Parallels Plesk Panel: Bug - DNS zone twice in DB
Sunday, February 16. 2014
Updating Metasploit with Packet Storm exploits
Saturday, February 15. 2014
For any computer security geek (like I am), Metasploit is the de facto tool to use. What especially makes Metasploit so good, that there are number of places where you can get brand new exploits to run it with. It is obvious that Packet Storm is the #1 place for your new dose of exploits to run. They release exploits in ready packages for Metasploit on monthly basis. To help people catch up in their installations, there are also yearly packages combining year's monthly updates into a single file.
Due to popularity of Metasploit and quality of Packet Storm's exploits, there are number of instructions how to do the update. I googled "upadate metasploit with packet storm exploits" and got a ton of garbage. Really?! Couple dozen YouTube-videos showing how to do it. Videos?! Really!! Apparently all of those videos are created by script-kiddies for script-kiddies. It is soooo easy to copy/paste information from a YouTube-video, or ... then again, NOT. No matter which search phrases I used, I simply could not find a sensible way of doing the updates. When you don't find the required information from the web, it must be one of these two: 1) you're wrong or 2) everybody else is wrong. My typical choice is 2), ask anybody who knows me. 
The single page with idea I found was at Mr. ljy396's blog "How to update exploits from packetstorm website". I was looking at his scripts of collecting and installing the exploits, and thought that there should be a single easy-to-use script for doing all this.
When I started writing my own script, the thought came to me again: "This is so wrong! There must be the real way of doing the updates, but I just didn't find it. It is obvious, that I'm writing an inferior duplicate thing for this." Anyway, that logic never stopped me so far. Here are the results.
The script operates in three modes:
- Do monthly updates:
updateMetasploitFromPacketStormExploits.pl --year=2014 - Download and install a specific package:
updateMetasploitFromPacketStormExploits.pl \
--package_url=http://packetstorm.interhost.co.il/1401-exploits/1401-exploits.tgz - Install an existing package:
updateMetasploitFromPacketStormExploits.pl --package_file=/tmp/1401-exploits.tgz
A Metasploit user has the "secret" $HOME/.msf4/-directory. My script adds the updates/-directory for keeping track of which monthly updates it already installed. As Metasploit requires, all of the installed exploits go to modules/. My script renames the .rb.txt-files in the packages properly during the installation. NOTE: I'm not touching the Metasploit install directory. The new updates really go to per-user directory and are not available system-wide.
Any bugs, comments and suggestions are welcome. Please drop a comment.
AMI BIOS iKVM (Asus Z8PE-D12) failing to open console redirection
Friday, February 14. 2014
I was trying to see the remote console of one of my servers:
![]()
It said: "Could not create token for this session. Max session limit might have reached". This was yet another reminder that Asus iKVM isn't the sharpest tool in the box, it generally responds slowly and sometimes it does weird things. Thanks to Java, it wasn't easy to get the console application running, it said a number of things, including a complaint:
![]()
... but after sorting out a number of Java issues it spat out an error-message with XML-content of:
<jnlp spec="1.0+" codebase="http://192.168.1.11/Java">
<information>
<title>JViewer</title>
<vendor>American Megatrends, Inc.</vendor>
<description kind="one-line">JViewer Console Redirection Application</description>
<description kind="tooltip">JViewer Console Redirection Application</description>
<description kind="short"> JViewer enables a user to view the video display of managed
server via KVM. It also enables the user to redirect his local keyboard, mouse for
managing the server remotely. </description>
</information>...
<resources>
<j2se version="1.5+"/>
<jar href="release/JViewer.jar"/>
</resources>
<application-desc>
<argument>192.168.1.11</argument>
<argument>7578</argument>
<argument>
<html>
<head>
<title>Document Error: Page not found</title>
</head>
<body>
<h2>Access Error: Page not found</h2>
<p>Could not create token for this session. Max session limit might have reached
</p>
</body>
</html>
</argument>
</application-desc>
</jnlp>
I found out somebody who had the same issue at Asus' discussion forums article [Problem]iKVM Remote Control Console w/ Java exception error. There was a suggestion to unplug the power cord. In my case the server is couple hundred kilometers away in a secure data center where I certainly do not have any access. Sure, I could write the support and ask them to do that but ... I'm pretty sure there has to be a way to reset the BMC remotely.
Then I remembered something I did a while ago with ipmitool on Linux-shell. Running:
# ipmitool bmc help
MC Commands:
reset <warm|cold>
guid
info
There is a reset-command in the list. Google led me to an article "Restarting an IBM BMC without restarting the server itself". I wasn't sure what would happen. My first guess was that it would do the same thing as typing "google" into a Google search - the entire world would implode to a singularity. So it is very important not to that. But I really needed the remote console. I was willing to try:
# ipmitool bmc reset cold
Sent cold reset command to MC
Nothing serious happened immediately. The Linux was responsive and world didn't come to an end. After a minute or so, ipmitool bmc info -command yielded a response! The IPMI was back on-line. A logon to web-console:
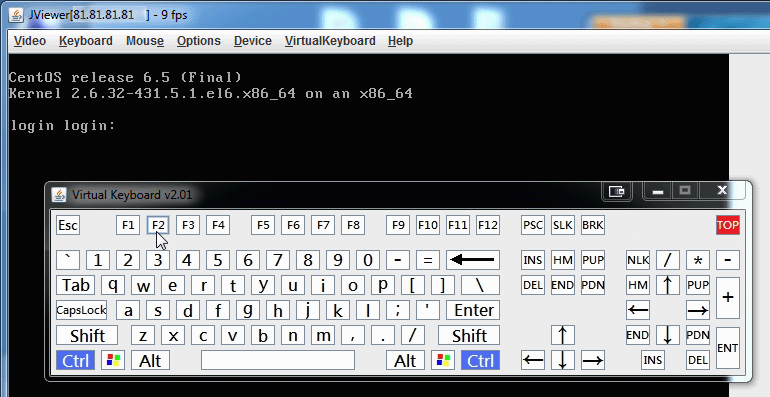
Yep. I had my console back.
I sure hope that all remote console manufacturers would stop using Java for their apps. It is such a bitch to get a Java application working on after 1.7.0_51 was released. See: "Java 7u51 will not accept JNLP with self-signed certificate?" about other people complaining about that. Anyway, all ended well and I didn't have to drive to the server to do some maintenance.
Zend Framework 2: Disable layout
Thursday, February 13. 2014
Triggering Adobe Flash Player update manually
Wednesday, February 12. 2014
Supermicro SuperServer 5015A-EHF-D525
Tuesday, February 11. 2014
I needed a new rack-server to fit in a standard 19" telco-rack. Your average rack-mounted server is 60 to 100 cm long. A rack-server may be really thin. 1U (4,5 cm) or less, but really long. Then again, your average telco rack is not long enough for a long server, they may be 40 to 50 cm and not all of them have brackets for mounting the back. My requirement of mounting a server into a telco-rack hugely limits the options to choose a server from. One final requirement I had was that the server must have IPMI 2.0, because that would guarantee KVM over IP.
But after a longish search I found one. The bad news was, that it was a Supermicro, a SuperServer 5015A-EHF-D525 to be exact. Supermicro's track-record on failing IPMI-security is known, see an earlier blog post about it. Anyway, I got a vendor from UK who would order one. They didn't have them in stock and such small rack-servers are quite inexpensive, but don't sell like hotcakes. Who would be crazy enough to want one? I am, so put an order in with the Boston Ltd. It didn't take them many weeks and I got my server delivered.
Here are the pics from front and back:
![]()
![]()
In the front there is couple of LEDs, power and reset buttons. In the back there are couple of USB 2.0 -ports and two RJ-45 for 100 Mbit/s Ethernet. It is possible to run IPMI on a shared Ethernet-port or a dedicated one. In my setup I didn't want to have the extra cable and went for a shared setup. The port announces itself as two different MAC-addresses and effectively gets two different DHCP-addresses. One for IPMI and one for the operating system.
This is what it looks inside:

Notice how the Intel SSD -drive is not attached properly yet at the time of taking the pic. The motherboard is really small. The only fan is in the PSU, no other ones are required as the Intel Atom CPU does not produce too much heat and the GPU isn't much of a rocket. The tiny box is almost empty, even with a 2.5" SSD in it.
In the BIOS I found that there is a lot of watchdogging to do, there are two of them:
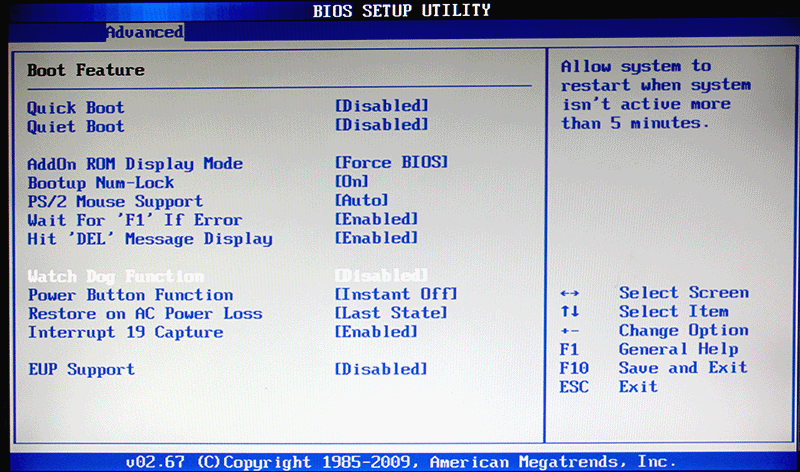
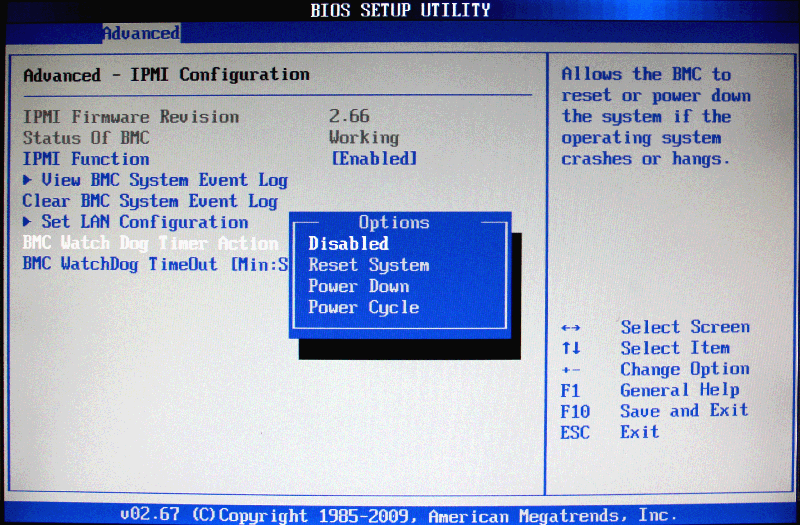
I don't know what the BIOS watchdog is good for as it keeps triggering if turned on. For the IPMI's watchdog there is a Linux-daemon.
Anyway, except the small size and 32-bit Atom CPU there is nothing special in it. 10 years ago such a server would have been a state-of-the-art box, but on today's standards its just a small low-power unit.
On the positive side, IPMI's web console has a setting for IP Access Control. I tested it and it seems to work. It closes all the ports for everybody else. Since the raw rules are not available for inspection, there still may be couple of network blocks which are allowed. These days you cannot help being suspicious.
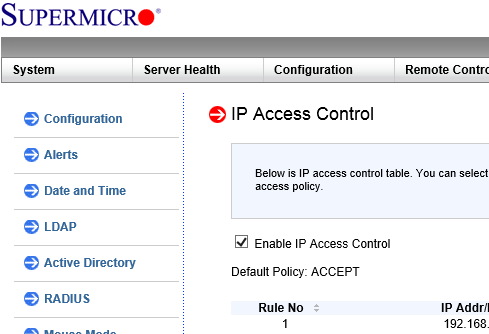
This is a special box. If you happen to need a silent low-power server, then go with a 5015A-EHF-D525.
Installing OpenSuse 13.1 into a MacBook
Monday, February 10. 2014
OpenSuse 13.1 was released November 2013. During Christmas holidays I started a project of upgrading my previous installation.
Since I'm running on a MacBook 1,1 it was obvious that I was looking for trouble. Previously I had rEFIt running just to get a GRUB 2 -prompt. This time I decided to start from a clean slate. Literally. I ran
dd if=/dev/zero of=/dev/sda
for the 10 first MiB of the drive to make sure, that it definitely has no trace of any of my previous settings. Since rEFIt has been abandoned years ago, I went for the replacement project rEFInd. I approached the author Mr. Roderick W. Smith and he was very helpful, but no matter what I did, I could not get rEFInd running on my very old 32-bit Mac. So, I had two options left: to go back to abandonware or see what would happen without a Boot Manager.
I failed on the installer settings-dialog, by trying to out-smart OpenSuse logic. My completed installation didn't boot. On 2nd try I simply went with the flow. As Mr. Smith instructed me, I didn't touch the most critical thing: MBR is not the way to go on a Mac! Here are my settings:
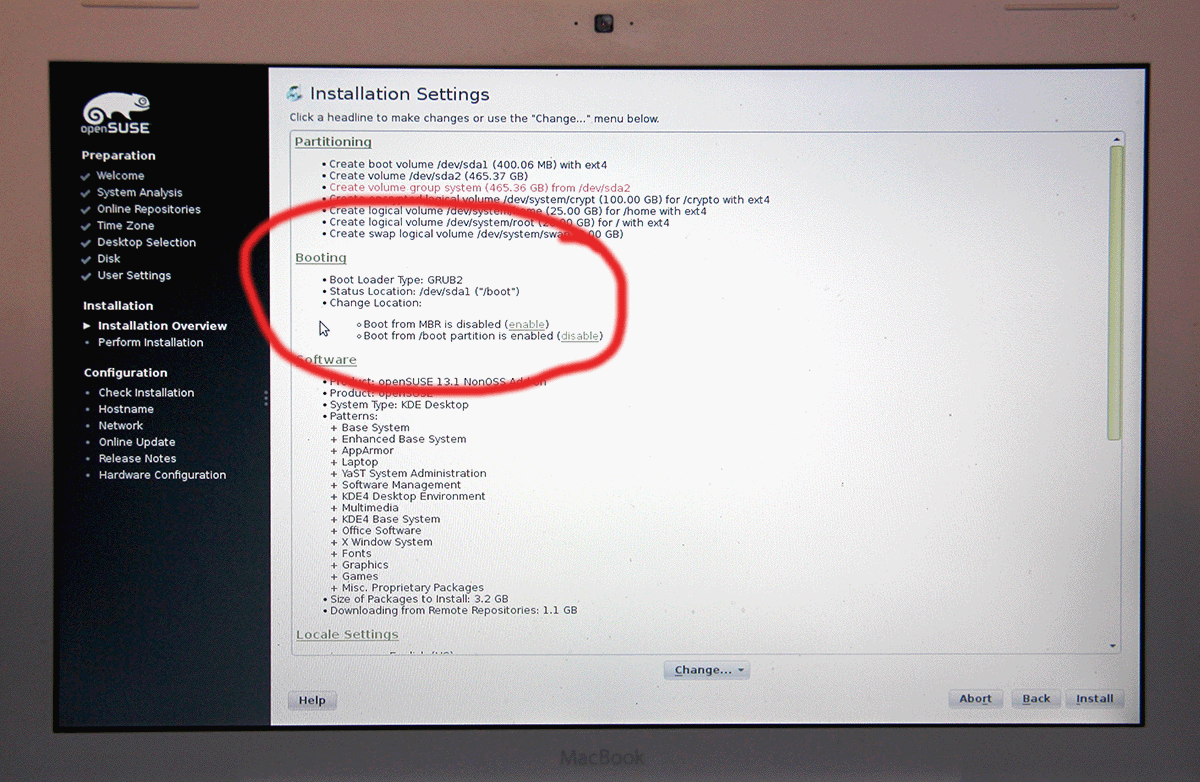
And guess what, it worked! OpenSuse 13.1 installer has enough logic to create a bootable Linux-installation to a completely blank hard drive. Nice!
The installer was pretty smart. Wi-Fi network was configured properly, it worked out-of-the-box. Apple-keys work: screen brightness, volume, etc. work as is. Also the typical trouble-makers sleep (on RAM) / hibernate (to disk), battery info, sound, and what not. There were only two minor issues: iSight does not work without the Apple proprietary firmware and the keyboard Apple-keys don't do anything usable.
To get the iSight camera working, see ift-extract -tool at Apple Built-in iSight Firmware Tools for Linux. It can dig the guts out of Mac OS X iSight-driver and equip your Linux with a functioning camera. The keyboard is a trivial one. Like previously, I just keyfuzz'ed the keys into something useful. See the OpenSuse 12.3 installation blog entry for details.
There is one thing you may want to check. If you enable SSHd, like I always do on all servers. As default /etc/sysconfig/SuSEfirewall2.d/services/sshd defines as TCP/22 to be open. That is the general idea, but apparently there is so much SSHd bombing going on, that I always tar pit my installations. For some strange reason Suse engineers chose not to allow that in a specific service definition file, but it has to be in the classic /etc/sysconfig/SuSEfirewall2 file, section FW_SERVICES_ACCEPT_EXT="0/0,tcp,22,,hitcount=3,blockseconds=60,recentname=ssh"
I urge everyone of you to rename the services/sshd into something else and add the above line. This makes bombing your SSH-port so much more difficult. And it does not affect your own login performance, unless you choose to bomb it yourself.
You may want to check OpenSuse's hardware compatibility list for details about Apple Laptops. The HCL has info about what works and what doesn't.
In general OpenSuse folks did a very good job with this one. There was a real improvement on ease installation. Thanks Roderick W. Smith for his help during my installation and thanks to Novell for giving this great distro for free!
Huawei E3276 reviewed
Sunday, February 9. 2014
I got my hands on Huawei E3276. It is a 4G LTE USB-stick. The model I tested appears to be a model s-150. According to 4GLTEmall.com it has following frequencies available in FDD: 800 MHz, 900 MHz, 1800 MHz, 2100 MHz and 2600 MHz. The newer 4G modulation of TDD is not available.
It looks like this:


On the side there is a slot for MicroSD-card and a standard CRC9-connector which Huawei is using for all of its USB-products. See this vid (with cheesy music) to see an external antenna connected to a Huawei. The pics:


You open the stick by sliding the white cover to left. Then you can insert a mini SIM-card (in my pic there is a micro-SIM to mini-SIM adapter sleeve):



In general it resembles your average Huawei 3G-stick a lot, the only difference is that it is little bit wider. I still remember how big a Huawei E220 felt when the 2nd gen 3G-sticks (E160/E169/etc.) came. As you would expect, when the USB-stick is inserted, it appears as a CD-drive with the classic Huawei Mobile Partner setup in the "disc". After you install the drivers and the software, there is pretty much no way of telling that you are not running on a 3G but a 4G. The mobile partner has features to lock it into LTE-mode and it indicates the connection type of 3G WCDMA, 3G DC and LTE properly.
This is how it looks like on a side of a Lenovo Ideapad S10:


Generally I was pretty pleased with the stick. It is clearly an evolution version of a 3G stick. The feeling is that it is a 3G on steroids. The antenna is very sensitive and my testing revealed that it keeps the connection open even if there is zero bars of reception. However, it is quite expensive currently. In Finland you can get one from a telco with 99,- € with a contract. The unlocked ones are around 150,- €.
It worked on Windows 7 without problems, but as a Linux-man I had to try and see if it works. Unfortunately there are issues with that. Linux recognizes the stick as a Huawei E352 3G-stick, does the modeswitch from storage mode to modem mode properly and a /dev/ttyUSB0 appears, but it does not connect to The Net. A short minicom session indicated, that the modem is there and is receving commands:
atz
OK
ati
Manufacturer: huawei
Model: E3276
Revision: 21.192.05.00.00
IMEI: 863781010000000
+GCAP: +CGSM,+DS,+ES
OK
It seems to have a new Type Allocation Code code of 86378101 for Huawei. Not all databases have that yet.
The Linux chatter in The Net is that 4g-connect-linux -script should be able to make a connection. I tried it with varying parameters, but somehow the new wwan0-interface didn't have a proper device attached into it and all I got was ioctl SIOCGIFHWADDR: No such device -errors. Search for "cdc_ncm e3276" to get a number of posts about that.
I also did some ping-testing on 3G Dual-Carrier versus 4G LTE. The bandwidth is really a no contest, LTE will win that one hands down as 3G DC has a theoretical cap on 42 Mbit/s. That's pretty much the point where LTE starts! My measurements also confirmed that. A 50 Mbit/s connection limit imposed by the telco measures 69 Mbit/s in reality. Not bad, huh!
Anyway, a simple ping-test says:
- Forced 3G DC: Minimum = 31ms, Maximum = 1217ms, Average = 66ms
- Forced LTE: Minimum = 24ms, Maximum = 460ms, Average = 35ms (Winner!)
The fluctuation in a mobile connection is there. When something happens in the air, there will be delays and retransmissions. But when conditions are nearing optimal, on LTE it is difficult to differentiate mobile connection from a wired one. That's the reason I'm so thrilled about LTE availability. 3G is ok for surfing the web, but LTE is the first mobile technology that really performs!
Final words:
The Huawei E3276 is definitely a keeper. Now that Finnish telcos have an agreement about the 800 MHz 4G usage, they are investing heavily on their LTE-networks. Even pre-paid data has 4G on some telcos. The stick does not replace my B593 which is meant for non-mobile usage, but for a laptop I'll be definitely keep using this one.
Led Lenser K2 vs. MagLite Solitaire LED
Saturday, February 8. 2014
A while ago I a friend send a link to Jamie and Adam Tested -YouTube channel. I'm a fan of Mythbusters, so he knew that I'd love their stuff. One of the videos they have there is Inside Adam Savage's Cave: Hacking a Flashlight for Adam's EDC. So, I felt that I should blog about flashlights too.
Last year my old and trustworthy MagLite Solitaire broke down after serving me well for 18 years and I had to get a replacement. My old Solitare became un-fixable due to some sort of stress in the inside plastic parts. They broke down to a number of new pieces that didn't fit anymore. Apparently my key chain with number of keys in it cause stress to a flashlight's guts.
In the above video Adam is doing a hack to his JETBeam. Me as a Leatherman man I went for a Led Lenser (apprently they are owned by same company). Model K2 to be specific. However it turned to be a mistake. The LED is bright, it really is, and the flashlight is really tiny, but its aluminum body is not built to be hung in a key chain and stuffed into a pocket over and over again. It broke after 8 months of "usage". Actually I didn't use the lamp that much, but ... It broke. Aow come on! My previous lamp lasted for 18 years!
Here is a pic of the broken Led Lenser K2 (the short one) next to my new flashlight:

Thankfully my favorite flashlight company is back! I don't know what MagLite did for 15 years or so, but they certainly lost the market leader position by not releasing any new products for a very, very long time. So... after failing with Led Lenser I went back to MagLite. Their new LED-products are really good and I got one of their new releases a Solitaire LED. I'm hoping it lasts a minimum of 18 years!
Advanced mod_rewrite: FastCGI Ruby on Rails /w HTTPS
Friday, February 7. 2014
Huawei B593: Forcing 4G LTE mode
Thursday, February 6. 2014
First I'd like to apologize. At least twice I've said that it is impossible to force B593 to stay out of 3G-mode and force it to stay on 4G LTE. That is not true. It is an incorrect statement by me and I'm sorry that I didn't investigate the facts before making such statements.
Here is a (slightly photoshopped) screenshot of my own device:
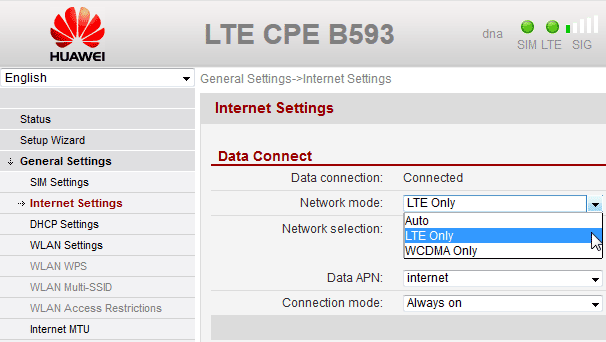
There actually is such an option in General Settings --> Internet Settings --> Network mode. And you can select LTE Only and it will work as expected.
For device hackers, the /var/curcfg.xml will have the setting:
<?xml version="1.0" ?>
<InternetGatewayDeviceConfig>
<InternetGatewayDevice>
<WANDevice NumberOfInstances="3">
<WANDeviceInstance InstanceID="2">
<WANConnectionDevice NumberOfInstances="1">
<WANConnectionDeviceInstance InstanceID="1">
<WANIPConnection NumberOfInstances="2">
<WANIPConnectionInstance InstanceID="1"
X_NetworkPriority="LTE Only"
Valid options for X_NetworkPriority "AUTO", "WCDMA Only" and "LTE Only".
After changing the setting my connection has been more stable than ever (on Danish 3's firmware). There has been occasions where my connection has dropped to 2.5G, see the blog post about it, but after fixing the LTE-only -mode things changed to most robust ever.
SplashID wasted my entire password database
Wednesday, February 5. 2014
I've been using SplashID as my password solution. See my earlier post about that. Today I tried to log in into the application to retrieve a password, but it turned out my user account was changed into null. Well... that's not reassuring. 
After the initial shock I filed a support ticket to them, but I'm not expecting any miracles. The database has been lost in my bookkeeping. The next thing I did was checked my trustworthy(?) Acronis True Image backups. I had them running on daily rotation and this turned out to be the first time I actually needed it for a real situation.
They hid the "Restore files and directories" -option well. My laptop is configured to run backups for the entire disk, so the default recover-option is to restore the entire disk. In this case that seems a bit overkill. But in the gear-icon, there actually is such an option. After discovering the option (it took me a while reading the helps), the recover was user friendly and intuitive enough. I chose to restore yesterday's backup to the original location. The recover went fine, but SplashID database was flawed on that point. I simply restored two days old backup and that seemed to be an intact one.
Luckily I don't recall any additions or changes to my passwords during the last two days. It looks like I walked away with this incident without harm.
Update 7th Feb 2014:
I got a reply to my support ticket. What SplashData is saying, that the password database is lost due to a bug (actually they didn't use that word, but they cannot fool me). The bug has been fixed in later version of SplashID. Luckily I had a backup to restore from. IMHO the software should have better notification about new versions.
Managing PostgreSQL 8.x permissions to limit application user's access
Wednesday, February 5. 2014
I was working with a legacy project with PostgreSQL 8 installation. A typical software developer simply does not care about DBA enough to think more than once about the permissions setup. The thinking is that for the purpose of writing lines of working code which executes really nice SQL-queries a user with lots of power in its sleeves is a good thing. This is something I bump into a lot. It would be a nice eye-opener if every coder would had to investigate a server which has been cracked into once or twice in the early programming career. I'm sure that would improve the quality of code and improve security thinking.
Anyway, the logic for ignoring security is ok for a development box, given the scenario that it is pretty much inaccessible outside the development team. When going to production things always get more complicated. I have witnessed production boxes which are running applications that have been configured to access DB with Admin-permissions. That happens in an environment where any decent programmer/DBA can spot out a number of other ignored things. Thinking about security is both far above the pay-grade and the skill envelope your regular coder possesses.
In an attempt to do things the-right-way(tm), it is a really good idea to create a specific user for accessing the DB. Even better idea is to limit the permissions so, that application user cannot run the classic "; DROP TABLE users; -- " because lacking the permission to drop tables. We still remember Exploits of a Mom, right?
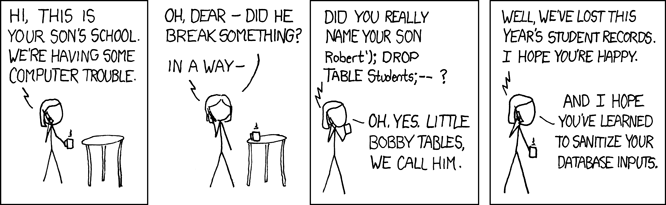
Image courtesy of xkcd.com.
Back to reality... I was on a production PostgreSQL and evaluated the situation. Database has owner of postgres, schema public had owner of postgres, but all the tables, sequences and views where owned by the application user. So any exploit would allow the application user to drop all tables. Not cool, huh!
To solve this three things are needed: first, owner of the entire schema must be postgres. Second, the application user needs only to have enough permission for CRUD-operations, nothing more. And third, the schema must not allow users to create new items on it. As default everybody can create new tables and sequences, but if somebody really pops your box and can run anything on your DB, creating new items (besides temporary tables) is not a good thing.
On a PostgreSQL 8 something of a trickery is needed. Version 9.0 introduced us the "GRANT ... ALL TABLES IN SCHEMA", but I didn't have that at my disposal. To get around the entire thing I created two SQL-queries which were crafted to output SQL-queries. I could simply copy/paste the output and run it in pgAdmin III query-window. Nice!
The first query to gather all tables and sequences and change the owner to postgres:
SELECT 'ALTER TABLE ' || table_schema || '.' || table_name ||' OWNER TO postgres;'
FROM information_schema.tables
WHERE
table_type = 'BASE TABLE' and
table_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'ALTER SEQUENCE ' || sequence_schema || '.' || sequence_name ||' OWNER TO postgres;'
FROM information_schema.sequences
WHERE
sequence_schema NOT IN ('pg_catalog', 'information_schema')
It will output something like this:
ALTER TABLE public.phones OWNER TO postgres;
ALTER SEQUENCE public.user_id_seq OWNER TO postgres;
I ran those, and owner was changed.
NOTE: that effectively locked the application user out of DB completely.
So it was time to restore access. This is the query to gather information about all tables, views, sequences and functions:
SELECT 'GRANT ALL ON ' || table_schema || '.' || table_name ||' TO my_group;'
FROM information_schema.tables
WHERE
table_type = 'BASE TABLE' and
table_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'GRANT ALL ON ' || table_schema || '.' || table_name ||' TO my_group;'
FROM information_schema.views
WHERE
table_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'GRANT ALL ON SEQUENCE ' || sequence_schema || '.' || sequence_name ||' TO my_group;'
FROM information_schema.sequences
WHERE
sequence_schema NOT IN ('pg_catalog', 'information_schema')
UNION
SELECT 'GRANT ALL ON FUNCTION ' || nspname || '.' || proname || '(' || pg_get_function_arguments(p.oid) || ') TO my_group;'
FROM pg_catalog.pg_proc p
INNER JOIN pg_catalog.pg_namespace n ON pronamespace = n.oid
WHERE
nspname = 'public'
It will output something like this:
GRANT ALL ON public.phones TO my_user;
GRANT ALL ON SEQUENCE public.user_id_seq TO my_user;
NOTE: you need to find/replace my_user to something that fits your needs.
Now the application was again running smoothly, but with reduced permission in effect. The problem with all this is that TRUNCATE-clause (or DELETE FROM -tablename-) are still working. To get the maximum out of enhanced security, some classification of data would be needed. But the client wasn't ready to do that (yet).
The third thing is to limit schema permissions so that only usage is allowed for the general public:
REVOKE ALL ON SCHEMA public FROM public;
GRANT USAGE ON SCHEMA public TO public;
Now only postgres can create new things there.
All there is to do at this point is to test the appliation. There should be errors for DB-access if something went wrong.


{kind=link}