Where in my keyboard is the € (euro) -character?
Thursday, July 4. 2013
I don't know who stole my €-char. It is supposed to be on AltGr-e, but my keyboard doesn't do it. There is a discussion about the same problem. On the thread on French keyboard layout the problem is not solved.
On my Finnish keyboard layout even Windows On-Screen Keyboard -application displays AltGr-e as the soure, but to my great amazement adds a 2nd source for the €-char, AltGr-5. WTF?! It works! See pic below:
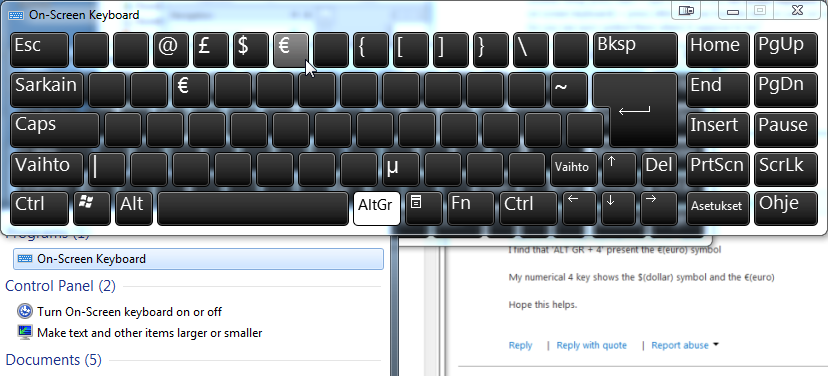
Hope this helps somebody. Unfortunately I could not determine who stole it/where my original euro-key went.
Converting classic init.d startup script into new systemd
Wednesday, July 3. 2013
Windows Azure web sites in West Europe data center
Tuesday, July 2. 2013
Well ... you cannot create one. They're just saying that there are "capacity issues" and due to that "West Europe was turned off for new subscriptions a short while back".
Is the old M$ is back? They very conveniently forget to tell you that when you're setting up your storage and servers, you cannot have a web site on top of them. Nice.  Wouldn't it be great to know that during setup-phase?
Wouldn't it be great to know that during setup-phase?
They must be really doing well in Microsoft to treat users that badly.
I'm sure that popularity of their service wasn't a surprise to them
either. Yet another nice example of bad communication from a big corporation.
Doing secure dynamic DNS updates with BIND
Monday, July 1. 2013
Solving Microsoft Secure Download Manager issues
Friday, June 28. 2013
Windows Azure trial purchase on IE10
Wednesday, June 26. 2013
This was pretty funny one. I was about to start a Windows Azure 30-day trial on Windows 8 with Internet Explorer 10, but it failed on payment options.

I waited for 10 minutes, but no avail. It was pretty obvious that a failure was imminent after 30 seconds of nothingness. The payment just hangs forever without doing anything. They simply never tested it on IE10. On any other browser I tried it works just ok.
udev wrangling
Tuesday, June 25. 2013
Figuring out Fedora 19 sysctl.conf
Monday, June 24. 2013
Losing OpenLDAP DB for a BDB0060 PANIC
Tuesday, June 18. 2013
My Fedora 19 got an update for KVM. It was a no biggie, nothing really happened at the time.
Then one of the virtual guests got a new kernel (RHSA-2013:0911-1). I rebooted the guest and BANG! My KVM hung the entires machine. I have the Magic SysRq enabled, but nothing. The box was completely hung.
The "funny" part happened after I forced a reboot from the button. The box wouldn't boot! My LDAP was corrupted. All I got was a "BDB0060 PANIC: fatal region error detected; run recovery" -message.
There is the /usr/bin/db_recover -tool, but it just said FUBAR. I didn't get the actual phrase, but surely you'll get the meaning. Then, what next? I was lucky enough to have a 3 week old slapcat of my entire LDAP. That was plenty of luck for me. But the morale of the story is, that I'll need to start dumping the LDAP or change the back-end format into something more recoverable.
Breaking php LDAP admin with PHP 5.5
Monday, June 17. 2013
Linux-distros are having a race for the most popular one. Part of the setup is to have the latest Linux kernel, and any other part of the software library a distro has. This effect yields into a "nice" effect where running the bleeding edge distros (Fedora, ArchLinux, Debian sid, etc.) every now and then something breaks.
The latest race is with PHP programming language which is nearing the 5.5.0 release. It has an RC3 version already out. Now the problem is that distro-guys start using the latest stuff, but PHP has incompatible changes in it. Plenty of things made with PHP 5.4 or 5.3 or ... won't run.
One of them is phpLDAPadmin. For some incomprehensible reason they are using stuff, which has been flagged as obsoleted years ago. So, it won't work. Luckily somebody at Debian made a fix. That makes my system's LDAP-admin working again. Hopefully somebody does the same with with all of the PEAR packages. 
This is what you get when running alpha version of Fedora 19.

