letting that piece of garbage pop up any more stupid questionnaires:

... the app needed to go. I didn't trust it for a second.
As I can almost hear you screaming already: "But you didn't prove, that it was the IMDb app! All of this is merely a coincidencee".
Sure, that's true. Even with my debugging skills, looking exactly at an app and tracing it in detail would take a very long time. Which in this case I didn't do. However, my proof is in the fact, that I haven't installed any apps for weeks. My Safari didn't display that stupid questionnaire page earier that day, but after installing and running the IMDb app, it did. I'm sure nobody really knows what the app loads and executes, I have proven, that it consumes a lot of data through network.
Also, I'm not a big believeer of coincidences:
Mycroft: “Oh Sherlock. What do we say about coincidence?”
Sherlock: “The universe is rarely so lazy.”
... there really aren't any.

