Replacing iPhone 4S battery
Thursday, July 17. 2014
I really don't understand why people complain about iPhone screen size being too small. Personally I'd rather carry a phone, not iPad. Also it happens that iPhone 4S is one of the best phones Apple ever manufactured, it is robust and take mis-handing, it is stable and never crashes on iOS 7. You cannot say that about previous or later phones. And IMHO the best feature about 4S is that it simply has the correct size!
My unit started showing symptoms of aging. Battery charge time was over 3 hours from 20% capacity to full, which felt like much longer time when my phone was new. I'm using Battery Doctor app to monitor the charging to keep my battery in a good shape, but the fact of life is that batteries wear on usage. It was time for me to replace it.
Going to an authorized Apple service was absolutely ouf of the question. I've always wanted to see what's inside my iPhone!  The absolutely best thing is to get the new battery and tools for the service from iFixit.com. They even provide a very nice guide for the replacement job iPhone 4S Battery Replacement. As the obligatory warning part I'll simply say, that there are very small parts inside and provide this pic as proof:
The absolutely best thing is to get the new battery and tools for the service from iFixit.com. They even provide a very nice guide for the replacement job iPhone 4S Battery Replacement. As the obligatory warning part I'll simply say, that there are very small parts inside and provide this pic as proof:
That's set of iPhone screws on an euro 1 cent, which is on top of US quarter. The leftmost two screws are Phillips-head battery connector screws and the rightmost screws are original Apple Pentalobes. This should scare you away from ever attempting to do any of this stuff by yourself. If it doesn't, please read forward!
So, I put in my order and in a couple of weeks the box arrived from USA. The box contained:


- The replacement battery
- Phillips-head screwdriver to remove the battery connector and insert the liberator screws for the back lid
- Pentalobe-head screwdriver to remove the back lid
- Plastic tool for prying the battery loose from the sticky stuff it is fitted into
The first task is to remove the back lid. It can be done by removing the two Pentalobe-screws next to the bottom dock connector:![]()
After the screws are removed, the back lid will slide bit upwards, that is away from the dock connector:
After that the lid should be loose and can be removed without applying force to it. It has some tricky plastic tabs on the sides, so please be careful with those. They're the ones actually holding the lid in place. Don't break them.
The guts of the phone look like this:
Next step is to remove the battery. This can be done by disconnecting the battery from the phone and then prying the battery loose from the glue. The battery connector looks like this:
It is mechanically not a tight one. First remove the two Phillips-head screws and the try to disconnect the connector pins by sliding the connector towards the battery, like this:
Warning: when the battery connector is loose, it is absolutely certain that you will remove a pressure connector in the process:
iFixit says "Pay attention to the pressure contact underneath the top screw of the battery connector. This may come loose while prying the battery connector from its socket". I already said: It will come loose! Just don't misplace it. Try to figure out how it was, to get it back in place.
Then pry the battery:
It is held in place by reasonable amount of gooey sticky stuff:
Now you have removed the battery! It is another story of getting it all back.
The battery looks like this:
Batteries from left to right: old backside, new backside, old front side, new front
Not much of a difference with the old and the new one. Based on the LMG 08/2013, my new one is manufactured about a year ago. It had 40% charge when I turned my phone back on, I guess that's ok.
Anyway, to put it back together, put the battery in it's slot and try to figure out how the connector cable goes so that it would be possible to put the connector screws back. Before actually placing the battery contactor, concentrate on the loose pressure connector. It should look like this:
Then put the battery connector and try to put the top screw in so, that it would hold both the battery and pressure connectors in place. Then put the bottom screw in. When done correctly it should look like this:
Then the last step is to put the back lid in, slide it to place and liberate your iPhone with the new Phillips-head screws:
After that you're done. Congratulations on your new battery!
When I first turned my phone back on, it didn't find my SIM-card. I don't know what happened, but everything else worked, except it never asked for my SIM PIN-code, nor ever found any telephone operators. I fixed the issue by shutting the phone, going to airplane mode didn't do the trick. On next power on, it did ask for my SIM PIN-code and found my telco quite soon.
My thanks goes to iFixit for their excellent guide. I simply wanted to do my own to fill in the gaps they left.
Huawei B593 u-12 firmware spreadsheet
Tuesday, July 15. 2014
Firefox untrusted certificate fail
Wednesday, July 2. 2014
Something changed in Firefox 30. Once in a while everybody runs into an untrusted certificate while browsing. There is a support article "This Connection is Untrusted" error message appears - What to do at Mozilla's support site. The idea is to click I Understand the Risks and proceed to the site.
Now the latest version chose not to display the button:
If the HTTPS-connection would fail miserably, it wouldn't display the option anyways, as there isn't any possibility to continue to the site. Here is an example:
But since this is not that case, the button should be there. Something changed, since it was there before. Googling gave me an about:config variable of browser.xul.error_pages.expert_bad_cert:![]()
It had been turned into false for some reason. When the setting is true, the error screen changes:![]()
Now there is an option to proceed. While at it, they failed. Adding an exception won't work: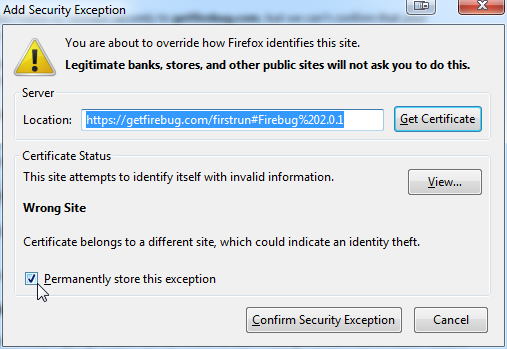
Storing the option permanently or not has no effect. It still won't proceed.
Perhaps they'll fix this into Firefox 31.
US travel pics: San Francisco
Saturday, June 28. 2014
Not much has happened here on the blog as I have been busy doing some training and planning abroad.
As the saying goes, "pics or it didn't happen!". Here are the pics:




My hotel is in Nob Hill, but for work I go to SoMa. I didn't have a chance to go to Alcatraz, as the queue is something in the region of 3 months, but I managed to take a nice picture of it from Russian Hill. I don't have the classic Golden Gate picture yet, as it would require renting a car. On the other hand, the Bay Bridge is easily visible throughout the city, including Washington Street where I took the picture of Cable Car Museum. The Also, we had a nice evening get-together and went to see Giants vs. Reds baseball game at AT&T Park. Giants lost 1-3.
Once I get back to home, I'll continue hacking the B593.
Update 2nd July:
I got back home and here are some more pics:

There are the classic Golden Gate pics you'd expect from anybody who visited San Francisco.
During the last day I had time to do a little pilgrimage:



University of California, Berkeley is the place where BSD Unix was initially written from AT&T's Unix. Nowadays that code runs among other OS X and iOS and most TCP/IP implementations, like the one in your Windows. So, it is a mighty important place. Second pic is a composite from Apple HQ's Apple Store. Every programmer will get the "infinite loop" joke. Since Infinite Loop is a looping street, you can actually take as many loops you want (until security throws you out). Third one is a composite from Google's HQ. There are number of Google bikes for employees to use (not that there wasn't security present when I drove one, typically there are). The last one is from YouTube HQ. It was surprising that it still has an own place and is not embedded into Google Campus.
Btw. In general the pics are of somewhat poor quality. I took them with my iPhone 4S. I didn't want to take my DSLR to a business trip.
Setting Cyberfox as the default browser
Thursday, June 19. 2014
Making the choice of a default browser in Windows 7 should be an easy task, right? If you are a fan of 64-bit Firefox browser like I do, then you should consider Cyberfox. The problem is, that ever since Cyberfox stopped using Firefox user profiles, it fails to set itself as the default browser.
Every single time you start your beloved Cyberfox, it will do something like this: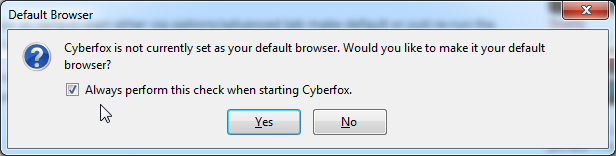
No matter what you try, it will do the same thing every single time.  Crap!
Crap!
The good thing is that this particular issue is a common one. It has been discussed in [Error] Problems Setting As Default Browser and [Solved] Cyberfox 28.0.1 Not the Default Browser bug, which contains enough information to solve the problem. The information is in the cracks of the discussion thread, but I managed to scavenge enough to fix my browser.
Start the fix by setting something else as the default browser:![]()
Confirm, that Cyberfox should be the default browser, but it just doesn't work: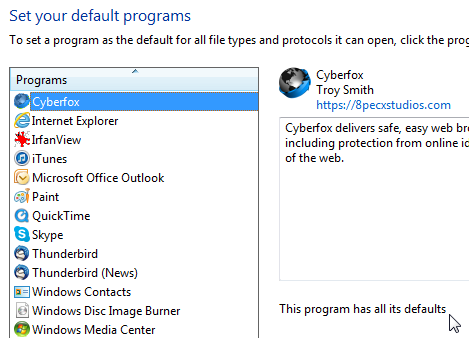
I'm setting IE as the default browser for the time being. Later I'll switch back to Cyberfox, but the fix requires you to change into something else: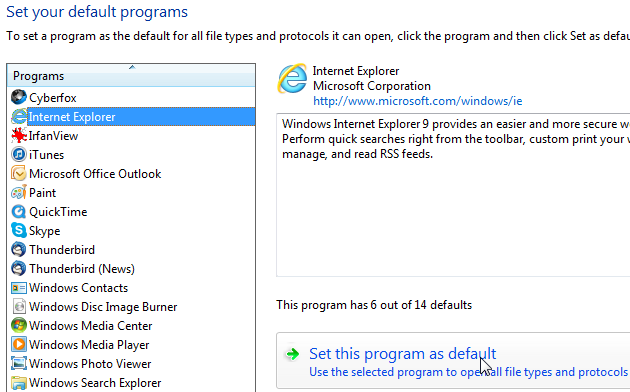
Next, go to Cyberfox and go to Options, Advanced, General settings and un-check the Always check to see if Cyberfox is the default browser on startup. Later you need to be able to start Cyberfox without the check: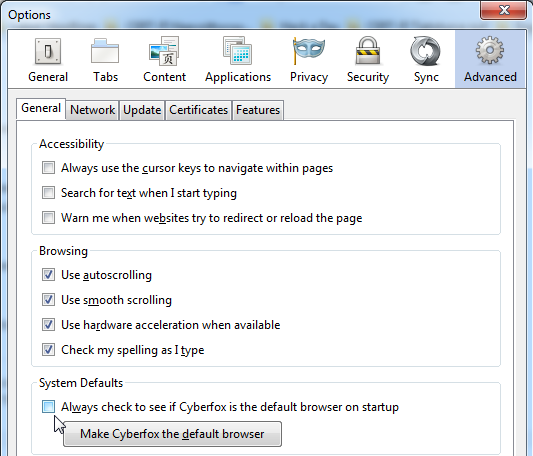
Download (or copy/paste) a small registry file defaults-64.reg. The entire file will be 7 lines (2 blank ones):
Windows Registry Editor Version 5.00
[-HKEY_LOCAL_MACHINE\SOFTWARE\Clients\StartMenuInternet\CYBERFOX.EXE]
[-HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Clients\StartMenuInternet\CYBERFOX.EXE][-HKEY_LOCAL_MACHINE\SOFTWARE\Clients\StartMenuInternet\FIREFOX.EXE]
[-HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Clients\StartMenuInternet\FIREFOX.EXE]
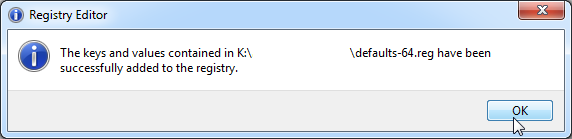
When you have the file in your disc, start File Explorer and right click the file:![]()
Select Merge. It should say something like this (The keys and values successfully added to the registry):![]()
Next thing is to start Cyberfox with administrator permissions. This is very important. If you attempt the fix with regular user permissions, you will fail and need to start over. Example:![]()
Go to Options, Advanced, General settings again: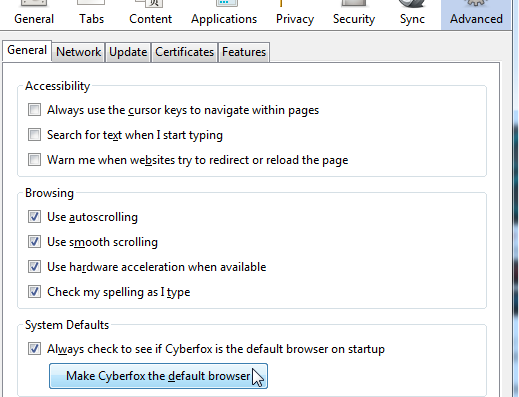
This time click the Make Cyberfox the default browser (you can check Always check to see if Cyberfox is the default browser on startup, if you want to). This time the button will disappear: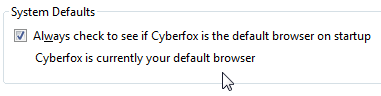
If the button disappears, it means that you succeeded! Cyberfox is the default browser for your Windows and it won't complain about it on startup.
All this trouble pays off. Now your super efficient and well optimizer browser works even better!
The obligatory shame-on-you prize goes out to Mozilla for scrapping their 64-bit Windows browser project. Even Google Chrome is heading towards 64-bit on Windows. Anyway, the 64-bitness is a weird subject, on Linux or Mac OS X 64-bit browsers have existed a very long time. What's with the Windows having only 32-bit versions?
Lenovo WWAN (Gobi 2000) for Windows 8
Wednesday, June 18. 2014
This is a part 2 of my Lenovo on Windows 8 series. See the part about energy management.
After installing Windows 8 there was a mobile broadband device, but funnily enough it was locked to Verizon Wireless. What Verizon? I live in Finland! There is no Verizon to the next 8000 km. On status the Verizon displays as unnamed. However, on my Windows 7 it did use it with a pre-paid SIM-card and it did work properly. See:
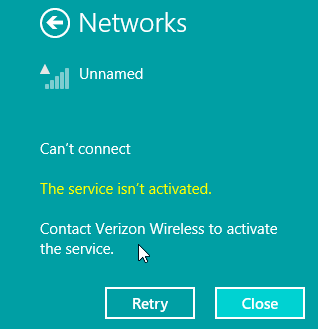
To fix this I went to check ThinkVantage Technologies downloads @ Lenovo, but for Windows 8 there is no Access Connections, or anything even remotely usable. Next I checked Windows 8 instructions Use mobile broadband to connect to the Internet @ Microsoft, but this information is relevant or usable only if the broadband modem is not locked to the goddam Verizon.
The exact modem make and model can be found out:
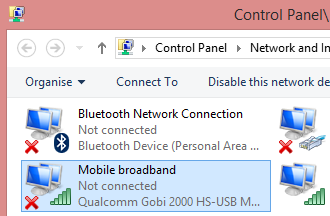
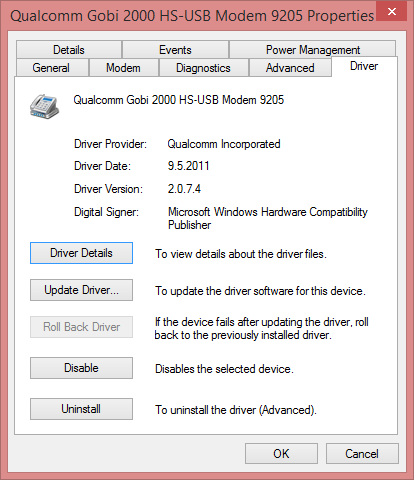
In Thinkpad L512 it is a Qualcomm Gobi 2000. Searching for information revealed Qualcomm Gobi 2000 page @ thinkwiki, a page dedicated to documenting Thinkpads running Linux. It has information in it about various firmwares for that modem. Searching for the firmware information turned out to be very successful, there is lot of good information at Gobi 2000 on Windows 8 (Thinkpad) and Gobi 2000 WAN Unlock Solution - tested & works new Z win7 64bit Pro.
The key to success is a Sony Vaio utility called OneClick Internet.
Update Feb 2021:
Given deprecation of Vaio models and Windows 7 and 8, the tool is not available anymore. I think https://www.sony.co.uk/electronics/support/downloads/Z0003894 might be it, but as I don't own suitable hardware anymore, I cannot verify.
Obsoleted setup instructions:
Download one from this link. Before running the Installer.exe, please change the config.ini as instructed. Out of the box the setting is:
[WebToGo-Project]
InstallSilent=1
Better:
InstallSilent=0
Now run the Installer.exe and install the app. Run it, and:
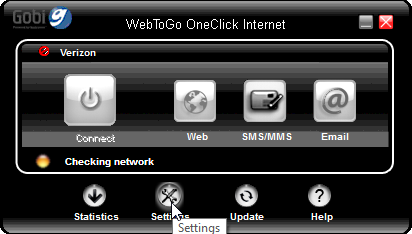
Click settings at the bottom, then:
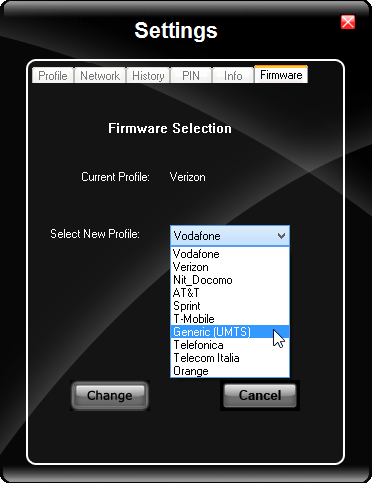
Hey presto! A drop-list of all firmwares available. Just select the one you want. My choice is obviously UMTS, which translates into the regular 2G/3G. What's even better is that this application has a SMS-utility in it. You can actually send and receive text messages with it. Something that is completely missing from Windows 8.1.
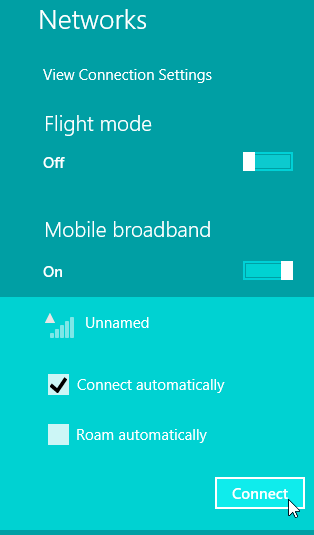
As a result, the Networks (click on the Internet connection on system tray to open the display to the right side of the screen) will look like this:

Nice! Exactly what I was looking for.
The bad thing about this is, that Thinkpad L512 has a really bad antenna. Any USB-stick will have a better one. The obvious good thing is, that Windows 8.1 gains one piece of much required functionality Lenovo chose to drop.
Lenovo Energy Management: Windows 8 shutting down sporadically
Tuesday, June 17. 2014
Arch Linux failing to start network interface
Monday, June 16. 2014
One of my boxes is running an Arch Linux. Out of the box it is really a slim one. The install runs only a blink and as a result the operating system won't have anything that is not absolutely necessary to boot the thing for the first time. Given any of the other distros who require gigabytes and gigabytes of storage for crap you won't ever need this is a refreshing change. Every Arch Linux user needs to "build their own excitement" (originally about Gentoo from obsoleted http://www.usenix.org.uk/pictures/despair-linux/gentoo.jpg).
Recently they maintainers have been fiddling around too much with network interface naming conventions. When I installed it was eth0, then it changed to ens3, and guess what happened when I last updated! Yuupp! Back to eth0, but with a twist. Now the eth0 won't come up on boot. Crap!
The Arch Linux discussion forum's section Networking, Server, and Protection has a discussion with topic [SOLVED] Update broke netctl (I guess?). It discusses the problem with a sys-subsystem-net-devices-ens3.device. However, in my box none of the repair instructions were accurate.
Later I realized that my dmesg has following lines in it:
systemd[1]: Expecting device sys-subsystem-net-devices-eth0.device...
systemd[1]: Expecting device sys-subsystem-net-devices-ens3.device...
Ok. On bootup it waits for two, as in not one, network interfaces to become alive. The problem is that my box only has one. A check for the ghost-interface:
systemctl status sys-subsystem-net-devices-ens3.device
* sys-subsystem-net-devices-ens3.device
Loaded: loaded
Active: inactive (dead)
Yields pretty much what I know. It is inactive and dead. A manual fix would be to start the DHCP-client manually with a:
systemctl start dhcpcd@eth0.service
... after which the network starts functioning again, but which does not fix the problem. On bootup the interface won't work!
What I did to fix this was to disable dhcpcd for both interfaces:
systemctl disable dhcpcd@ens3.service
systemctl disable dhcpcd@eth0.service
And enabled it to the proper one:
systemctl enable dhcpcd@eth0.service
This does seem to help, but on bootup it still complains "Dependency failed for dhcpcd on ens3". I don't know exactly where the old interface keeps popping up.
In the end, this does work, but it simply takes a bit longer to boot than it used to. Any suggestions to improve booting are welcome.
Windows 8.1 update failing to install
Sunday, June 15. 2014
I've been really busy with a new job and haven't had much time to blog. Now things are settling down a bit, so here goes ...
Windows 8.1 is my favorite subject. I'm an user and it does have a lot of issues. This time I'm discussing my attempts to install The Windows 8.1 Update. Ok. Is that the stupidest name in the whole world, or can somebody come up with something that could be more confusing, lame and non-descriptive at the same time. Don't answer, somebody at Microsoft eventually will.
The thing with this "update" is that you need to have it installed, or else <insert a threat here>. One of the ideas of this weirdly named update (aka. "update") is that it is kinda service pack, but it is not. It seems to pack all the updates in an "update". Nice and warm thought. The problem is, that it won't install. No matter what I do. Really. It WON'T INSTALL!
What I initially got is a "Windows Update error 0x80073712". The fix has been discussied in The Windows Club article Fix: Windows Update error 0x800F081F in Windows 8.1 and a help article your Windows 8.1 will give if clicking "more information" at the Windows Update failure dialog. It will say: "If you receive Windows Update error 0x80073712 or 80073712, it means that a file needed by Windows Update is damaged or missing." Everybody pretty much instructs you to run following as an admin:
DISM.exe /Online /Cleanup-image /Scanhealth
Deployment Image Servicing and Management tool
Version: 6.3.9600.16384
Image Version: 6.3.9600.16384
[==========================100.0%==========================]
The component store is repairable.
The operation completed successfully.
Notice how this scanner found a problem and says "is repairable". If there is nothing to do the message would be "No component store corruption detected". The actual fix run goes as follows:
DISM.exe /Online /Cleanup-image /Restorehealth
Deployment Image Servicing and Management tool
Version: 6.3.9600.16384
Image Version: 6.3.9600.16384
[==========================100.0%==========================]
The restore operation completed successfully. The component store corruption was repaired.
The operation completed successfully.
I did that. 7 times. Rebooted the computer a couple of times between runs. No avail.
The second thing to do is to get a Windows Update troubleshooter. It will chew your computer a while and spit out something like this: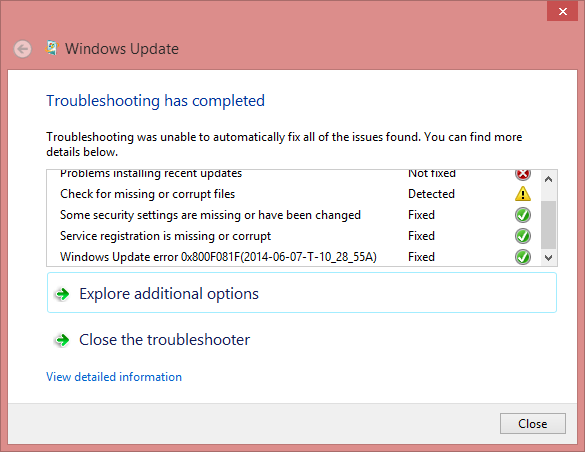
It basically does the same thing than the previous commands, but only has a nice GUI. No avail.
Then I thought that I'll download the update manually, it is available as KB2919355. There is a specific track to be followed when installing this, for example there are prerequisite updates that must exist on the machine for the "update" update to install. I did all that, but failed on the first prerequisite install. I tried a couple of times, but eventually gave up. No avail.
Since I had been attempting the install since April 2014 Microsoft updates came out. I was quite demotivated on this particular subject. My luck turned when June 2014 updates came out. There weren't many of those available, since the update I need called "update" wasn't updating. The total number of available updates on my computer was 3. My attempt of installing all of them at the same batch wasn't successful. Yet another 0x800blah error. Then I tried installing them individually. Same story. My luck turned when I did them in pairs. I got one of them to install! Amazing! Something wonderful happened and after a reboot the "update" was installed.
A reboot later my updated Windows 8.1 could see 22 new updates available. It worked!
Morale of the story:
Sometimes, even the stubborn idiot finds the kernel of corn. To this day I cannot comprehend what exactly happened and my Windows refused to do the good thing.
My message to Microsoft's Windows division is: Aow come on! Test these things once in a while. I'm pretty darn sure you know what the problem was, why not release a proper information how to get the darn update installed.
Transferring Windows 7 OEM license to a new hard drive
Friday, May 30. 2014
This is a follow-up post on my previous post about Replacing Compaq 615 hard drive with a SSD.
It is obvious, that when you remove the old hard drive from your PC and replace it with a new one, all your stuff won't be on the new drive. "All your stuff" includes Windows operating system, your user profile information, settings, background picture of your desktop, all your precious photos, ... the list goes on. So to succesfully replace the hard drive, some preliminary steps are needed. Even in the best case, where you're prepared to lose all of your files and information, the only thing that you need to transfer is your Windows 7 license. In Microsoft lingo it is called The Activation. This literally means, that your Windows will emulate E.T. and "call home" to verify, that you are allowed to run the installation.
In this particular case following circumstances exist:
- The laptop in question is manufactured by HP/Compaq
- HP/Compaq is a Microsoft OEM partner and they get their Windows 7 licenses with special pricing
- The hardware must has a suitable identification for the OEM partner in its BIOS called SLIC
- Actual Windows 7 license (activation) will be stored on the hard drive, the OEM product key of this installation is not known
- It is impossible to transfer the activation from old hard drive to the new one. It is possible to re-activate on the new drive when the existing OEM product key has been extracted from the old Windows 7 installation.
- There is nothing illegal in this procedure. You bought the hardware, you own the hardware. With hardware you paid for the Windows 7 license. This is NOT software piracy of any kind.
Abandoned options
There are three good possibilities of transferring an existing Windows installation to the new drive. I chose not to use either of those.
It is possible to create a recovery disc from existing installation. This has been covered in articles How do I create recovery discs on a Compaq 615 and Creating Recovery Discs or Saving a Recovery Image to a USB Flash Drive (Windows 7). There was a glitch, though. The HP Backup & Recovery manager was not installed to this Compaq laptop. I found an article Download hp backup & recovery manager which points to softpaq sp45602.exe containing the installer.
Another way would be to use the Windows 7 built-in backup. There is an option to create the system recovery image. Apparently HP/Compaq chooses to go with this on consumer models.
Other possibilities would include Clonezilla, Acronis True Image, or similar to transfer the entire drive with all the partitions.
The reason why I abandoned all of those was that I definitely wanted a fresh start without any old payload. The HP Backup & Recovery would provide the cleanest start, but still there are a number of weird software being installed, which nobody actually needs or wants. Another thing is that Windows 7 fresh install on SSD takes care of setting the TRIM-flag to the partition and aligns the partitions properly on 4096 byte boundaries. Both of those settings differ when installing to a hard drive. These are pretty much the only differences when installing to SSD instead of HD, but I definitely wanted to get all of my performance settings right from the beginning.
Prerequisites for license transfer
When talking about OEM Windows 7 licenses, following license types exist OEM Channel SLP, NONSLP and COA License Product Keys. The difference of those is explained in detail in this article. To put it briefly, in every OEM machine there must be a sticker somewhere. The sticker has the Certificate of Authentication (COA) key. This OEM COA key can be used to activate a Windows 7 installation only via phone. It is a possibility, but not my first choice as there are other options available.
Every OEM Windows 7 also has an OEM System Locked Pre-installation key. The key is not available anywhere. It is hidden intentionally, for the reason that nobody would ever try anything I'm about to describe in this post. To dig out the SLP-key, you will need a special piece of software. My choice is The Magical Jelly Bean Keyfinder. There is a free edition available for download and it just magically tells you your Windows installation key. The smart thing to do is to use the export-option to an USB stick. You can copy/paste your license key from a file later when it is needed.
If you are interested in your settings and data, backup your user profile(s) with Windows Easy Transfer (migwiz.exe). I chose to save the profile data onto an USB hard drive to be restored later.
You must have OEM certificates for this the license activation to work. Download a the certificate bundle from https://docs.google.com/open?id=0Bxj5NEo7I3z9dWx3VndfenZBWVE. Your hardware manufacturer should be in the archive, if it is not, you cannot proceed.
Optional prerequisite is SLIC ToolKit V3.2. You can download one from https://docs.google.com/open?id=0Bxj5NEo7I3z9WE1NS2dVVjc4VEE. Using this tool really helps you in the process, because you can actually see if it would work and you can verify the steps.
Warning!
If you don't know your SLP-key DO NOT remove the old hard drive.
Installing Windows 7 to the new drive
Warning!
If you don't know your SLP-key DO NOT start installing to the new drive. Put the old drive back and use a keyfinder to get your key.
Update 2nd Jan 2016: My recent findings about possibility of recovering the key with USB-dock. With suitable hardware it is possible to read the key from already removed hard drive.
Update 13th Mar 2015: Microsoft took down their Windows 7 downloads from Digital River. They are not available anymore!
All the Windows 7 SP1 installation images are generally available for download. See Official Windows 7 SP1 ISO from Digital River about details. Again: This is not software piracy! You own the license for your Windows 7, you are entitled to own the installation media for it.
Download the exact version of your installation image. Language may be different, but not all OEM licenses are allowed for both 32-bit and 64-bit installations. If you are changing x86 to x64 there will be also issues with Windows Easy Transfer, it documented that the transfer wizard works only on same arcitecture. To see if your OEM license works both on 32-bit and 64-bit you simply have to test it.
If you need the language files see Windows 7 SP1 Language Packs Direct Download Links and the utility needed to install them Vistalizator. The language packs are different for 32-bit and 64-bit installations, so choose carefully. Windows 7 Ultimate can change languages from control panel, no special tweaks are needed for it.
During installation, choose not to enter a license key. You will end up having a non-activated Windows installation. The technical term is that your activation is on a "grace period". This is what we want to do. Activate later.
Re-activating the license on the new drive
Third warning: You will need your SLP-key for the re-activation to work.
In your Computer properties, there is an option to "Change Product Key". None of your OEM-keys will work there, no matter how much you try. Any activation attempts will yield something like this:
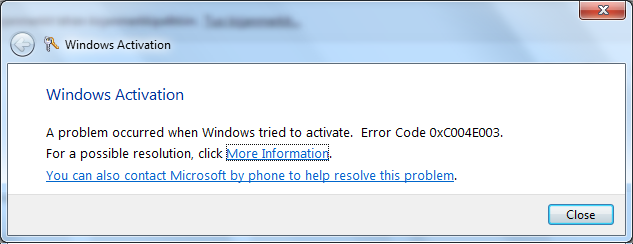
Activation Error code: 0XC004E003 (Product key already in use). There is a lengthy discussion of Clean OEM Windows 7 install returns 0xc004e003 @ Microsoft.
What you need to do is follow instructions from activating windows 7 OEM way. Open a Command Prompt (cmd.exe) and run it as Administrator.
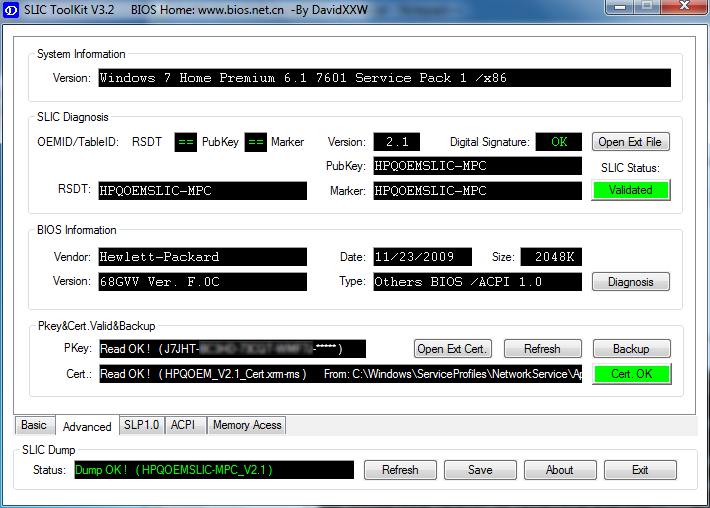
First we confirm that the BIOS has required information in it. It definitely should as the machine had a working Windows 7 in it, but still ... run the SLIC tool to confirm:
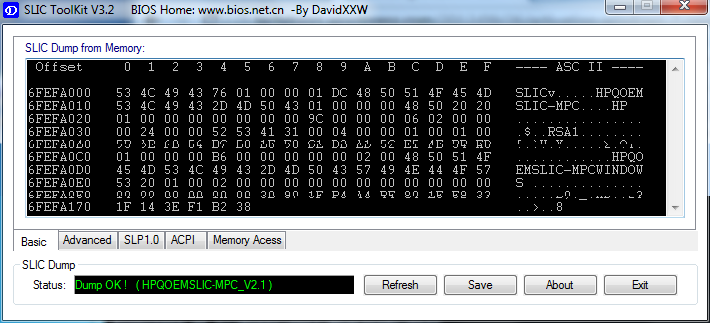
It should say "Dump OK!". On the Advanced-tab you can confirm, that there are issues with the activation:
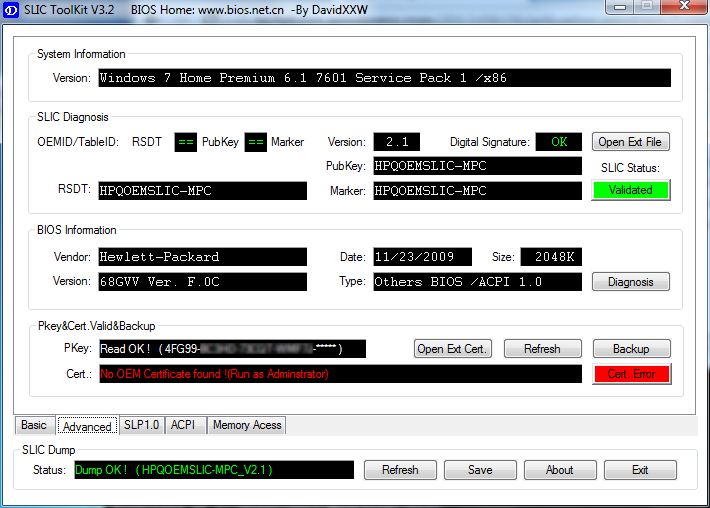
The SLIC status is on green and is valid, but private key and certificate have issues and display a red cert. error.
To fix this, my sequence differs a bit from the article. The first thing to do is to set your SLP-key, say something like this into your command prompt (no, that is not really my SLP-key):
slmgr.vbs -ipk J7JHT-BC3HD-73CQT-WMFJ-XXXXX
It should respond after a delay:

Next install your manufacaturer certificate, this will take a while:
slmgr.vbs -ilc HP-COMPAQ.xrm-ms
It should respond after a lengthy delay with something like this:
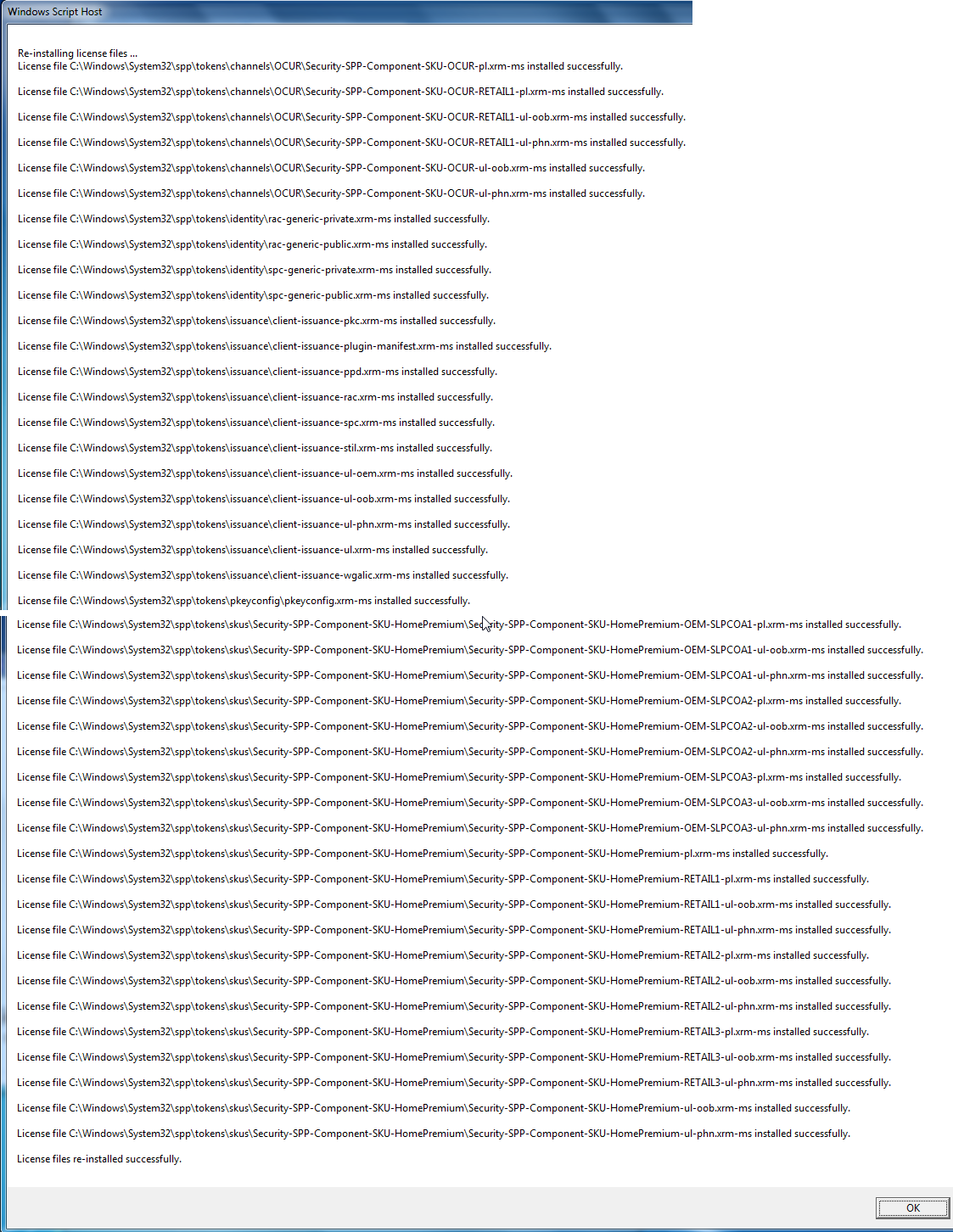
The last thing to do is to rebuild the certificate store, to start using all these changes:
slmgr.vbs -rilc
That should respond with a simple "Ok". Now you can confirm your activation status with a:
slmgr.vbs -dli
The response should be something like:
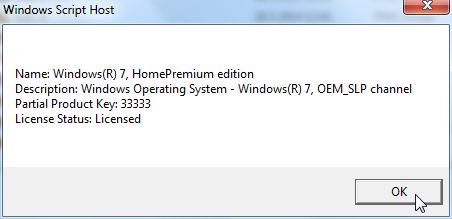
If you failed in this process, the response will look more like:
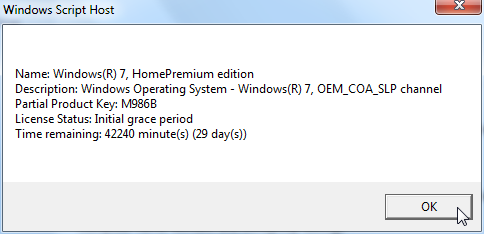
Upon success, the SLIC tool will also display the status as:
Slmgr.vbs is volume activation tool installed into all Windowses. See more details about it from Slmgr.vbs Options for Volume Activation @ Technet.
The successful activation can be confirmed also from Computer properties. At no part of this activation any network traffic to Microsoft or any other party is required.
Both Microsoft and your PC's manufacturer would like for you not to know anything about this. Both of their businesses rely on the fact, that hardware vendors and their partners will do all the maintenance for your PC while making money at it. Since hacking is about learning how computer stuff works, this is a prime example of hacking. With this information you can hack your own laptop.
Any comments are welcome!
Running AT-commands on your B593
Thursday, May 29. 2014
This is something I've wanted to do for a long time. Ever since I got my B593. Jevgenij has been hacking his B593 and dropped me a comment that he found command /bin/lteat from his box. Obviously I had to SSH into mine to confirm this:
# ssh admin@192.168.1.1 /bin/sh
admin@192.168.1.1's password:
-------------------------------
-----Welcome to ATP Cli------
-------------------------------
ATP>shell
BusyBox vv1.9.1 (2013-07-25 14:10:15 CST) built-in shell (ash)
Enter 'help' for a list of built-in commands.
# ls -l /bin/lteat
-rwxrwxrwx 1 0 0 34604 /bin/lteat
... and oh yes! Such a command is there. It is an interactive AT-command shell!
Warning!
Running these AT-commands will mess up with your box. The modem does not like to be messed up and my box didn't connect to internet after doing this. There is a simple fix to just reboot the router.
Let's explore some possibilities.
Manufacturer information
Running the AT-command shell:
# lteat
AT>
This is something that worked already in the 80s modems. The classic modem information:
AT>ati
Manufacturer: Huawei Technologies Co., Ltd.
Model: EM920
Revision: 11.433.61.00.07
IMEI: 868031008680310
+GCAP: +CGSM,+DS,+ES
OK
The 15-digit IMEI is broken into two pieces. First 8 numbers are the Type Allocation Code (or TAC). The second part is the 7 number unique id of my unit. That's why I'm not revealing it here.
If we punch the TAC into a http://www.nobbi.com/tacquery.php it will yield a result of:
86803100
Manufacturer = Huawei
Model = B593
Hints = LTE/UMTS Router
Which is not very surprising. That is something we already know.
Telco information
Let's see what we can get from my telco. I found a nice reference List of AT commands to be very helpful. Running command:
AT>AT+COPS=3,2
AT+COPS=3,2
OK
AT>AT+COPS?
AT+COPS?
+COPS: 0,2,"24405",2
OK
The 24405 is my PLMN code (note: this can be found from web GUI's diagnostics wireless status also). According to article Mobile country code, it breaks down to two parts:
Mobile Country Code = MCC = 244
Mobile Network Code = MNC = 05
According to the table:
MCC = 244 = Finland
MNC = 05 = Elisa
Again, something that I already know.
Location information
To dig a bit deeper ... Every cell tower has unique code. I found information about that from a discussion forum with topic Huawei USB LTE Modem, E3276 K5150 E398 (Modems). The forum says that:
AT+CREG?
+CREG: 2,1, YYYY, XXXXX, 2
OK
Y = LAC
X = Cell ID
Added: Note that both are in hex so need to convert it
Let's try that one out:
AT>AT+CREG=2
AT+CREG=2
OK
AT>AT+CREG?
AT+CREG?
+CREG: 2,1, 620C, 123ABC, 2
OK
Now we have:
LAC = 620C (hex) = 25100 (decimal)
Cell ID = 123ABC (hex) = 1194684 (decimal)
Again, I'm not going to reveal my exact location here! The cell-ID published here is something I made up.
I tested all the gathered information of:
MCC = 244
MNC = 05
LAC = 25100
cell-ID = 1194684
in OpenCellID's search engine, but they don't seem to have my coordinates in it. Maybe I should add them. Your's may very well be there.
According to Wikipedia article, there are a number of databases for cell-IDs, but most of them are commercial and I don't have a license to use them. In general they simply have exact GPS-coordinates of cell towers and they can be used to get a rough estimate of your location.
Signal quality
The last one I did was to get exact signal quality. A B593 has 5 bars in it, which is accurate enough for most users. The hardware has the quality info in much more detailed level. The AT-command list says:
Signal quality
Command: AT+CSQ
Response: +CSQ: <rssi>,<ber>
Let's try that out:
Query for the ranges:
AT>AT+CSQ=?
AT+CSQ=?
+CSQ: (0-31,99),(0-7,99)
OKQuery for the signal quality:
AT>AT+CSQ
AT+CSQ
+CREG: 1, 620C, 123AC1, 2
AT+CSQ
+CSQ: 23,99
OK
Whoa! It also returned a LAC and another cell-ID. The cell-ID is pretty close to the original one, but not exactly the same. Anyway, the Received signal strength indication (RSSI) is 23 and Bit Error Rate (BER) is 99.
By Googling I found out following information about RSSI:
RSSI (dBm) = RSRP + 10*log10(RB) + | RSRQ | + other noice, temperature noice etc.
You may also see the RSSI vs RSRP: A Brief LTE Signal Strength Primer for details about the signal math.
To put all the logarithms and four-letter-acronyms into layman terms. This table was published in the discussion forum in Finnish by user with nickname timtomi. Signal levels are from poor to excellent:
| 0 | <-113 dBm | poor, signal breaks up and all kinds of nasty |
| 1 | -111 dBm | poor, signal breaks up and all kinds of nasty |
| 2 | -109 dBm | works, but signal fluctuates, especially upload |
| 3 | -107 dBm | works, but signal fluctuates, especially upload |
| 4 | -105 dBm | works, but signal fluctuates, especially upload |
| 5 | -103 dBm | works, but signal fluctuates, especially upload |
| 6 | -101 dBm | works, but signal fluctuates, especially upload |
| 7 | -99 dBm | still better than ADSL |
| 8 | -97 dBm | still better than ADSL |
| 9 | -95 dBm | still better than ADSL |
| 10 | -93 dBm | still better than ADSL |
| 11 | -91 dBm | still better than ADSL |
| 12 | -89 dBm | full download, good upload |
| 13 | -87 dBm | full download, good upload |
| 14 | -85 dBm | full download, good upload |
| 15 | -83 dBm | full download, good upload |
| 16 | -81 dBm | full download, good upload |
| 17 | -79 dBm | excellent! good signal and ping |
| 18 | -77 dBm | excellent! good signal and ping |
| 19 | -75 dBm | excellent! good signal and ping |
| 20 | -73 dBm | excellent! good signal and ping |
| 21 | -71 dBm | excellent! good signal and ping |
| 22 | -69 dBm | excellent! good signal and ping |
| 23 | -67 dBm | excellent! good signal and ping |
| 24 | -65 dBm | excellent! good signal and ping |
| 25 | -63 dBm | excellent! good signal and ping |
| 26 | -61 dBm | excellent! good signal and ping |
| 27 | -59 dBm | you're right next to the cell tower! |
| 28 | -57 dBm | you're right next to the cell tower! |
| 29 | -55 dBm | you're right next to the cell tower! |
| 30 | -53 dBm | you're right next to the cell tower! |
| 31 | > -51 dBm | you're right next to the cell tower! |
| 99 | |
not known or not detectable |
The BER is typically 99 which means that none could be measured. In general there shouldn't be any errors in the transmission, so 99 is likely what you'll get also.
Replacing Compaq 615 hard drive with a SSD
Wednesday, May 28. 2014
This is a HOWTO instruction for replacing a spinning platter hard drive with a modern faster solid-state drive. Since Compaq 615 has Windows 7 Home Premium OEM installed, I'll blog about the Windows Activation in more detail on my next post.
This kind of Compaq laptop is quite generic PC. Majority of this information applies to almost any laptops I've disassembled. It's about the location of the drive, location and number of screws, but the information in general covers the operation of replacing a drive with another one.
I started this project with checking for Manuals for Compaq 615 Notebook PC @ HP. The good stuff is at PDF-document with title Compaq 615 Notebook PC and Compaq 610 Notebook PC - Maintenance and Service Guide.
It will contain all the information a service technician would need to successfully operate on this kind of hardware. On page 4-8 it has the hard drive replacement procedure documented.
Anyway, this is something I've done a lot. I briefly checked out the location of the drive and the screws that needed un-screwing. Here is a pic from the flipside of the laptop:

Those two screws hold a HDD-cover in place. The screws even have a HDD-symbol next to them. Un-screw both of them with a small Phillips head screwdriver:
Remove the HDD-cover by pulling up from the side you removed the screws from. The drive is visible:
The drive is held in place by a single Phillips head screw. Remove that too. Pull up from the drive screw bracket and the drive will slide left and reveal a standard S-ATA -connector:
Now you have the drive completely detached from the laptop. The actual hard drive is connected to a metal cradle with 4 Phillips head screws. Un-screw them:

As you can see, the screws are really small. The screws are quite tight, see the blue substance in the screws. It is threadlocker and its purpose is to make sure a screw is tightly attached. If you don't have the proper sized screwdriver, you will destroy the notches of these screws making removal really difficult. This is the only part of disassembly, where I needed to apply some force just to make sure that the screwdriver wouldn't slip.
The next step is to attach the new SSD-drive to the cradle:
Think really carefully which way the drive needs to be attached to the cradle. There are four possible options, but only one of them will yield success. You will see quite soon the position the cradle needs to be in the laptop. The hard part is to figure out which way the drive needs to be to succesfully connect to the S-ATA -connector of the laptop.
When the hard part is done, all you need to do is slide the cradle back to S-ATA connector and secure the screw holding the cradle at place. Then put the HDD-cover back and secure the two screws for the cover.
All this will take around 10 minutes on experienced hands. If this is your first laptop maintenance work, reserve a hour. Nothing here requires much force to be applied. If you are applying much force, you're doing something wrong.
Good luck on your project!
Telia Sweden SP102 firmware for u-12
Tuesday, May 27. 2014
Jevgenij dropped me a comment about new firmware. It is from Telia Sweden and you can get it from here http://www.telia.se/privat/support/mobiltbredband/uppdaterausbmodemorouter#huaweib593formac=&tabMenu_0=huaweib593formac The direct download link is https://www.telia.se/dms/mgnl-ext-dms/www-telia-se-ui/installation-files/se_telia_r-m-h-s.tar/se_telia_r-m-h-s.tar.bz2 The firmware seems to have nice features, SMS and even to force for 2G-operation. He highly recommends this one. This looks very promising, perhaps I'll try this myself.
I upgraded my B593 with this one and can confirm that it works well. GUI-languages are: Svenska, Suomi, Pусский, Norsk, Dansk, Eesti, Lietuviu and Latviešu. No setup wizard. Has external antenna support. No VoIP. No DDNS. Mode selector has 5 options: auto, auto 3G/4g, 2G only, 3G only and 4G only. SMS in/out. No DLNA. So it is little bit light on features, but is fully exploitable and SP102!
The file will contain a SP102 for u-12. Altough The Exploit does not work, it seems to have a nice bug in it. When you're FTPing into it, it will open also SSH-port! Whaat!
Warning:
SSH passwords are reset to something the telco set. However, USB/FTP-hack will work and you can get the /var/sshusers.cfg and look at the plaintext password from there.
Windows 8 desktop icon fail [Fixed]
Thursday, May 22. 2014
Windows 8 (or 8.1) is one of the not-so-popular operating systems. Even Microsoft employees admit Windows 8 is 'the new Vista'. Ok, they failed on that. Perhaps Windows 9 will be better.
Now that we have that out, there are a number of weird things in that OS. The one bugging me most is the fact that the full screen app icons that appear when you move the cursor to the top-left corner of your desktop are failing to display. This happens to me very often. It seems to have something to do with sleep/hibernate on my Win8 laptop. It should look like this: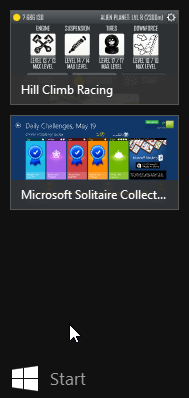
But it looks like this instead:
Not cool.
There are some shadows from the icons, but nothing usable or nothing that I could use to identify which icon is for which app.
I don't know what's the problem, but I found a fix. The culprit is your classic explorer.exe. The fix is simple. Zap your Windows Explorer with a magic kill process -wand and create a new better one. The new explorer won't know anything about already running full-screen apps, but it will sure learn if you manage to get into one.
Here is the fix. First start the Task Manager. Since the idea is to kill explorer.exe, you'll need a tool to eradicate the old one and make sure you can start a new one. The sequence starts from Task Manager's Details tab-sheet: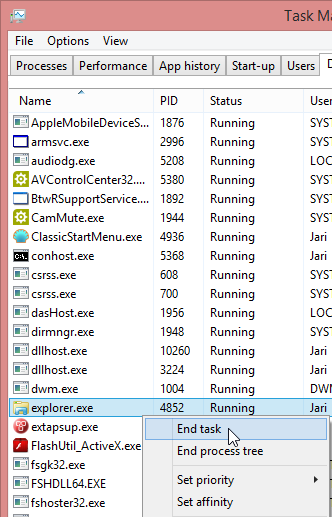
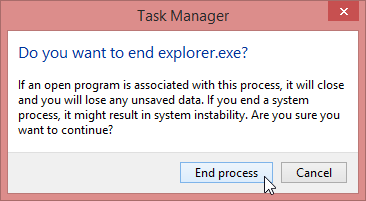

After that your explorer will be back and your icons will be back after you visit all of your apps.
Extracting /var/curcfg.xml from NVRAM [Solved!]
Wednesday, May 21. 2014
John do, a reader of this blog made a serious break-trough! Via SSH on B593 prompt, he found the flashtest-command. Before this I had no knowledge about such command, but see what I can do with this new information:
# flashtest
Usage: flashtest {info|read|write|erase|export|load} {addr} {len} [data]
Format:
flashtest help
flashtest info
flashtest read addr len
flashtest write addr len {data}
flashtest erase addr len
flashtest export addr len
Well ... the info sound interesting. Let's see:
# flashtest info
flash block size : 0x40000 (256k Bytes)
flash block num : 0x40 (64 Blocks)
flash total size : 0x1000000 (16M Bytes)
flash partation info :
---------------------------------------------------------------
Name Address Usage
---------------------------------------------------------------
Boot 0x0---0x40000 Bootloader
Image 0x40000---0xA40000 Main image
Image 0xA40000---0xE00000 Subject image
Curcfg 0xE00000---0xE40000 Curcent config
Faccfg 0xE40000---0xE80000 Factury config
Tmpcfg 0xE80000---0xF00000 Temp config
Fixcfg 0xF00000---0xF40000 Fixed config
Logcfg 0xF40000---0xF80000 Log config
TR069 0xF80000---0xFC0000 TR069 cert
Nvram 0xFC0000---0xFFFFFF Nvram
Current config! Really!? (Mis-typed as Curcent config). The run-time -only /var/curcfg.xml's real storage has eluded me this far. Let's explore that further:
# flashtest export 0xE00000 65536
Read data: addr = 0xe00000, len = 0x10000 ...
Begin write to file
Export done
What did it do? Where it wrote to? Some poking around reveals:
# cd /tmp/
# ls -l
---------- 1 0 0 65536 flashinfo.bin
Oh yes! The next thing is to get my hands on to the file. In the B593 firmware's Busybox there is only a limited set of tools.
Let's use the USB/FTP-hack for transferring the file. The idea is to plug an USB-stick into B593. Any FAT32-formatted stick will do, it is totally irrelevant if there are files or not. Early firmwares are known to have a flaw in them. You can mount the entire filesystem into FTP-server and transfer file to/from the box. Setup goes like this:![]()
Make sure you have the FTP-server running, add a user to the new mount and set the directory as ../.. It is really important to do that! That effectively breaks out of /mnt/usb2_1 into /. See this pic:![]()
I added user with name test. Now let's see if the FTP-connection works from an external machine:
# ftp 192.168.1.1
Connected to 192.168.1.1 (192.168.1.1).
220 bftpd %v at 192.168.1.1 ready.
Name (192.168.1.1:user): test
331 Password please.
Password:
230 User logged in.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> cd /tmp
250 OK
ftp> dir
227 Entering Passive Mode (192,168,1,1,166,124)
150 BINARY data connection established.
---------- 1 0 0 65536 May 21 19:26 flashinfo.bin
226 Directory list has been submitted.
ftp>
Oh yes! The extracted NVRAM-binary is there. Let's download it:
ftp> get flashinfo.bin
local: flashinfo.bin remote: flashinfo.bin
227 Entering Passive Mode (192,168,1,1,144,190)
150 BINARY data connection established.
226 File transmission successful.
65536 bytes received in 0.06 secs (1092.41 Kbytes/sec)
A brief analysis of the file reveals:
# hexdump -C flashinfo.bin | head -3
00000000 3e 00 64 fe 3c 3f 78 6d 6c 20 76 65 72 73 69 6f |>.d.<?xml versio|
00000010 6e 3d 22 31 2e 30 22 20 3f 3e 0a 3c 49 6e 74 65 |n="1.0" ?>.<Inte|
00000020 72 6e 65 74 47 61 74 65 77 61 79 44 65 76 69 63 |rnetGatewayDevic|# hexdump -C flashinfo.bin | tail -5
000064f0 65 77 61 79 44 65 76 69 63 65 43 6f 6e 66 69 67 |ewayDeviceConfig|
00006500 3e 0a 00 ff ff ff ff ff ff ff ff ff ff ff ff ff |>...............|
00006510 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00010000
The first 4 bytes of 3e 00 64 fe are bit of a mystery. I don't know what the 3e 00 is for, but the 64 fe is obvious! It is the length of the XML-file following the header bytes. I can confirm that the entire /var/curcfg.xml is there. Unchanged. Intact!
My next move is to try altering the curcfg.xml and write it back. There is a chance of locking myself out of my own B593, so ... I need to be really careful with this. If everything works as I expect, my next move is to write tools for allowing people to access their devices as they want to.
I'd like to extend my gratitude to Mr. John do. This really is ground-breaking stuff allowing us to new lengths with Huawei B593 hacking. Thank you, sir!


{kind=link}